
- Классификация баз данных
- Вступление
- Классификация баз данных пи типу хранимых данных
- Классификация баз данных по обращению к ним
- Классификация БД по способу организации данных
- Модели БД
- Реляционная база данных
- Другие статьи раздела: База данных
- Что такое база данных — понятие база данных в информатике
- Функции СУБД обеспечивающие управление базой данных
- PhpMyAdmin на локальном сервере
- Классификация баз данных. 1. По характеру хранимой информации БД делятся на:
- Обработка и хранение информации
- Хранение информации. Базы и хранилища данных
Классификация баз данных
Вступление
Напомню, что база данных это большой объем данных, которая в ней хранится, может обрабатываться, дополняться, удаляться, причем в удобной для пользователя форме. Также нужно четко понимать, что в БД хранится не всякая информация, а информация, которую можно организовать по тем или иным свойствам. Например, большое количество различных фотографий или документов это не данные, а информация. Но мы можем организовать фотографии, например по сути: фото людей, фото животных, фото городов и т.д. или организовать их по размеру: большие, средние, маленькие. Организованная, таким образом информация превращается в данные и пригодна для автоматической обработки с использованием баз данных. Переходим к классификации баз данных.

Классификация баз данных пи типу хранимых данных
Базы данных, объединяющие документы, сгруппированные (организованные) по разным свойствам, классифицируются, как документальные БД.
Под документом понимается текстовой документ или ссылка на него. Документальные БД разделили по типу документов на полнотекстовые, реферативные (рефераты) и библиографические. Это деление не так важно, как важен способ хранения информации. Здесь следующее разделение: базы данных хранящие исходный документ или хранящие ссылки, по которым можно обратиться к исходному документу.
Фактографические БД объединяют данные по факту совершения события (дата выпуска товара, год рождения сотрудника).
Лексикографические БД объединяют словари, классификаторы, и т.л. документы.
Характерным примером, документальных баз данных могут послужить базы объединяющие документы по нормативным «формам». Вы встречались с такими документами, например в паспортом столе или отделе кадров, заполняя «бумажку» по форме № такой то.
Классификация баз данных по обращению к ним
Базы данных индивидуального пользования классифицируют, как персональные или локальные базы данных.
Интегрированные иначе централизованные базы данный предоставляют коллективный доступ к данным. Такой доступ может быть как многопользовательский (сразу все), так и параллельный (независимый).
Распределительные базы данных аналогичны интегрированным, но могут быть физически разнесены на разные машины, и при этом логически считаться единым целым.
Перечисленные выше классификации не особо интересны пользователям. Для пользователя интересна классификация по способу организации данных и по типу используемой модели.
Классификация БД по способу организации данных
Не буду останавливаться на неструктурированных и частично структурированных базах данных. Они имеют узкое применение. Более важно понятие структурированной базы данных, в которых данные хранятся по предварительно спроектированной модели.
Модели БД
Моделями структурированной БД могут быть:
- БД иерархической модели;
- Сетевой модели;
- И самой используемой моделью БД – реляционной базой данных.
Реляционная база данных
Реляционная база данных самая используемая и самая математическая модель БД. Эта модель используется везде, где есть формализованная информация. Основа этой модели таблица, а взаимоотношения данных происходят по «доменам», «атрибутам», «кортежам» или более понятно и знакомо, по «типам данных», «столбцам» и «строкам».
В завершении замечу, что классификации БД перечисленных в статье, с уверенностью применяются для классификации СУБД.
Другие статьи раздела: База данных

Что такое база данных — понятие база данных в информатике
Содержание статьи: Что такое база данных в информатикеЧто такое СУБД и SQLСУБД MySQLСтатьи по теме “База данных” Информация основа современного общества. Объем ее огромен и растет с каждым годом. Огромный объем информации уже давно поставил задачу ее хранения и обработки. Решает эту задачу понятие база данных. Похожие статьи: Что такое целевой рынок, как его найти […]

Функции СУБД обеспечивающие управление базой данных
В этой статье вы познакомитесь с основными функциями СУБД системами управления базами данных.

PhpMyAdmin на локальном сервере
В этой статье мы рассматриваем работу с phpMyAdmin на локальном сервере, то есть в рамках настольного компьютера.
Источник
Классификация баз данных. 1. По характеру хранимой информации БД делятся на:




![]()
![]()
1. По характеру хранимой информации БД делятся на:
· Фактографические БД — это картотеки, где хранится краткая информация в строго определенном формате.
· Документальные БД — это архивы, где хранятся всевозможные документы, это могут быть не только текстовые документы, но и графика, видео и звук (мультимедиа).
2. Классификация по способу хранения данных делит БД на:
· Централизованные БД – где вся информация хранится на одном компьютере. Это может быть автономный ПК или сервер сети, к которому имеют доступ пользователи-клиенты.
· Распределенные БД — используются в локальных и глобальных компьютерных сетях. В таком случае разные части базы хранятся на разных компьютерах.
3. Третий признак классификации баз данных — по структуре организации данных:
Источник
Обработка и хранение информации
Хранение информации. Базы и хранилища данных
Предметная область какой-либо деятельности — часть реального мира, подлежащая изучению с целью организации управления процессами и объектами для получения бизнес-результата. Предметная область может быть разделена (декомпозирована) на фрагменты: например, предприятие — это дирекция, плановые отделы, бухгалтерия, цеха, отделы маркетинга, логистики и продаж, клиенты, поставщики и т. д. Каждый фрагмент предметной области характеризуется множеством объектов и процессов, использующих объекты, а также множеством пользователей, характеризуемых различными взглядами на предметную область и данными, которые описывают указанные составляющие предметной области . Эти данные отражают динамичную внешнюю и внутреннюю среды предприятия, поэтому в специальных разделах информационной системы необходимо создавать динамически обновляемые модели отражения внешнего мира с использованием единого хранилища — базы данных .
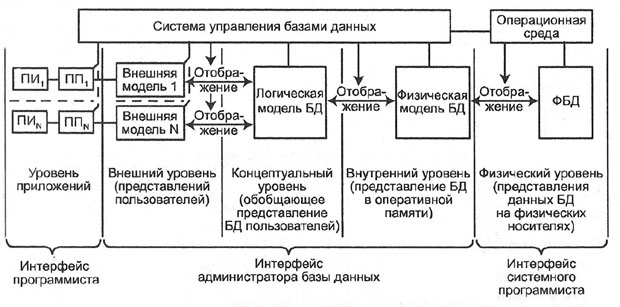
База данных, БД (Data Base) — структурированный организованный набор данных, объединенных в соответствии с некоторой выбранной моделью и описывающих характеристики какой-либо физической или виртуальной системы ( рис. 2.2).
Понятие «динамически обновляемая БД » означает, что соответствие базы данных текущему состоянию предметной области обеспечивается не периодически, а в режиме реального времени. При этом одни и те же данные могут быть по -разному представлены в соответствии с потребностями различных групп пользователей.
Система управления базами данных, СУБД (Data Base Management System) — специализированная программа или комплекс программ, предназначенные для манипулирования базой данных. Для создания информационной системы и управления ею СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор .
СУБД часто упрощенно или ошибочно называют «базой данных». Нужно различать набор данных (собственно БД ) и программное обеспечение , предназначенное для организации и ведения баз данных ( СУБД ).
Отличительной чертой баз данных следует считать то, что данные хранятся совместно с их описанием, а в прикладных программах описание данных не содержится. Независимые от программ пользователя данные обычно называются метаданными или данными о данных. В ряде современных систем метаданные , содержащие также информацию о пользователях, форматы отображения, статистику обращения к данным и др. сведения, хранятся в специальном словаре базы данных .
Организация структуры БД формируется исходя из следующих соображений:
- адекватность описываемому объекту/системе — на уровне концептуальной и логической моделей ;
- удобство использования для ведения учета и анализа данных — на уровне так называемой физической модели .
Виды концептуальных и логических моделей БД :
- картотеки;
- сетевые;
- иерархические;
- реляционные;
- дедуктивные;
- объектно-ориентированные;
- многомерные.
На уровне физической модели электронная БД представляет собой файл или набор данных в dbf-форматах приложений Excel , Access либо в специализированном формате конкретной СУБД . Также в СУБД в понятие физической модели включают специализированные виртуальные понятия, существующие в ее рамках, — » таблица «, «табличное пространство «, «сегмент», «куб», » кластер » и т. д.
В настоящее время наибольшее распространение получили реляционные базы данных . Картотеками пользовались до появления электронных баз данных. Сетевые и иерархические базы данных считаются устаревшими, объектно-ориентированные пока никак не стандартизированы и не получили широкого распространения.
Реляционная база данных — база данных , основанная на реляционной модели. Слово «реляционный» происходит от английского » relation » ( отношение ).
Теория реляционных баз данных была разработана доктором Эдгаром Коддом из компании IBM в 1970 году. В реляционных базах данных все данные представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении которых расположены данные. Запросы к таким таблицам возвращают таблицы, которые сами могут становиться предметом дальнейших запросов. Каждая база данных может включать несколько таблиц. Кратко особенности реляционной базы данных можно сформулировать следующим образом:
- данные хранятся в таблицах, состоящих из столбцов («атрибутов») и строк («записей»);
- на пересечении каждого столбца и строчки стоит в точности одно значение;
- у каждого столбца есть свое имя, которое служит его названием, и все значения в одном столбце имеют один тип;
- запросы к базе данных возвращают результат в виде таблиц, которые тоже могут выступать как объект запросов;
- строки в реляционной базе данных неупорядочены, упорядочивание производится в момент формирования ответа на запрос.
Общепринятым стандартом языка работы с реляционными базами данных в настоящее время является язык структурированных запросов ( Structured Query Language — SQL ). Это универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных . Вопреки существующим заблуждениям, SQL является информационно-логическим языком, а не языком программирования.
SQL основывается на реляционной алгебре . Язык SQL делится на три части:
- операторы определения данных;
- операторы манипуляции данными (Insert, Select, Update, Delete);
- операторы определения доступа к данным.
Основные функции системы управления базами данных :
- управление данными во внешней памяти (на различных носителях);
- управление данными в оперативной памяти;
- журналирование изменений и восстановление базы данных после сбоев;
- поддержка языков БД (язык определения данных, язык манипулирования данными, язык определения доступа к данным).
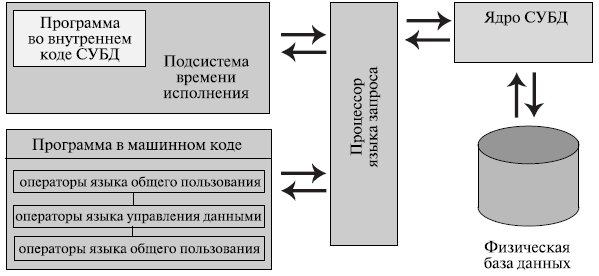
Обычно современная СУБД содержит следующие компоненты ( рис. 2.3):
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журналирование ;
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода;
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД;
- сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
По типу управляемой базы данных СУБД разделяются на иерархические, реляционные, объектно-реляционные, объектно-ориентированные, сетевые.
По архитектуре организации хранения данных:
- локальные СУБД (все части локальной СУБД размещаются на одном компьютере);
- распределенные СУБД (части СУБД могут размещаться на двух и более компьютерах).
Классификация СУБД по способу доступа к БД :
- файл-серверные ;
- клиент-серверные;
- трехзвенные;
- встраиваемые.
Файл-серверные СУБД. Архитектура » файл-сервер » не имеет сетевого разделения компонентов диалога и использует компьютер для функции отображения, что облегчает построение графического интерфейса. » Файл-сервер » только извлекает данные из файлов, так что дополнительные пользователи добавляют лишь незначительную нагрузку на центральный процессор , и каждый новый клиент добавляет вычислительную мощность сети. Минус — высокая загрузка сети. На данный момент файл-серверные СУБД считаются устаревшими. Примеры: Microsoft Access, MySQL (до версии 5.0).
Клиент-серверные СУБД. Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера. Клиент-серверные СУБД , в отличие от файл -серверных, обеспечивают разграничение доступа между пользователями и меньше загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по мере надобности его можно заменить другим. Недостаток клиент-серверных СУБД — в самом факте существования сервера (что плохо для локальных программ — в них удобнее встраиваемые СУБД ) и больших вычислительных ресурсах, потребляемых сервером. Примеры: Firebird , Interbase , MS SQL Server , Oracle , DB2 , PostgreSQL, MySQL (старше версии 5.0).
Существенным недостатком клиент-серверной архитектуры является необходимость установления прямого соединения между клиентским компьютером и базой данных. При трехзвенной архитектуре пользовательское приложение (клиент) соединяется со специально выделенным сервером приложений, и только он уже соединяется с базой данных. Кроме повышения уровня безопасности трехзвенная архитектура позволяет более гибко модернизировать приложения. Как правило, в массовой клиентской части оставляют только минимальный набор функций по доступу и отображению информации, а основную бизнес-логику реализуют в программах, запускаемых на серверах приложений . При этом модернизация обычно затрагивает только сервер приложений , а на массовых клиентских местах переустанавливать ПО не приходится.
Встраиваемая СУБД — это, как правило, «библиотека», которая позволяет унифицированным образом хранить большие объемы данных на локальной машине. Доступ к данным может происходить через SQL либо через особые функции СУБД . Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют установки сервера, поэтому востребованы в локальном ПО , которое имеет дело с большими объемами данных — например, геоинформационные системы (Geographic Informational System — GIS ). Примеры: SQLite, BerkeleyDB, один из вариантов Firebird , один из вариантов MySQL .
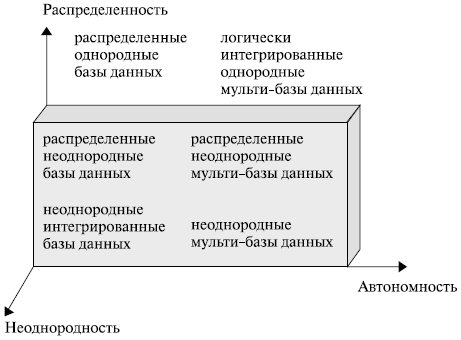
В общем случае СУБД могут быть классифицированы в системе координат «Неоднородность — Автономность -Распределенность» ( рис. 2.4).
Таким образом, распределенная обработка данных в обязательном порядке предполагает наличие банков и баз данных. Но база данных — это не просто место , куда складывают данные, ими нужно пользоваться, актуализировать, изменять форматы и связи, совершать множество других действий. Если бессистемно наполнять базу данных информацией, то через некоторое время ее невозможно будет использовать — времени на поиск нужных данных будет уходить все больше и больше, физическое пространство базы переполнится. Чтобы этого избежать, данные необходимо «очищать» и структурировать, а для эффективной работы с ними необходимы системы управления работой баз данных.
Индустрия создания баз данных и СУБД берет свое начало в 60-х годах прошлого века и к настоящему времени достаточно развита, однако понятие » хранилище данных » в современном понимании его появилось относительно недавно.
Идея хранилищ данных оказалась востребованной, так как во многих видах государственной, деловой, научной, социальной деятельности необходимы тематически объединенные и исторически очищенные совокупности данных, при этом постоянно возрастала потребность:
- в более дешевых данных;
- в точных и структурированных данных;
- в большей оперативности получения и обработки данных;
- в интегрированных данных.
К концу 1980-х годов, когда была в полной мере осознана необходимость интеграции корпоративной информации и надлежащего управления этой информацией, появились технические возможности для создания соответствующих систем, которые первоначально были названы «хранилищами информации» ( Information Warehouse — IW). И лишь в 1990-е годы, с выходом книги Уильяма (Билла) Инмона, хранилища получили свое нынешнее наименование «хранилища данных» ( Data Warehouse — DW) [Inmon W.H. Building the Data Warehouse , QED/Wiley, 1991, 312 р.].
Билл Инмон определил хранилища данных как «предметно-ориентированные, интегрированные, неизменные, поддерживающие хронологию наборы данных, организованные для целей поддержки управления, призванные выступать в роли единого и единственного источника истины, обеспечивающего менеджеров и аналитиков достоверной информацией, необходимой для оперативного анализа и принятия решений».
В основе концепции хранилищ данных лежат следующие основополагающие идеи:
- интеграция ранее разъединенных детализированных данных (исторические архивы, данные из традиционных систем обработки документов, разрозненных баз данных, данные из внешних источников) в едином хранилище данных;
- тематическое и временное структурирование, согласование и агрегирование ;
- разделение наборов данных, используемых для операционной (производственной) обработки, и наборов данных, используемых для решения задач анализа.
Данные, помещаемые в хранилище, должны отвечать определенным требованиям — предметной ориентированности, интегрированности, поддержки хронологии и неизменяемости (таблица 2.3).
| Предметная ориентированность | Все данные о некоторой сущности (бизнес-объекте, бизнес-процессе и т. д.) из некоторой предметной области собираются из множества различных источников, очищаются, согласовываются, дополняются, агрегируются и представляются в единой, удобной для их использования в бизнес-анализе форме |
| Интегрированность | Все данные о различных бизнес-объектах взаимно согласованы и хранятся в едином общекорпоративном хранилище |
| Поддержка хронологии | Данные хронологически структурированы и отражают историю за период времени, достаточный для выполнения задач бизнес-анализа, прогнозирования и подготовки принятия решения |
| Неизменяемость | Исходные (исторические) данные, после того как они были согласованы, верифицированы и внесены в общекорпоративное хранилище, остаются неизменными и используются исключительно в режиме чтения |
Хранилище данных выполняет множество функций, но его основное предназначение — предоставление точных данных и информации в кратчайшие сроки и с минимумом затрат.
Понятие хранилище данных в первоначальном понимании было основано на понятии распределенной витрины данных ( Distributed Data Mart — DDM ). Поэтому в классическом исполнении хранилище данных было прежде всего репозиторием (сквозной базой данных) данных и информации предприятия.
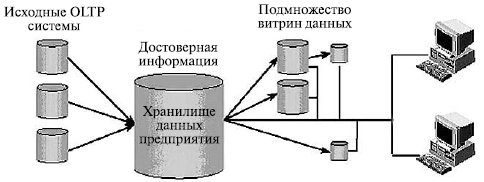
Среда хранилища была предназначена только для чтения и состояла из детальных и агрегированных данных, которые полностью очищены и интегрированы; кроме того, в репозитории хранилась обширная и детальная история данных на уровне транзакций. С точки зрения архитектурного решения такое хранилище данных реализует свои функции через подмножество зависимых витрин данных ( рис. 2.5).
Достоинствами архитектуры классического хранилища данных являются:
- общая семантика;
- централизованная, управляемая среда;
- согласованный набор процессов извлечения и бизнес-логики использования;
- непротиворечивость содержащейся информации;
- легко создаваемые по шаблонам и наполняемые витрины данных;
- единый репозиторий метаданных ;
- многообразие механизмов обработки и представления данных.
К недостаткам можно отнести большие затраты по реализации, высокую ресурсоемкость в масштабе всего предприятия, потребность в сложных сервисных системах, рискованный сценарий развития, когда все данные и метаданные находятся в одном репозитории и в неблагоприятном случае могут быть потеряны. Кроме того, при фильтрации, агрегировании и рафинировании «сырых» данных для такого хранилища обычно теряется очень много информации, которая может быть чрезвычайно полезной при бизнес-анализе. В связи с этим возникло понимание того, что хранилище, помимо механизмов размещения и извлечения данных (On Line Transactional Processing — OLTP ), репозитория и витрин, должно иметь соответствующее пространство для организации «сырых» данных и их многомерного анализа в режиме реального времени (On Line Analytical Processing — OLAP ).
Источник



