
- Увеличиваем производительность процессора
- Способы оптимизации и ускорения работы процессора
- Узнаём, пригоден ли процессор для разгона
- Способ 1: оптимизация при помощи CPU Control
- Способ 2: разгон при помощи ClockGen
- Способ 3: разгон процессора в BIOS
- Способ 4: оптимизация работы ОС
- Методы увеличения вычислительной производительности
Увеличиваем производительность процессора

Частота и производительность процессора может быть выше, чем указано в стандартных характеристиках. Также со временем использования системы производительность всех главных комплектующих ПК (оперативной памяти, ЦП и т.д.) может постепенно падать. Чтобы этого избежать, нужно регулярно “оптимизировать” свой компьютер.
Необходимо понимать, что все манипуляции с центральным процессором (особенно разгон) нужно проводить только если убеждены в том, что он сможет их “пережить”. Для этого может потребоваться выполнить тестирование системы.
Способы оптимизации и ускорения работы процессора
Все манипуляции по улучшению качества работы ЦП можно поделить на две группы:
- Оптимизация. Основной акцент делается на грамотное распределение уже доступных ресурсов ядер и системы, дабы добиться максимальной производительности. В ходе оптимизации трудно нанести серьёзный вред ЦП, но и прирост производительности, как правило, не очень высокий.
- Разгон. Манипуляции непосредственно с самим процессором через специальное ПО или BIOS для повышения его тактовой частоты. Прирост производительности в этом случае получается весьма ощутимым, но и возрастает риск повредить процессор и другие компоненты компьютера в ходе неудачного разгона.
Узнаём, пригоден ли процессор для разгона
Перед разгоном обязательно просмотрите характеристики своего процессора при помощи специальной программы (например AIDA64). Последняя носит условно-бесплатный характер, с её помощью можно узнать подробную информацию обо всех компонентах компьютера, а в платной версии даже проводить с ними некоторые манипуляции. Инструкция по использованию:
- Чтобы узнать температуру ядер процессора (это один из главных факторов при разгоне), в левой части выберите пункт “Компьютер”, затем перейдите в пункт “Датчики” из главного окна или меню пунктов.
- Здесь вы сможете просмотреть температуру каждого ядра процессора и общую температуру. На ноутбуке, при работе без особых нагрузок она не должна превышать 60 градусов, если она равна или даже немного превышает этот показатель, то от разгона лучше отказаться. На стационарных ПК оптимальная температура может колебаться в районе 65-70 градусов.
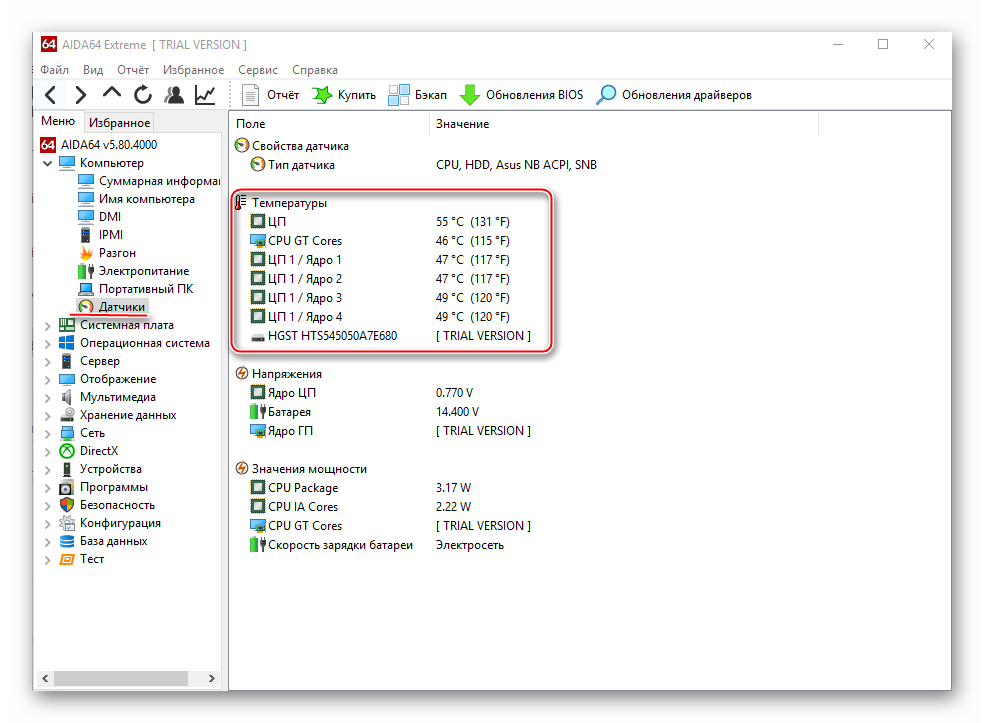
Если всё нормально, то перейдите в пункт “Разгон”. В поле “Частота ЦП” будет указано оптимальное число МГц при разгоне, а также процент, на который рекомендуется увеличить мощность (обычно колеблется в районе 15-25%).

Способ 1: оптимизация при помощи CPU Control
Чтобы безопасно оптимизировать работу процессора, потребуется скачать CPU Control. Данная программа имеет простой интерфейс для обычных пользователей ПК, поддерживает русский язык и распространяется бесплатно. Суть данного способа заключается в равномерном распределении нагрузки на ядра процессора, т.к. на современных многоядерных процессорах, некоторые ядра могут не участвовать в работе, что влечёт потерю производительности.
Инструкция по использованию данной программы:
- После установки откроется главная страница. Изначально всё может быть на английском. Чтобы это исправить, перейдите в настройки (кнопка “Options” в правой нижней части окошка) и там в разделе “Language” отметьте русский язык.
На главной странице программы, в правой части, выберите режим “Ручной”.
![]()
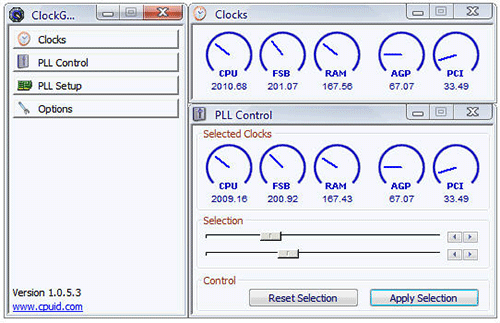
Способ 2: разгон при помощи ClockGen
ClockGen — это бесплатная программа, подходящая для ускорения работы процессоров любой марки и серии (за исключением некоторых процессоров Intel, где разгон невозможен сам по себе). Перед разгоном убедитесь, что все температурные показатели ЦП в норме. Как пользоваться ClockGen:
- В главном окне перейдите во вкладку «PLL Control», где при помощи ползунков можно изменить частоту процессора и работы оперативной памяти. Не рекомендуется за раз слишком сильно передвигать ползунки, лучше небольшими шагами, т.к. слишком резкие изменения могут сильно нарушить работу ЦП и ОЗУ.
- Когда получите необходимый результат, нажмите на «Apply Selection».
Способ 3: разгон процессора в BIOS
Довольно сложный и “опасный” способ, особенно для неопытных пользователей ПК. Перед разгоном процессора рекомендуется изучить его характеристики, в первую очередь, температуру при работе в штатном режиме (без серьёзных нагрузок). Для этого воспользуйтесь специальными утилитами или программами (описанная выше AIDA64 вполне подойдет для этих целей).
Если все параметры в норме, то можно приступать к разгону. Разгон для каждого процессора может быть разным, поэтому ниже представлена универсальная инструкция проведения данной операции через BIOS:
- Произведите вход в BIOS при помощи клавиши Del или клавиш от F2 до F12 (зависит от версии БИОСа, материнской платы).
- В меню BIOS найдите раздел с одним из таких наименований (зависит от вашей версии БИОСа и модели материнской платы) – “MB Intelligent Tweaker”, “M.I.B, Quantum BIOS”, “Ai Tweaker”.
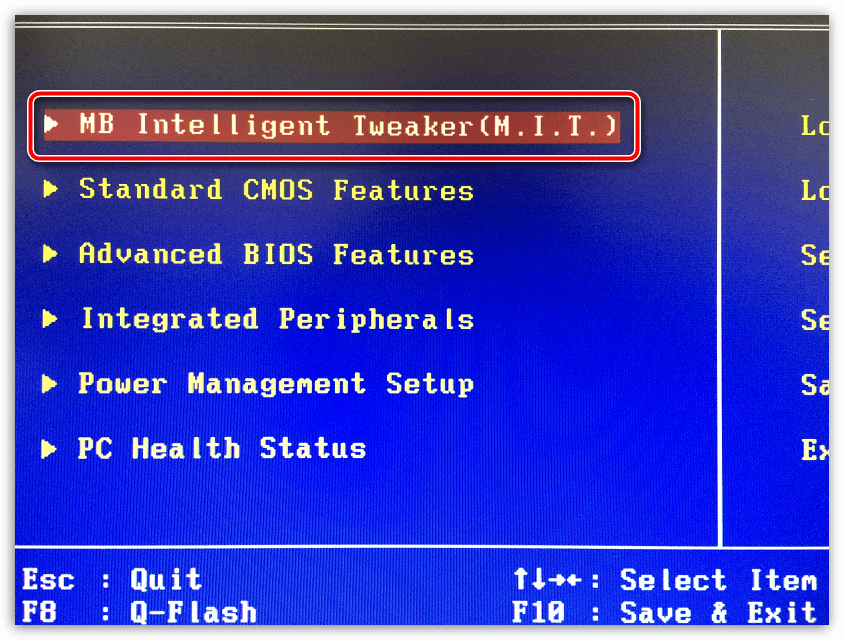
Теперь вы можете видеть данные о процессоре и вносить некоторые изменения. Перемещаться по меню можно при помощи клавиш со стрелочками. Переместитесь до пункта “CPU Host Clock Control”, нажмите Enter и поменяйте значение с “Auto” на “Manual”, чтобы можно было самостоятельно изменять настройки частоты.
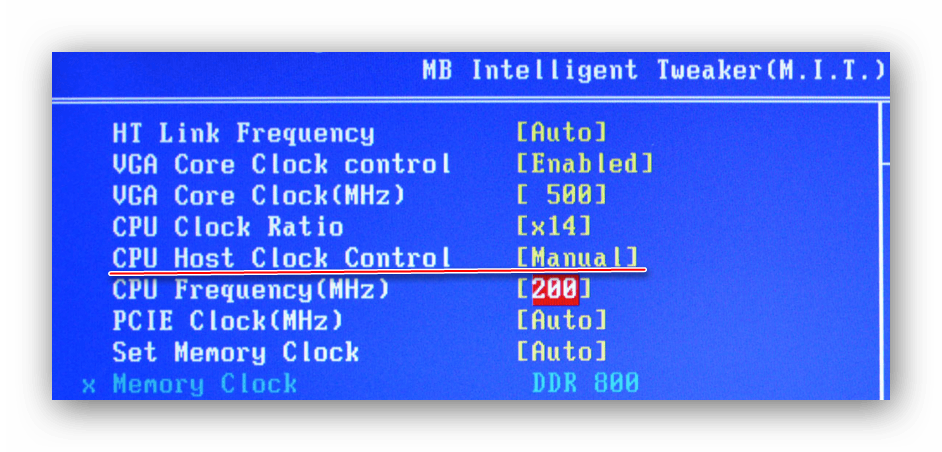
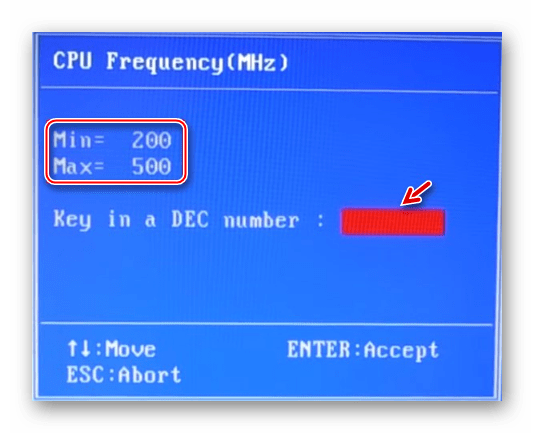
Спуститесь на пункт ниже к “CPU Frequency”. Чтобы внести изменения, нажмите Enter. Далее в поле “Key in a DEC number” введите значение в диапазоне от того, что написано в поле “Min” до “Max”. Не рекомендуется применять сразу максимальное значение. Лучше наращивать мощности постепенно, дабы не нарушить работу процессора и всей системы. Для применения изменений нажмите Enter.
Способ 4: оптимизация работы ОС
Это самый безопасный метод увеличения производительности ЦП путём очистки автозагрузки от ненужных приложений и дефрагментации дисков. Автозагрузка – это автоматическое включение той или иной программы/процесса при загрузке операционной системы. Когда в этом разделе скапливается слишком много процессов и программ, то при включении ОС и дальнейшей работе в ней, на центральный процессор может быть оказана слишком высокая нагрузка, что нарушит производительность.
В автозагрузку приложения можно добавлять как самостоятельно, так и приложения/процессы могут добавляться сами. Чтобы второго случая не было, рекомендуется внимательно читать все пункты, которые отмечены галочкой во время установки того или иного софта. Как убрать уже имеющиеся элементы из Автозагрузки:
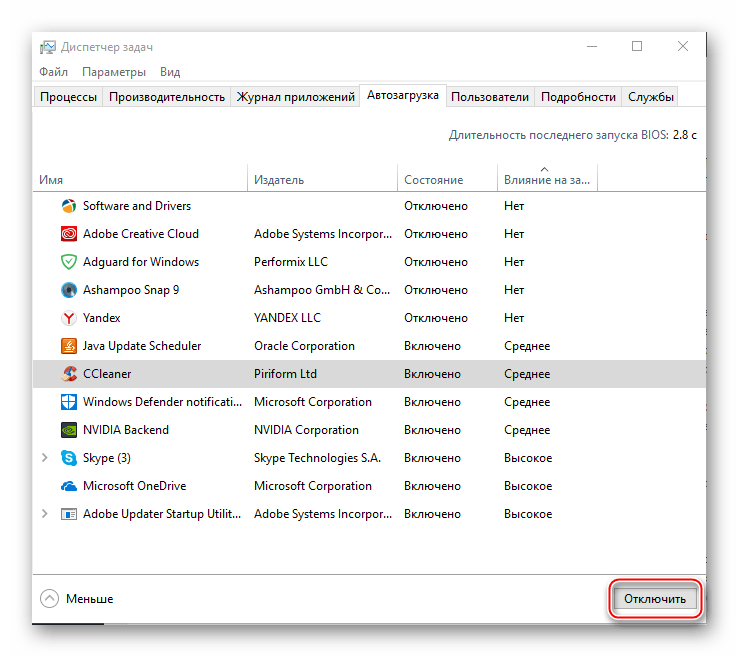
- Для начала перейдите в “Диспетчер задач”. Чтобы перейти туда, используйте комбинацию клавиш Ctrl+SHIFT+ESC или в поиске по системе вбейте “Диспетчер задач” (последнее актуально для пользователей на Windows 10).
- Перейдите в окно “Автозагрузка”. Там будут представлены все приложения/процессы, которые запускаются вместе с системой, их состояние (включено/отключено) и общее влияние на производительность (Нет, низкое, среднее, высокое). Что примечательно – здесь вы можете отключить все процессы, при этом не нарушите работу ОС. Однако, отключив некоторые приложения, вы можете сделать работу с компьютером немного неудобной для себя.
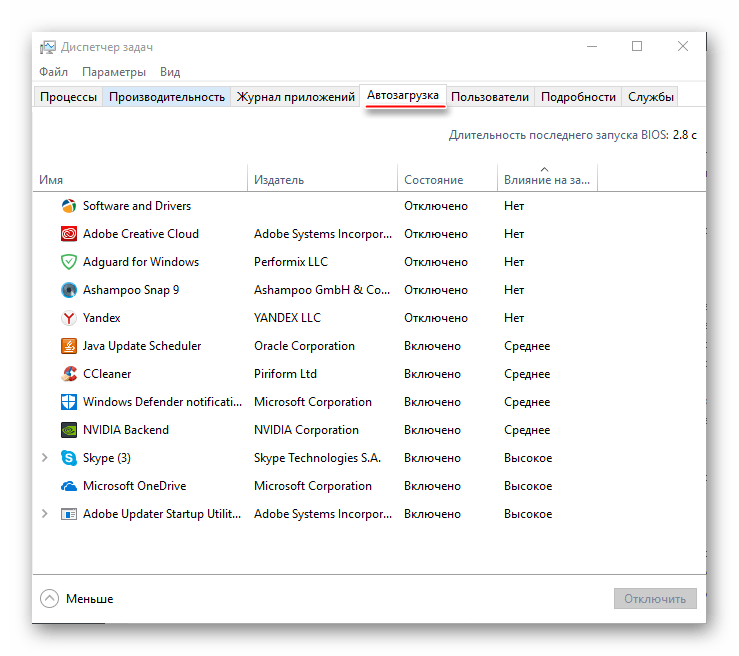
В первую очередь, рекомендуется отключать все пункты, где в колонке “Степень влияния на производительность” стоят отметки “Высокое”. Чтобы отключить процесс, кликните по нему и в правой нижней части окна выберите “Отключить”.
Дефрагментация диска увеличивает не только скорость работы программ на этом диске, но также немного оптимизирует работу процессора. Происходит это потому, что ЦП обрабатывает меньше данных, т.к. в ходе дефрагментации обновляется и оптимизируется логическая структура томов, ускоряется обработка файлов. Инструкция проведения дефрагментации:
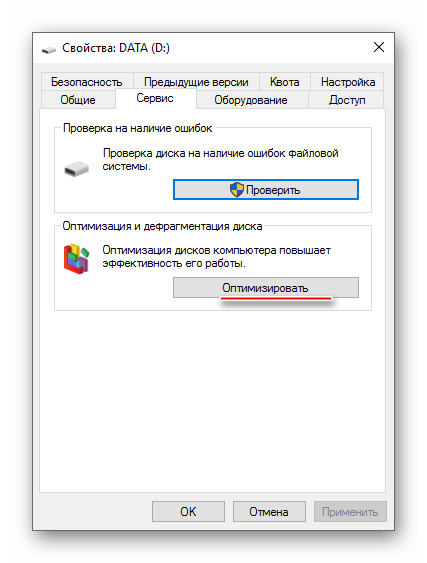
- Нажмите правой кнопкой мыши по системному диску (вероятнее всего, это (C:)) и перейдите в пункт “Свойства”.
- В верхней части окна найдите и перейдите во вкладку “Сервис”. В разделе “Оптимизация и дефрагментация диска” нажмите “Оптимизировать”.
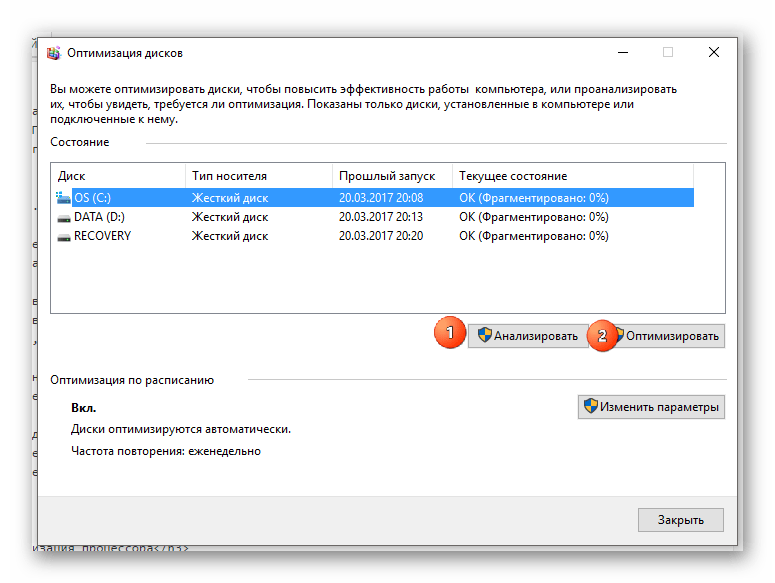
Рекомендуется также назначить автоматическую дефрагментацию дисков. Для этого перейдите по кнопке “Изменить параметры”, далее отметьте галочкой “Выполнять по расписанию” и задайте нужное расписание в поле “Частота”.
![]()
Оптимизировать работу ЦП не так сложно, как кажется на первый взгляд. Однако, если оптимизация не дала сколь-нибудь заметных результатов, то в этом случае центральный процессор потребуется разогнать самостоятельно. В некоторых случаях разгон не обязательно производить через БИОС. Иногда производитель процессора может предоставить специальную программу для увеличения частоты той или иной модели.
Помимо этой статьи, на сайте еще 12419 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Источник
Методы увеличения вычислительной производительности
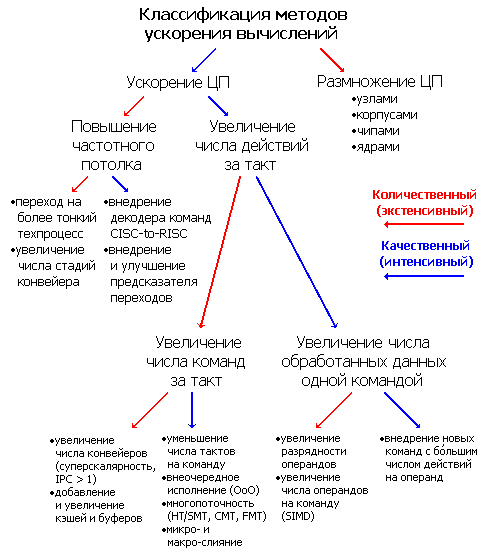
Всё время существования вычислительных машин, начиная ещё с арифмометров, создатели всегда хотели их ускорить. Какими способами у них это получалось и получается? Разумеется, никакого основного метода увеличить скорость вычислений нет, одновременно применяются почти все из до сих пор найденных. Поэтому для классификации потребуется разделение на качественные (интенсивные) и количественные (экстенсивные) ускорения. Разделение весьма условное — чёткой границы между методами повышения производительности нет, да и внутри себя они тоже делятся на разные подклассы. Т.к. за обработку данных отвечает один или несколько центральных процессоров (ЦП), а производительность является его/их главной характеристикой — большинство способов так или иначе касаются именно этой части системы. Заранее предупредим, что под процессором мы понимаем микросхему с корпусом и выводами, вставленную в разъём (сокет).
Первое разделение относится к числу процессоров: качественные методы предполагают ускорение работы ЦП при неизменном его/их количестве, количественные — наращивание числа ЦП с целью сложить их усилия. Многопроцессорные архитектуры применяются, когда другие способы уже внедрены и более не эффективны, и при должном умении инженеров и программистов дают отличный результат (если, конечно, задача хорошо распараллеливается) — совокупная производительность системы растёт почти линейно числу процессоров благодаря тщательно слаженной синхронизации взаимодействий вычислительных узлов. В последних выпусках рейтинга самых быстрых суперкомпьютеров планеты Top500 почти все машины используют кластерную архитектуру, основанную на концепции массового параллелизма (MPP, massively parallel processing). В этих вычислительных монстрах, занимающих целые залы, одновременно работают десятки, а скоро, возможно, и сотни тысяч процессоров.

Для ускорения таких систем применяется два способа — численно увеличить число узлов (вплоть до десятков тысяч) и ускорять сами узлы. Уже по цифрам видно, что для суперкомпьютеров первый способ — основной, но жрущие мегаватты и шумящие вентиляторами шкафы домашнему пользователю не подойдут. Так что не менее важной задачей будет ускорение системы, не приводящее к линейному увеличению её физических размеров. Самый очевидный (количественный) способ — нарастить число ЦП в пределах системного блока и платы. Качественно же (потому что это сложнее) требуется наращивать число вычислительных ядер внутри одного ЦП — что активно происходит и в персональных компьютерах. Наращивать можно, устанавливая несколько 1-ядерных чипов в один корпус, или делая чип с несколькими ядрами. Возможны и комбинации — 4-ядерные ЦП Intel Core 2 Quad имеют два 2-ядерных чипа. Более тесное расположение ядер имеет плюсы и минусы. Достоинства — умещается больше ядер на единицу физического объёма системы, возможен быстрый обмен данными между ядрами через внутрипроцессорные шины и общую кэш-память. Недостатки — у ядер есть общие конкурентно разделяемые ресурсы (кэши, контроллёры шин и памяти), многоядерные ЦП больше потребляют энергии и больше греются (а отвести сотни ватт с микросхемы — дело непростое, особенно, когда процессоров несколько), у однокристальных многоядерных ЦП меньше частотный потолок (максимальная частота, на которой надёжно заработает самая быстрая микросхема среди всех себе подобных) из-за отсутствия возможности согласовать характеристики нескольких ядер (а вот отдельные чипы согласовать можно). Несмотря на сложности, количественное усиление параметров системы размножением её компонентов практикуется давно: есть RAID-массивы для винчестеров, 2-3 видеокарты в одной упряжке и многомониторные конфигурации, 2-3-канальные контроллёры памяти — уместно добавить сюда и пару многоядерных процессоров.
Однако не каждая программа, особенно домашней неспециализированной направленности, хорошо распараллеливается на несколько потоков, задействуя все имеющиеся ядра. До сих пор многие игры (а из популярных программ именно они самые ресурсоёмкие) почти не ускоряются при числе ядер свыше двух, не говоря уже о линейном увеличении производительности при большем их числе. Так что ускорение самого ядра обязательно, особенно, если оно одно. Именно эта задача является самой сложной. Уже в первых вычислительных системах сразу после появления стали применять разнообразые способы, о которых пойдёт речь далее — путь был долгий. И тут снова нужно разделение на количественное и качественное улучшение. К количественному отнесём увеличение частоты ЦП, как его главной числовой характеристики («покупали мегагерцы» ещё в 80-х), а к качественному — число выполненных действий за каждый такт.
Увеличение частоты достижимо двумя способами. Физически: уменьшая проектные нормы, т.е. минимальные размеры проводников и транзисторов на чипе — за счёт этого последние работают быстрее и потребляют меньше энергии (это главная причина, почему в своё время мир отказался от ТТЛ- и ЭСЛ-семейств логики в пользу КМОП — у тех при уменьшении размеров таких масштабных приемуществ не было). И архитектурно: увеличивая частотный потолок разделением процессора на отдельные стадии, т.е. организацией вычислительного конвейера. А если он уже есть — увеличением числа этих стадий.
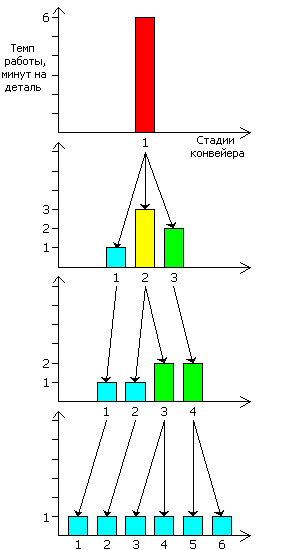
Рассмотрим для примера заводик, выпускающий некую деталь. Пока на нём 1 станок, обрабатывающий заготовку за 6 минут. Производительность — 10 деталей/час. Однако процесс можно разделить на 3 отдельных слабо связанных этапа, которые можно выполнять одновременно над тремя деталями — каждая на своей стадии. Ставим три станка вместо одного: первый над каждой деталью работает 1 минуту, второй 3 и третий 2. Общая производительность конвейера ограничивается самой медленной его частью — вторым станком. И хотя остальные часто простаивают, наш заводик выпускает уже 20 деталей/час. Чтобы оптимизировать конвейер, следует сделать работу его стадий максимально равномерной — передать часть работы со второго станка на первый так, чтобы оба работали за 2 минуты. Однако это не всегда получается, зато обнаруживается, что мы можем самую медленную часть системы («бутылочное горлышко») разделить на 2 этапа — пускай по 1 и 2 минуты каждый. Теперь у нас 4 станка с темпом работы 1, 1, 2 и 2 мин., соответственно. Всё бы хорошо, но количество железа увеличилось вчетверо, а вот скорость работы — всего втрое. А не нарезать ли нам конвейер ещё помельче — поставим 6 станков, работающих по одной минуте. Теперь мы затратили 6-кратное количество средств производства и получили 6-кратный выход продукта.
Вычислительный конвейер в однокорпусных процессорах (а до этого — в больших ЭВМ, где ЦП состоял из десятков микросхем) устроен так же. Его можно ускорить, разделив на стадии, но чтобы оптимально использовать транзисторы (при данном техпроцессе их число больше других факторов влияет на цену), стадии должны работать с максимально близким темпом. Поэтому, удвоив число стадий, новый ЦП на том же техпроцессе может поднять частотный потолок менее чем вдвое (если удвоение привело к неравномерной разбивке), более чем вдвое (см. пример со станками) или ровно вдвое (если всё было и осталось качественно разделено). Однако процесс обработки команд и данных нельзя «нашинковать» в произвольных местах на любое число кусков (хотя авторы последних модификаций Pentium 4 сделали такую попытку, получив в результате очень горячий и высокочастотный, но умеренно производительный процессор). Но главное — длинный конвейер панически боится условных переходов.
При возникновении в программе любого ветвления (что, по статистике, происходит каждые 7-10 команд) специальная схема (предсказатель переходов, первая стадия конвейера) должна за 1 такт «сообразить», сработает ли этот переход, и, если да, то куда — при том, что данные для вычисления управляющего условия могут быть не готовы. Безусловные переходы, вызовы и возвраты функций (кроме косвенных) требуют только предсказание целевого адреса, а для условных переходов надо предсказать и поведение. Хотя современные алгоритмы динамических предсказателей успешны на 98-99 % (1-2 % ошибок), и это неидеально. Допустим, что предсказатель 20-стадийного конвейера ЦП имеет успешность 98%, а условные переходы встречаются каждые 10 команд, причём сами команды в среднем выполняются за полтакта, т.к. процессор суперскалярный (см. далее). Каждая 50-я команда перехода будет неверно предсказана — 1 раз в 250 тактов придётся перегружать конвейер, очищая его от 20 накопившихся с неверной ветви команд. Таким образом, на каждые 270 тактов 20 мы выбрасываем впустую, снижая производительность на 7,4%. Нужно удвоить частотный потолок, удвоив число стадий конвейера — нет проблем, но готовимся к удвоенным штрафам (в тактах) за неверно предсказанные переходы. Или придётся улучшить предсказатель, что непросто, т.к. его рабочие таблицы и логика занимают много места, что снова приводит к увеличению стоимости (а она и так выросла от разбивки конвейера на мелкие стадии).
Разумеется, можно разрубить гордиев узел одним ударом — если не убрать условные переходы вообще, то минимизировать их количество, а те, что остались — сделать максимально предсказуемыми. Делается это как алгоритмически (т.е. зависит от мудрости авторов компиляторов и стандартных библиотек), так и архитектурно — в том же Pentium 4 внедрены специальные префиксы-подсказки (которые суть старые префиксы, игнорирующиеся перед командой перехода в ранних ЦП). Префиксы ставятся профайлером (модуль среды программирования для оценки времени выполнения и использования ресурсов) и намекаюn предсказателю на вероятное поведение этого перехода как минимум на первые несколько его выполнений (пока не накопится статистика срабатываний). Правда, в следующих архитектурах Intel и в любом процессоре AMD эти подсказки не действуют — слишком неточно. Можно вспомнить, что ещё с 80-х появились команды условного выполнения (установки константы и копирования значения), которые срабатывают только при «правильных» флагах. Всё это активно применяется и сейчас — тем не менее, резвого увеличения числа стадий конвейера со времён забвения Pentium 4 не наблюдается ни у одного производителя ЦП.
Впрочем, десяти и более стадий мы бы не увидели ни в одном процессоре, если бы не прозорливое решение Intel совместить коня и трепетную лань — быструю, но сложную для программирования архитектурную модель RISC с удобной, но медленной парадигмой CISC. Получившийся процессор, а это был Pentium Pro, имел внутренний декодер, транслирующий внешнюю CISC-команду набора x86 в одну или несколько внутренних RISC-подобных микроопераций (мопов) — они и путешествуют далее по конвейеру до исполнения. (Справедливости ради — в 1994 г., за год до PPro вышел NexGen Nx586 с почти таким же внутренним устройством, после чего NexGen была куплена AMD, и через 2 года вышел первый K5.) Более простые команды проще подготавливать и исполнять, но их самих требуется больше для реализации алгоритма. Тем не менее, получаемое частотное ускорение того стоит, хотя такой шаг можно сделать лишь раз: дальнейшее разбиение мопов на ещё более простые операции уже невозможно, поэтому это улучшение качественное, а не количественное.
Итак, частотный потолок увеличивается трудно. При этом большая частота требует большего напряжения питания, что увеличивает потребление энергии примерно в 5 раз на каждое удвоение частоты. (Идеальный полевой транзистор имеет линейную зависимость макс. частоты от напряжения питания, линейную зависимость энергопотребления от частоты и квадратичную — энергопотребления от напряжения, получая 8-кратное увеличение потребления и выделения ватт при удвоении герц. Однако паразитные ёмкости, утечки тока и прочие неидеальности делают зависимость сглаженной в сторону квадратичной, а не кубической.) Возможность пожарить яичницу на радиаторе ЦП вряд ли будет оценена как важное достоинство нового поколения процессоров, да и мобильная электроника с её тотальной экономией на всём требует энергоэффективности не в ущерб скорости — надо иметь способы ускорить производительность при уже имеющейся частоте.
Производительность за такт характеризуется двумя взаимно обратными величинами — среднее число тактов для выполнения одной команды (clocks per instruction, CPI) и среднее число выполненных за такт команд (instructions per clock, IPC). До появления суперскалярных ЦП главным способом ускорения помимо частотной гонки было уменьшение CPI (или увеличение IPC, хотя такой термин ещё не применялся за ненадобностью). Это можно отвести к качественному улучшению, т.к. главный способ один — вместо размножения или разгона имеющихся структур добавляются новые, аппаратно (т.е. быстрее) вычисляющие то, что ранее неспешно делалось в блоках общего назначения.
Для примера рассмотрим улучшения, позволившие 286-му процессору быть почти вдвое быстрее 86-го по CPI, выполняя тот же код:
- вместо единой мультиплексированной шины для адресов и данных в 286 эти шины отдельные, что удвоило пропускную способность по данным;
- декодер команд считывает не по одному, а по два байта за такт — длинные команды декодируются быстрее;
- регистровый файл (РФ) стал 2-портовым — за такт можно считать или записать пару регистров, а копирование «регистр-регистр» может быть сделано внутри самого РФ без использования внешнего буфера;
- появилось AGU — устройство генерации адреса, адресный калькулятор для вычисления смещения в текущем сегменте или странице с любым видом адресации быстрее вычисления адреса в общем АЛУ;
- все операции сдвига делаются не в АЛУ с темпом 4 такта/бит, а в отдельном последовательном регистре сдвига с темпом 1 такт/бит;
- появился отдельный счётчик для циклических операций (сдвиг, строки, многорегистровые операции со стеком);
- АЛУ имеет собственный простой регистр сдвига для хранения частичной суммы или остатка, что в 5-7 раз ускорило умножение и деление.
У 386-го процессора удвоили очередь предзагрузки команд (prefetch queue) до 12 байт, расширили до 3 байт разрядность декодера, добавили после него буфер микрокоманд (теперь это ЦП с 3-стадийным конвейером), и заменили последовательный регистр сдвига параллельным (barrel shifter, производит любой вид сдвига на любое число бит за фиксированное время). 486-й наделён конвейерным исполнением, встроенным вещественным блоком, буфером записи и внутренним кэшем L1 (тот, что на плате, теперь L2). 486DX2 получил возможность кэшировать в L1 запись (write-back, не во всех моделях), а 486DX4 — удвоенный кэш и матричный умножитель (правда, пока только целочисленный и половинной разрядности — 16·16). Все подобные улучшения продолжаются до сих пор — например, до появления архитектур AMD К10 и Intel Core 2 процессоры выполняли арифметические команды над векторными вещественными данными с темпом 2 такта — векторные АЛУ и умножители там половинной, 64-битной ширины, а у К10 и Core 2 они стали полноразрядными.
Когда почти каждая команда выполняется за 1-2 такта, а все функциональные устройства (ФУ, занимающиеся собственно исполнением команд) уже полноконвейерные, наступает этап суперскалярности — увеличения числа самих конвейеров. Теперь процессор может выполнить более одной команды за такт (IPC>1). Как и внедрение и увеличение буферов и кэшей, этот метод количественный. Казалось бы, увеличивай себе конвейеры и наслаждайся высокой производительностью (в ущерб площади ЦП). Однако на этом пути нас ждёт такое число подводных камней, что становится понятно, почему переход на 2-путную суперскалярность (считая количество архитектурных, а не внутренних команд) произошёл в 1993 г. (Pentium), на 3-путную — в 1995 (Pentium Pro), а на 4-путную — только в 2006 (Core 2, AMD же только собирается в 2011). Дело в том, что одновременно исполнять команды можно, только если они не конфликтуют:
- по записываемым регистрам (они должны отличаться от читаемых другими командами);
- по считываемым регистрам (на их число должно хватить портов РФ и кэша);
- по запрашиваемым ФУ (свободных ФУ должно хватить на все команды);
- по совокупной длине команд (иначе они не уместятся в декодер и не смогут быть одновременно распознаны);
- по отдельной длине команд (декодер длины команд не справится с кучей префиксов у нескольких инструкций за такт);
- по сложности (декодеру не хватит максимального числа мопов, генерируемых за такт);
- и пр.
Но самое главное — в программе могут почти не встречаться длинные цепочки команд, параллельно выполнимые даже на идеальном процессоре. В результате уже для перехода к трём конвейерам потребуются качественные «подпорки» для максимального заполнения конвейеров командами.
Главный такой костыль — внеочередное исполнение (Out-of-order execution, OoOE или OOO): мопы накапливаются в специальном перетасовочном буфере (reorder buffer, ROB) и считываются оттуда уже не в указанном программой порядке, а в произвольном при появлении возможности одновременного исполнения. Т.к. буфер вмещает десятки мопов, этого хватит на 3-4 запускаемые за такт команды, даже далеко стоящие друг от друга (если они уже считаны и декодированы). Особенно хорошо OOO работает с ещё одним механизмом улучшения — переименование регистров удаляет ложные взаимозависимости по операндам последующих команд от предыдущих. Однако и это пока не позволяет поднять IPC свыше 4-х. Отчасти потому, что мопов больше, чем команд, так что считывая 4 команды, мы получаем 5-10 мопов, для хранения и исполнения которых потребуется такое же количество свободных ресурсов каждый такт. Поэтому придумана схема слияния (fusion), позволяющая объединять на время предварительной подготовки пару команд (пока пару, но вполне возможно, что больше ни у кого не получится). Для мопов это микрослияние: декодер генерирует слитые мопы, которые при распределении запускаются в пару разных ФУ, выполняя там разные операции, что экономит число занятых мопами конвейерных шин и ячеек буферов. Для внешних команд это макрослияние: декодер трактует некоторые пары команд как одну, генерируя для неё 1 моп (возможно, тоже слитый), что в редких случаях также поднимает IPC.
Но и эти методы недостаточны, когда происходят такие рушащие производительность события, как неверно предсказанный переход, кэш-промах (запрошенная информация не закэширована), долго исполняющаяся команда и т.п. — при заторе в одной стадии остальные ждут, пока нужный ресурс станет доступным. Тогда между стадиями добавляют многочисленные буферы и очереди, сглаживающие разницу в производительности отдельных этапов и поддерживающие на плаву весь конвейер первые несколько тактов после фатального затора. А дальше всё равно надо откуда-то брать команды и данные. И если с текущей программой мы ничего сделать не сможем, пока не рассосётся затор, — может, переключимся на другую, раз уж все процессоры многозадачные?
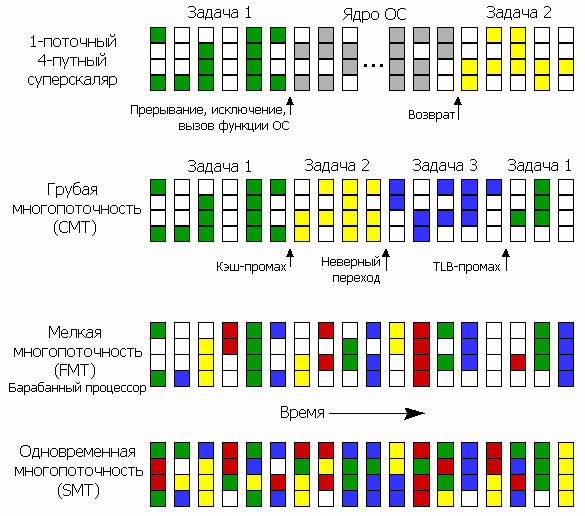
Родилась идея одновременной многопоточности (simultaneous multithreading или SMT, по терминологии Интел — гиперпоточность, hyper-threading/HT) или виртуальной многоядерности. Каждое физическое ядро представляется системе как несколько логических, хотя почти все ресурсы в них являются разделяемыми (кроме архитектурного РФ, стека адресов возврата и некоторых других блоков памяти, уникальных для каждого потока). При заторе в одном потоке ЦП может быстро всем конвейером переключиться на исполнение следующего одновременно с подкачкой нужного ресурса — при возврате в первый поток там уже будет всё готово. В случае плавного исполнения всех потоков переключение между ними происходит как при обычной многозадачности — программно, через интервалы и в зависимости от приоритета задачи. Но ещё лучше переключаться не всем конвейером, а отдельными свободными стадиями (именно это и подразумевается в SMT). Допустим, в двухпоточном ЦП буфер мопов после декодера оказался заполнен — тогда предсказатель переходов, загрузчик команд и декодер (т.е. все стадии до буфера) переключаются на другой поток, заполняя его мопами либо отведённую для этого потока половину буфера, либо динамически «отнимая» от первого потока часть места для второго. Суперскалярные процессоры могут также одновременно запускать на исполнение (в т.ч. внеочерёдное) мопы разных потоков и вперемешку считывать для них данные из кэша. Более того, т.н. барабанный процессор (barrel processor, который, возможно, будет реализован в грядущей архитектуре AMD Bulldozer) вообще может переключаться на следующий поток каждый такт всеми стадиями конвейеров (кроме занятых более одного такта) вне зависимости от того, произошёл ли в течение этого такта затор или нет.
Впрочем, OOO и SMT не могут поднять производительность выше пиковой, определяемой числом конвейеров (уровнем суперскалярности) и скоростью срабатывания ФУ — они лишь нивелируют неизбежные заторы команд и данных, уменьшая простои и максимально загружая ресурсы. Чтобы повысить скорость ещё, требуется что-то сделать не на уровне команд, а на уровне обрабатываемых ими данных. Первое, что пришло бы в голову, окажись мы в 80-х — увеличить разрядность обрабатываемых данных до 32-х бит (количественное решение). Но для целых чисел больше, как правило, не надо (кроме вычисления адресов для 64-битного режима), для вещественных 64 бита двойной точности тоже давно достигнуты, так что увеличение разрядности означает переход к векторным вычислениям (согласно парадигме SIMD — одна команда, много данных) и увеличение числа компонент вектора. До сих пор большинство процессоров (не только x86) обходились 128-битными векторами, куда умещается пара вещественных чисел двойной точности или целых 64-битных (раз уж ЦП таки перешли на 64-битные вычисления спустя почти 20 лет после перехода на 32 бита), либо 4 32-битных значения (целых или одинарных вещественных). Intel впервые встроила векторные ФУ сразу в ЦП (вместо возможного векторного сопроцессора), хотя они сначала были 64-битные (целочисленная технология MMX, а ещё раньше, в 1989 г. — аналогичное векторное ФУ для RISC-ЦП i860). В последнее время внедрение других способов ускорить ЦП слишком усложнилось, так что Intel снова предлагает увеличить разрядность векторов — вдвое в наборе команд AVX для ЦП общего назначения, а в специальном (но тоже x86-совместимом) процессоре Larrabee — даже вчетверо (до 512 бит), оставляя место и для дальнейших расширений. Вспоминается судьба японских суперкомпьютеров NEC серии SX, считающих векторами по 8 компонент (512 бит) и проигрывающих по пиковой производительности многоузловым кластерным системам традиционной «настольной» архитектуры за ту же цену — с несколькими многоядерными ЦП в узле, каждый из которых обрабатывает 128-битные векторы.
Единственный качественный способ ускорить обработку данных при фиксированном числе команд — внедрять новые команды, исполняющие над данными больше действий, заменяя несколько (иногда даже десятков) простых инструкций. Это не только уменьшает размер кода, но и ускоряет его, т.к. исполнение новой команды будет скорее аппаратное, а не микропрограммное. Вот примеры:
- операции над всеми регистрами сразу (сохранение всего РФ в стеке и восстановление из него);
- непосредственные операнды в командах (где они были недоступны);
- операции с битами и битовыми полями (поиск, выборка, вставка и замена);
- операции с изменением формата на лету (расширение нулём и знаком, перевод из вещественных в целые или обратно, изменение точности, маскированная запись);
- условные операции (копирование, запись константы);
- многоразрядные операции с переносом (для наращивания размера обрабатываемых данных, если они не умещаются в одном регистре);
- команды с регулировкой точности (умножение с получением только старшей или младшей половины результата, приближённые вещественные вычисления и увеличение их точности аппроксимацией);
- слитые команды (умножение-сложение, сложение-вычитание, сравнение-обмен, синус-косинус, перетасовка компонентов вектора, минимум, максимум, среднее, модуль, знак);
- горизонтальная арифметика (источники и приёмник являются компонентами одного вектора);
- недеструктивные операции (приёмник не перезаписывает источники — не требуется предварительная команда копирования одного из операндов в новый регистр);
- программно-специфичные команды (подсчёт контрольной суммы и битовой населённости, поиск подстроки, сумма модулей разностей, индекс и значение минимума в векторе, скалярное произведение).
По числу пунктов выше видно, что добавление дополнительных наборов команд — один из основных методов увеличения скорости ЦП. Уже сейчас общее число команд в архитектуре x86 перевалило за 1000, что привело к исключительному усложнению декодеров и ФУ, а также к сильному затруднению программирования и оптимизации на ассемблере. Тем не менее, Intel (а именно она ввела подавляющее большинство таких наборов) продолжает снабжать новые процессоры очередными видами инструкций, заставляя то же самое делать и конкурента.
Предсказать ветвления технической мысли инженеров, архитекторов и микроэлектронщиков, пытающихся найти очередной способ ускорить процессор — задача не проще, чем самому ЦП предсказать ветвления в исполняемой программе с 99%-ной точностью. Тем не менее, если посмотреть с высоты на историю методов ускорения вычислений, замечается любопытная закономерность: сначала некий способ появляется в больших машинах — мэйнфреймах и суперкомпьютерах, где он проверяется и оттачивается. Затем, благодаря прогрессу в микроэлектронике, то, что ранее занимало шкафы и залы, стало возможным уместить на одну плату, потом в корпус процессора, а затем и на его чип. Конвейеры, кэши, суперскалярность, ОOО, SIMD и остальное — всё это родом из 60-80-х. Надо полагать, что подобное будет происходить и далее — просто посмотрим на сегодняшние суперкомпьютеры и постараемся через 10-20 лет сделать то же самое в одной микросхеме. Однако тут ждёт неожиданная развязка — большинство мощнейших компьютеров планеты сегодня сами основаны на архитектуре x86. Просто она оказалось столь успешной и универсальной, так быстро вобрала в себя всё лучшее от конкурентов, что, наоборот, это суперкомпьютеры теперь делаются на архитектуре, изначально созданной для персоналок. Фактически, вычислительная техника, сделав полный круг, упёрлась сама в себя.
Возможно, спасением будет новая, некремниевая микроэлектроника (вообще-то, она уже давно «нано-») — либо углеродная на графене и нанотрубках, либо квантовая на спинтронных транзисторах или «запутанных» частицах. А может, и без электричества вообще — фотоника активно изучается той же Intel, которая уже добилась создания интегральных волноводов и исследует методы создания фотонного транзистора. Всё это способно поднять частотный потолок (ведь отказываться от идеи синхронных вычислителей не собираются, хотя, например, человеческий мозг является «нетактируемой вычислительной машиной»), а вот какие будут качественные идеи (помимо очередного SSE8) — точно никто не знает. Поэтому пресловутый закон Мура (который никакой не закон, а эмпирическая закономерность, не очень чётко, но всё же соблюдающаяся в течение десятилетий) последнее время постоянно подвергается сомнению — протянем ещё годков пять, или наступит-таки конец экспоненциальному росту?
Впрочем, рост может и не понадобиться. Как сказал в 90-х один пользователь, имевший отношение к ВПК, «моего компьютера с 486-м процессором с головой хватило бы для управления всей группировкой советских военных спутников, но его не хватает на одновременный набор и распечатку текста в Word’е». Десятки гигафлопов и доступность программирования на языках высокого уровня, скрывающих сложность аппаратных тонкостей, настолько развратили многих программистов, что они и думать перестали о какой-то там экономии и оптимизации — зачем, если пользователь просто подождёт полгода и проапгрейдится, а за это время лучше не оптимизировать текущую версию программы, а сделать новую и продать её подороже. Когда программирование из творчества превратилось в поточное ремесло (массовый ПК подразумевает массовое ПО и массового программиста), главными стали не качество, скорость и удобство, а способы побыстрее заработать деньги. Выходит, что после внедрения всех относительно простых и недорогих ускорителей производительности главным способом сделать компьютер ещё быстрее может оказаться оптимизация программ и экономия уже имеющихся ресурсов. Но это уже тема другой статьи.
Источник



