
- Как создать pandas DataFrame
- Создать DataFrame из данных, записанных в коде программы
- Создать DataFrame из csv файла
- Создать DataFrame из jsonl файла
- Создать DataFrame из результата sql запроса
- Создать DataFrame из файла в интернете
- Python и Pandas: учебник DataFrame с примерами
- Вступление
- Создание DataFrame
- Создание пустого DataFrame
- Создание DataFrame из списков
- Создание DataFrame из словарей
- Чтение DataFrame из файла
- Манипулирование Фреймами Данных
- Доступ/Расположение Элементов
- Манипулирование Индексами
- Манипулирование строками (rows)
- Манипулирование столбцами (columns)
- Вывод
Как создать pandas DataFrame
DataFrame — это специальная структура данных в очень популярной Python библиотеки pandas. Работа с библиотекой pandas часто заключается в том что нужно создать из данных DataFrame, а дальше что-то делать с этими данными, лежащими в DataFrame.
Есть несколько способов создать DataFrame.
Создать DataFrame из данных, записанных в коде программы
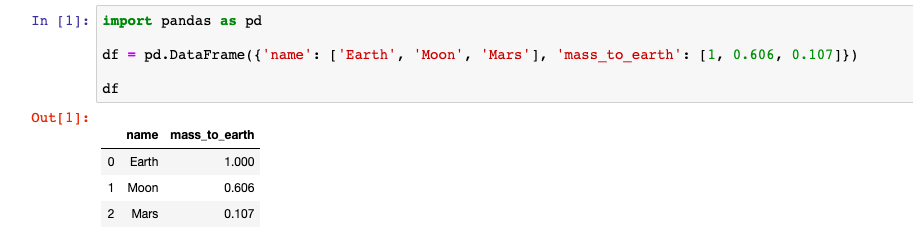
Самый простой способ создать DataFrame — это передать конструктору словарь. Ключи станут названиями колонок, а значения (в которых содержатся списки) станут данными в этих колонках.
Вот пример как это выглядит в Jupyter Notebook:
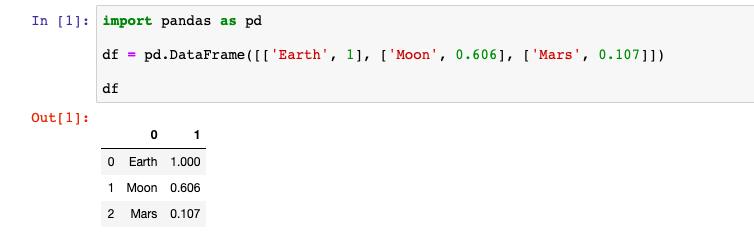
Но не всегда удобно задавать данные по столбцам. Можно создать DataFrame и из данных, которые разбиты по строкам. Для этого в конструктор нужно передать список в котором содержатся данные для строк. Вот пример создания DataFrame с данными как из прошлого примера, но по строкам, а не по столбцам:
Но при такой записи система не знает как нужно называть столбцы, поэтому названия столбцов становятся числа начиная с нуля. В этих данных две колонки, поэтому они называются ноль и один:
Для того чтобы вместо чисел были осмысленные названия колонок нужно указать список названий в именованном аргументе columns:
Но запись данных в коде программы подходит только для очень простых ситуаций, когда данных немного. Обычно данные в DataFrame загружаются из какого-то внешнего источника, например из файла из из базы данных.
Создать DataFrame из csv файла
Вот содержимое файла solar-system.csv:
Csv — это очень распространенный формат (расшифровывается как «comma separated values»,— «значения разделенные запятыми»). В файле solar-system.csv в первой строчке находится заголовок с названиями столбцов, все остальные строки — это данные. Разделитель между элементами это символ запятая. Для того чтобы загрузить данные из этого файла в DataFrame нужно сказать:
Но иногда формат csv файла выглядит несколько иначе. Бывает что в качестве разделителя используется не запятая, а какой-то другой символ, например точка с запятой или символ табуляции (в это случае файл иногда бывает с расширением .tsv — «tab separated values»). read_csv можно указать какой разделитель использовать:
Бывает что в csv файле нет заголовка, в первой строке сразу идут данные. В таком случае нужно передать None в именованный параметр header:
Но в такой ситуации система не будет знать какие названия столбцов использовать и будут использованы цифры начиная с нуля. Для того чтобы установить имена колонок нужно передать параметр names:
Создать DataFrame из jsonl файла
Кроме csv еще есть достаточно популярный формат для хранения данных в текстовых файла — jsonl. JSON Lines. При использовании этого формата в каждой строчке файла содержится однострочный json. Это формат лучше чем csv, так как строго регламентирует что должно быть разделителем и как нужно экранировать.
Вот пример содержимого файла solar-system.jsonl:
Для того чтобы загрузить его в DataFrame нужно сказать:
Создать DataFrame из результата sql запроса
Вот пример кода, который загружает в DataFrame таблицу с результатом sql запроса из sqlite базы данных:
Создать DataFrame из файла в интернете
Иногда необходимо создать DataFrame с данными которые лежат где-то в интернете. Например, создать DataFrame из csv файла, который лежит на GitHub.
Источник
Python и Pandas: учебник DataFrame с примерами
В этой статье мы познакомимся с DataFrame из библиотеки Pandas и узнаем как они хранят информацию. Затем мы создадим их вручную и из файлов, а также рассмотрим способы манипуляции данными внутри них.
Автор: Olivera Popović
Дата записи
Вступление
Pandas – библиотека Python с открытым исходным кодом для анализа данных. Она предназначена для эффективной и интуитивной обработки структурированных данных.
Двумя основными структурами данных в Pandas являются Series (Ряды) и DataFrame. Ряды являются по существу одномерными маркированными массивами любого типа данных, в то время как DataFrames являются двумерными, с потенциально гетерогенными типами данных, маркированными массивами любого типа данных. Гетерогенный означает, что не все «ряды» должны быть одинакового размера.
В этой статье мы рассматрим наиболее распространенные способы создания DataFrame и методы изменения их структуры.
Мы будем использовать блокнот Jupyter, так как он предлагает хорошее визуальное представление DataFrames. Однако любая среда IDE также выполнит эту работу, просто вызвав инструкцию print() для объекта DataFrame.
Создание DataFrame
Каждый раз, когда создается DataFrame, независимо от того, создается ли он вручную или создается из источника данных, например файла, данные должны упорядочиваться в табличном виде как последовательности строк с данными.
Это означает, что строки имеют одинаковый порядок полей, т.е. если требуется DataFrame с информацией об имени и возрасте человека, необходимо убедиться, что все строки содержат информацию одинаково.
Любое несоответствие приведет к тому, что DataFrame будет неисправен, что приведет к ошибкам.
Создание пустого DataFrame
Создать пустой DataFrame так же просто, как:
Рассмотрим, как можно добавлять строки и столбцы в этот пустой DataFrame при управлении их структурой.
Создание DataFrame из списков
Следуя принципу «последовательность строк с одинаковым порядком полей», можно создать DataFrame из списка, который содержит такую последовательность, или из нескольких списков объединённых вместе функцией zip() таким образом, что они обеспечивают последовательность так:
Такого же эффекта можно было бы достичь, если бы данные находились в нескольких списках и были объединены вместе с помощью zip(). Этот подход может быть использован, когда данные, которые мы имеем, предоставляются в виде списков значений для одного столбца (поля), вместо вышеупомянутого способа, в котором список содержит данные для каждой конкретной строки.
Это означает, что у нас есть все данные (по порядку) для столбцов по отдельности, которые, будучи сжатыми вместе, создают строки.
Возможно, вы заметили, что метки столбцов и строк не очень информативны в созданном нами DataFrame. Можно передать эту информацию при создании DataFrame.
Что даёт нам тот же результат, что и раньше, только с более значимыми именами столбцов:
Другим представлением данных, которое можно использовать здесь, является предоставление данных в виде списка словарей в следующем формате:
В нашем примере представление будет выглядеть следующим образом:
И мы создадим DataFrame таким же образом, как и раньше:
Создание DataFrame из словарей
Словари являются еще одним способом предоставления данных в виде столбцов. Каждому столбцу присваивается упорядоченный список строк значений.
Давайте представим те же данные, что и раньше, но в формате словаря:
Что дает нам ожидаемый результат:
Чтение DataFrame из файла
Для чтения и записи DataFrames поддерживается множество типов файлов. Каждая функция соответствует типу файла, например read_csv(), read_excel(), read_json(), read_html() и т.д.
Наиболее распространенным типом файла является .csv (значения разделенные запятыми). Строки состоят из значений, разделенных специальным символом (чаще всего запятой). Можно задать другой разделитель с помощью аргумента sep.
Если вы не знакомы с типом файла .csv , вот пример того, как он выглядит:
Обратите внимание, что первой строкой в файле являются имена столбцов. Конечно, можно указать, с какой строки Pandas должен начать считывать данные, но по умолчанию Pandas рассматривает первую строку как имена столбцов и начинает загрузку данных из второй строки:
Что дает нам на выходе:
Манипулирование Фреймами Данных
В этом разделе рассматриваются основные методы изменения структуры DataFrame. Однако прежде чем перейти к этой теме, необходимо знать, как получить доступ к отдельным строкам или группам строк, а также к столбцам.
Доступ/Расположение Элементов
Pandas имеет два разных способа выбора данных – loc[] и iloc[].
loc[] позволяет выбирать строки и столбцы с помощью меток, таких как row[‘Value’] и culumn[‘Other Value’]. В то же время, iloc[] принимает индекс записей, которые вы хотите выбрать, поэтому вы можете использовать только числа. Можно также выбрать столбцы, просто передав их имя в скобки. Посмотрим, как это работает в действии:
Это также работает для группы строк, от 0 до n:
Важно отметить, что iloc[] всегда ожидает целое число. loc[] поддерживает и другие типы данных. Здесь мы также можем использовать целое число на ряду с другими типами данных, например строки.
Также можно получить доступ к определенным значениям для элементов. Например, может потребоваться получить доступ к элементу во 2-й строке, но вернуть только его значение Name:
Доступ к столбцам так же прост, как запись dataFrameName.ColumnName или dataFrameName [‘ColumnName’]. Второй вариант предпочтителен, так как столбец может иметь то же имя, что и зарезервированное имя в Pandas, и использование первого варианта в этом случае может вызвать ошибки:
Доступ к столбцам можно также получить с помощью loc[] и iloc[]. Например, мы получим доступ ко всем строкам, начиная с 0…n, где n – количество строк, и выберем первый столбец. Вывод совпадает с выводом предыдущей строки кода:
Манипулирование Индексами
Индексы – это метки строк в DataFrame и именно их мы используем при обращении к строкам. Поскольку мы не изменили индексы по умолчанию, которые Pandas присваивают DataFrame при создании, все наши строки были помечены целыми числами от 0 и выше.
Первый способ изменить индексацию вашего DataFrame – это использовать метод set_index() . Мы передаем любой из столбцов в вашем DataFrame этому методу, и он становится новым индексом. Таким образом, мы можем либо сами создавать индексы, либо просто назначить столбец в качестве индекса.
Обратите внимание, что метод не изменяет исходный DataFrame, а вместо этого возвращает новый DataFrame с новым индексом, поэтому мы должны назначить возвращаемое значение переменной DataFrame, если мы хотим сохранить изменение, или установить флаг inplace равным True:
Это будет работать так же хорошо:
Теперь, когда у нас есть нестандартный индекс, мы можем использовать новый набор значений, используя reindex(), Pandas автоматически заполнит значения NaN для каждого индекса, который не может быть сопоставлен с существующей строкой:
Вы можете контролировать, какое значение Pandas использует для заполнения пропущенных значений, установив необязательный параметр fill_value :
Поскольку мы установили новый индекс для нашего DataFrame, loc[] теперь работает с этим индексом:
Манипулирование строками (rows)
Добавление и удаление строк становится простым, если удобно использовать loc[]. Если задать несуществующую строку, она будет создана:
И если вы хотите удалить строку, вы указываете ее индекс функции drop () . Он принимает необязательный параметр axis . Ось | принимает 0 / индекс или 1 / колонки . В зависимости от этого функция drop() отбрасывает либо вызываемую строку, либо вызываемый столбец.
Если требуется удалить строку, необходимо указать ее индекс для функции drop(). Она принимает необязательный параметр, axis. Axis может быть 0/index или 1/columns. В зависимости от этого функция drop() удаляет строку или столбец для которого она была вызвана.
Если не указать значение параметра axis , то соответствующая строка будет удалена по умолчанию, так как axis 0 по умолчанию:
Если не указать значение параметра axis, соответствующая строка будет удалена по умолчанию, так как axis по умолчанию равен 0:
Вы также можете переименовать строки, которые уже существуют в таблице. Функция rename() принимает словарь изменений, которые вы хотите внести:
Обратите внимание, что drop() и rename() также принимают необязательный параметр inplace . Установка этого параметра в True ( False по умолчанию) скажет Pandas изменить исходный DataFrame вместо того, чтобы возвращать новый. Если оставить его не заданным, вам придется упаковать полученный DataFrame в новый, чтобы сохранить изменения.
Другим полезным методом, о котором следует знать, является функция drop_duplicates(), которая удаляет все повторяющиеся строки из DataFrame. Давайте продемонстрируем это, добавив две повторяющиеся строки:
Что дает нам выход:
Теперь мы можем вызвать drop_duplicates() :
И дубликаты строк будут удалены:
Манипулирование столбцами (columns)
Новые столбцы можно добавлять аналогично добавлению строк:
Также, как и строки, столбцы можно удалить, вызвав функцию drop() , с той лишь разницей, что вы должны установить необязательный параметр axis в значение 1 чтобы Pandas знали, что вы хотите удалить столбец, а не строку:
Когда речь идет о переименовании столбцов, функции rename() нужно сказать конкретно, что мы хотим изменить столбцы, установив необязательные параметр columns значение нашего “словаря изменений”:
Опять же, как и при удалении/переименовании строк, вы можете установить необязательный параметр на месте в True если вы хотите, чтобы исходный DataFrame был изменен вместо функции, возвращающей новый DataFrame .
Опять же, как и при удалении/переименовании строк, можно установить для параметра inplace значение True, если требуется изменить исходный DataFrame вместо создания нового DataFrame.
Вывод
В этой статье мы рассмотрели, что такое Pandas DataFrame s, поскольку они являются ключевым классом из фреймворка Pandas, используемого для хранения данных.
В этой статье мы рассмотрели, что такое Pandas DataFrame, поскольку он является ключевым классом фреймворка Pandas для хранения данных.
Мы научились создавать DataFrame вручную, используя список и словарь, после чего считывали данные из файла.
Затем мы манипулировали данными в DataFrame – используя loc[] и iloc[] , мы находили данные, создавали новые строки и столбцы, переименовывали существующие и затем удаляли их.
Затем мы манипулировали данными в DataFrame используя loc[] и iloc[]. Мы обнаружили данные, создали новые строки и столбцы, переименовали существующие, а затем удалили их.
Источник



