
Кодирование для чайников, ч.1
Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
0. Начало
Поскольку я обращаюсь к новичкам в этом вопросе, то не посчитаю зазорным обратиться к Википедии. А там, для обозначения кодирования информации, у нас есть такое определение — процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Чего мне не хватало в 70-80-е, так это в школе, пусть не на информатике, а, например, на уроках математики — базовой информации по кодированию. Дело в том, что кодированием информации каждый из нас занимается ежесекундно, постоянно и в целом — не концентрируясь на самом кодировании. То есть в быту мы это делаем постоянно. Так как это происходит?
Мимика, жесты, речь, сигналы разного уровня — табличка с надписью, знак на дороге, светофоры, и для современного мира — штрих- и бар-коды, URL, хэш-тэги.
Давайте рассмотрим некоторые более подробно.
1.1 Речь, мимика, жесты
Удивительно, но всё это — коды. С помощью них мы передаём информацию о своих действиях, ощущениях, эмоциях. Самое важное, чтобы коды были понятны всем. Например, родившись в густых лесах у Амазонки и не видя современного городского человека, можно столкнуться с проблемой непонимания кода — улыбка, как демонстрация зубов, будет воспринята как угроза, а не как выражение радости.
Следуя определению, что же происходит когда мы говорим? Мысль — как форма, удобная для непосредственного использования, преобразуется в речь — форму удобную для передачи. И, смотрите, так как у звука есть ограничение как на скорость, так и на дальность передачи, то, например, жест, в какой-то ситуации, может быть выбран для передачи той же информации, но на большее расстояние.
Но мы всё еще будем ограничены дальностью остроты нашего зрения, и тогда — человек начинает придумывать другие способы передачи и преобразования информации, например огонь или дым.
1.2 Чередующиеся сигналы
В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы «включено/выключено». Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.
Наряду с сигнальными флажками на морских и речных судах, при появлении радио начали использовать код Морзе. И при всей кажущейся бинарности (представление кода двумя значениями), так как используются сигналы точка и тире, на самом деле это тернаный код, так как для разделения отдельных кодов-символов требуется пауза в передаче кода. То есть код Морзе кроме «точка-тире», что нам даёт букву «A» может звучать и так — «точка-пауза-тире» и тогда это уже две буквы «ET».

1.3 Контекст
Когда мы пользуемся компьютером, мы понимаем, что информация бывает разной — звук, видео, текст. Но в чем основные различия? И до того, как начать информацию кодировать, чтобы, например, передавать её по каналам связи, нужно понять, что из себя представляет информация в каждом конкретном случае, то есть обратить внимание на содержание. Звук — череда дискретных значений о звуковом сигнале, видео — череда кадров изображений, текст — череда символов текста. Если мы не будем учитывать контекст, а, например, будем использовать азбуку Морзе для передачи всех трёх видов информации, то если для текста такой способ может оказаться приемлемым, то для звука и видео время, затраченное на передачу например 1 секунды информации, может оказаться слишком долгим — час или даже пара недель.
2. Кодирование текста
От общего описания кодирования перейдём к практической части. Из условностей мы за константу примем то, что будем кодировать данные для персонального компьютера, где за единицу информации приняты — бит и байт. Бит, как атом информации, а байт — как условный блок размером в 8 бит.
Текст в компьютере является частью 256 символов, для каждого отводится один байт и в качестве кода могут быть использованы значения от 0 до 255. Так как данные в ПК представлены в двоичной системе счисления, то один байт (в значении ноль) равен записи 00000000, а 255 как 11111111. Чтение такого представления числа происходит справа налево, то есть один будет записано как 00000001.
Итак, символов английского алфавита 26 для верхнего и 26 для нижнего регистра, 10 цифр. Так же есть знаки препинания и другие символы, но для экспериментов мы будем использовать только прописные буквы (верхний регистр) и пробел.
Тестовая фраза «ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП».
2.1 Блочное кодирование
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:
Источник
Основы информатики
Примеры двоичного кодирования информации
Среди всего разнообразия информации, обрабатываемой на компьютере, значительную часть составляют числовая, текстовая, графическая и аудиоинформация. Познакомимся с некоторыми способами кодирования этих типов информации в ЭВМ.
Кодирование чисел
Существуют два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел.
Множество целых чисел, представимых в памяти ЭВМ, ограничено. Диапазон значений зависит от размера области памяти, используемой для размещения чисел. В k-разрядной ячейке может храниться 2 k различных значений целых чисел.
Чтобы получить внутреннее представление целого положительного числа N, хранящегося в k-разрядном машинном слове, необходимо:
- перевести число N в двоичную систему счисления;
- полученный результат дополнить слева незначащими нулями до k разрядов.
Пример. Получить внутреннее представление целого числа 1607 в 2-х байтовой ячейке.
Переведем число в двоичную систему: 160710 = 110010001112. Внутреннее представление этого числа в ячейке будет следующим: 0000 0110 0100 0111.
Для записи внутреннего представления целого отрицательного числа (-N) необходимо:
- получить внутреннее представление положительного числа N;
- обратный код этого числа заменой 0 на 1 и 1 на 0;
- полученному числу прибавить 1.
Пример. Получим внутреннее представление целого отрицательного числа -1607. Воспользуемся результатом предыдущего примера и запишем внутреннее представление положительного числа 1607: 0000 0110 0100 0111. Инвертированием получим обратный код : 1111 1001 1011 1000. Добавим единицу: 1111 1001 1011 1001 — это и есть внутреннее двоичное представление числа -1607.
Формат с плавающей точкой использует представление вещественного числа R в виде произведения мантиссы m на основание системы счисления n в некоторой целой степени p, которую называют порядком: R = m * n p .
Представление числа в форме с плавающей точкой неоднозначно. Например, справедливы следующие равенства:
12.345 = 0.0012345 x 10 4 = 1234.5 x 10 -2 = 0.12345 x 10 2
Чаще всего в ЭВМ используют нормализованное представление числа в форме с плавающей точкой. Мантисса в таком представлении должна удовлетворять условию: 0.1p мантисса меньше 1 и первая значащая цифра — не ноль (p — основание системы счисления).
В памяти компьютера мантисса представляется как целое число, содержащее только значащие цифры (0 целых и запятая не хранятся), так для числа 12.345 в ячейке памяти, отведенной для хранения мантиссы, будет сохранено число 12345. Для однозначного восстановления исходного числа остается сохранить только его порядок, в данном примере — это 2.
Кодирование текста
Множество символов, используемых при записи текста, называется алфавитом. Количество символов в алфавите называется его мощностью.
Для представления текстовой информации в компьютере чаще всего используется алфавит мощностью 256 символов. Один символ из такого алфавита несет 8 бит информации, т. к. 2 8 = 256. Но 8 бит составляют один байт, следовательно, двоичный код каждого символа занимает 1 байт памяти ЭВМ.
Все символы такого алфавита пронумерованы от 0 до 255, а каждому номеру соответствует 8-разрядный двоичный код от 00000000 до 11111111. Этот код является порядковым номером символа в двоичной системе счисления .
Для разных типов ЭВМ и операционных систем используются различные таблицы кодировки, отличающиеся порядком размещения символов алфавита в кодовой таблице. Международным стандартом на персональных компьютерах является уже упоминавшаяся таблица кодировки ASCII.
Принцип последовательного кодирования алфавита заключается в том, что в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений.
Стандартными в этой таблице являются только первые 128 символов, т. е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная со 128 (двоичный код 10000000) и кончая 255 (11111111), используются для кодировки букв национальных алфавитов, символов псевдографики и научных символов. О кодировании символов русского алфавита рассказывается в главе «Обработка документов».
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части — растровую и векторную графику .
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element ). Код пиксела содержит информацию о его цвете.
Для черно-белого изображения (без полутонов) пиксел может принимать только два значения: белый и черный (светится — не светится), а для его кодирования достаточно одного бита памяти: 1 — белый, 0 — черный.
Пиксел на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксел недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксел, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 — черный, 10 — зеленый, 01 — красный, 11 — коричневый.
На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов — красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций:
| R | G | B | цвет |
|---|---|---|---|
| 0 | 0 | 0 | черный |
| 0 | 0 | 1 | синий |
| 0 | 1 | 0 | зеленый |
| 0 | 1 | 1 | голубой |
| R | G | B | цвет |
|---|---|---|---|
| 1 | 0 | 0 | красный |
| 1 | 0 | 1 | розовый |
| 1 | 1 | 0 | коричневый |
| 1 | 1 | 1 | белый |
Разумеется, если иметь возможность управлять интенсивностью (яркостью) свечения базовых цветов, то количество различных вариантов их сочетаний, порождающих разнообразные оттенки, увеличивается. Количество различных цветов — К и количество битов для их кодировки — N связаны между собой простой формулой: 2 N = К.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения — линия, прямоугольник, окружность или фрагмент текста — располагается в своем собственном слое, пикселы которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т. д.). Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличии от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость). Подробнее о графических форматах рассказывается в разделе «Графика на компьютере».
Кодирование звука
Из курса физики вам известно, что звук — это колебания воздуха. Если преобразовать звук в электрический сигнал (например, с помощью микрофона), мы увидим плавно изменяющееся с течением времени напряжение. Для компьютерной обработки такой — аналоговый — сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел.
Поступим следующим образом. Будем измерять напряжение через равные промежутки времени и записывать полученные значения в память компьютера . Этот процесс называется дискретизацией (или оцифровкой), а устройство, выполняющее его — аналого-цифровым преобразователем (АЦП).
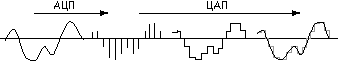
Для того чтобы воспроизвести закодированный таким образом звук, нужно выполнить обратное преобразование (для него служит цифро-аналоговый преобразователь — ЦАП ), а затем сгладить получившийся ступенчатый сигнал.
Чем выше частота дискретизации (т. е. количество отсчетов за секунду) и чем больше разрядов отводится для каждого отсчета, тем точнее будет представлен звук. Но при этом увеличивается и размер звукового файла. Поэтому в зависимости от характера звука, требований, предъявляемых к его качеству и объему занимаемой памяти, выбирают некоторые компромиссные значения.
Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Человек издавна использует довольно компактный способ представления музыки — нотную запись. В ней специальными символами указывается, какой высоты звук, на каком инструменте и как сыграть. Фактически, ее можно считать алгоритмом для музыканта, записанным на особом формальном языке . В 1983 г. ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI .
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и неоспоримые преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI -редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии.
Заметим, что существуют и другие, чисто компьютерные, форматы записи музыки. Среди них следует отметить формат MP3, позволяющий с очень большим качеством и степенью сжатия кодировать музыку. При этом вместо 18-20 музыкальных композиций на стандартный компакт-диск (CDROM) помещается около 200. Одна песня занимает примерно 3,5 Mb, что позволяет пользователям сети Интернет легко обмениваться музыкальными композициями.
Источник



