
- Автоматизация типовых процессов, правильный выбор реализации
- Структура
- Начальная проблема и причины начала работы
- Какие есть варианты попроще и чем они не нравятся
- Что и как сделано
- Результат
- Первые шаги к автоматизации бизнеса. С чего начать?
- Шаг 1. Бизнес-процессы
- Шаг 2. Таблицы
- Шаг 3. Доступ
- Шаг 4. Шаблоны
- Шаг 5. Рассылки
- Шаг 6. Напоминания
- Шаг 7. Вычисления
- Шаг 8. Отчеты
Автоматизация типовых процессов, правильный выбор реализации
В процессе написания мелких сервисов и программ для автоматизации однотипных действий операторов или взаимодействия нескольких систем вне их сферы действий я столкнулся с тем, что множество мелкого кода очень трудно поддерживать, а рост репозиториев, описаний становится неконтролируемым. Я решил написать, к каким выводам и на основе чего я пришел в процессе разработки оптимального решения для такой ситуации.
Структура
Начальная проблема и причины начала работы
Какие есть варианты попроще и чем они не нравятся
Что и как сделано
Результат
Начальная проблема и причины начала работы
О школе у меня осталось много воспоминаний, со временем они все стали хорошими, одну историю я часто вспоминаю с улыбкой:
Средние классы школы, учительница по математике пытается проанализировать контрольные работы и объяснить свое нежелание ставить пятерку отличницам, которые превратили решение математической задачи в сочинение на тему, как эта задача решалась. Поняв, что объяснения до детей не доходят, она взяла мою тетрадь и продемонстрировала со словами, которые я решил считать похвалой: «Я очень люблю его работы проверять. Это настолько ленивый человек, что любая лишняя или нематематическая запись у него никогда не будет написана. Всегда использует сокращения и ленится писать слова, если есть совпадающие с ними по смыслу символы». Кстати, несмотря на похвалу, я тоже пятерку тогда не получил.
Думаю, что здоровая лень – это положительное качество. Код, в котором его автор поленился писать однотипные вызовы и оформил его один раз в процедуре, давно стал признаком качества написания. Ну а функционал различных систем, который на 90% делает одно и то же, у меня вызывает вопрос – «не лень же было столько копипастить?».
Хочу на примере показать, что иногда асинхронно проще проходит реализация снаружи, чем внутри систем. Два разработчика базы данных (БД) MSSQL и Oracle в процессе разработки сложного бизнес-процесса столкнулись с необходимостью обмена файлами между своими системами. На этапе разработки у них отлично пошел обмен в расшаренной папке, которая смонтирована к обоим серверам БД и доступна для обращения. При тестировании увеличилась нагрузка на обмен файлами и появилась на регулярной основе EXCEPTION о занятом другим модулем файле. Поскольку менять весь бизнес-процесс уже накладно по трудозатратам, то обмен стал обрастать условиями и сложностями – разделили направления обмена на несколько каталогов. Добавили транзакционность в обмен – формировали пустые файлы .lock для монопольного доступа к каталогам и проверяли их наличие. Когда заработало все более или менее стабильно, по их работе прошелся бич безопасности, выявив дыры в этой самой безопасности, и им быстренько (обычно в такой момент время не ждет – все, как у Джека Лондона) написали в модной микросервисной архитектуре службу обмена файлами. При рассмотрении поближе этот микросервис оказался по сути тем, что раньше называлось толстым клиентом, – в одной сессии открывается SELECT с достаточно жесткой WHERE-частью и забирается бинарник файла, в другой сессии происходит INSERT забранных бинарников в таблицу в цикле. Все заработало, все службы довольны.
Потом приносящий прибыль бизнес-процесс продублировали, и не один раз. И в конце примера пришла пора исправлений существующих микросервисов: то ли поле добавлено в INSERT, то ли WHERE-часть усложнилась в SELECT – в общем, надо менять код программ. И делать это надо ответственному за эти функционалы программисту. Тут здоровая лень и просыпается – кажется бессмысленным компилить однотипные изменения в n-проектах, если n>1. А ведь есть еще понимание, что поддержка таких изменений будет производиться на достаточно регулярной основе. Появилось желание пересмотреть подход к организации подобных обменов. Как я это делал, напишу ниже.
Какие есть варианты попроще и чем они не нравятся
Сейчас есть такой модный тренд – роботизация. Я столкнулся с использованием робота в автоматизировании передачи данных из одной системы в другую. Выглядит это так: поднимается виртуалка с установленными на ней необходимыми программами, в данном случае клиентская часть модуля и Excel, робот по сути – это кликер на определенные части экрана, где есть кнопки управления в клиенте или в Excel (имитирует нажатие этих кнопок человеком). В виртуалке возникли сложности с имитацией среды выполнения макросов в шаблоне Excel, заработало на 90% без некоторых отработок, возникла необходимость повесить еще службу для этих отработок, чтобы полноценно имитировать функционал. Это решение имеет неприятные минусы. Для настройки одного макроса кликера нужно провести довольно кропотливую и трудоемкую работу (для настройки виртуалки под требуемую задачу). Обязательно всплывают нюансы, на которые уйдет время и, возможно, ресурсы разработки. Полная зависимость от версий используемых программ, изменения интерфейса рушат весь механизм имитации. Разработчик макросов должен иметь компетенции в используемых модулях программ. Это постоянная работа (не для ленивого человека) по исправлению макросов, количество которых будет расти. На память из юности приходят кликеры игрушек ММОРПГ – производитель такого кликера всегда хочет получать деньги за каждую сессию кликера, – в нашем случае зарплату оператора системы. Сложно и недостаточно надежно, придется сверху отдельный мониторинг еще прикрутить по каждому процессу. Думаю, этот подход применим к старым системам, неизменяемым годами. Новые лучше обслуживать более простыми способами.
И еще один момент, который не нравится в различных вариантах автоматизации процессов внутри системы, – ограничение на работу только доступными данными внутри системы. Для того чтобы организовать выборку данных по внешним ключам, обязательно нужно дорабатывать АПИ обмена какой-нибудь, или список фильтров организовывать, или еще какой сложный процесс, который не покроет следующую выборку и его надо будет опять дорабатывать в коде.
Что и как сделано
Для себя я выделил такие особенности, которые хочу видеть в системе автоматизации:
должен быть набор инструментов для выполнения требуемых операций;
должен быть механизм настройки, понятный и сразу воспринимаемый другими разработчиками;
Чтобы создать набор инструментов, я взял все простые операции, которые выполнялись при функционировании автоматизируемых бизнес-процессов, и сгруппировал их по используемым библиотекам. У меня получились на тот момент такие группы:
Работа с файлами (удаление, копирование, перенос, перевод в BASE64 и т. п.);
Чтение/запись данных из Excel, включая CSV и т. п. Здесь в группу попали все операции, которые можно выполнить библиотекой NPOI (Apache POI);
Работа с JPG и PDF, тут пришлось сделать специфическую DLL под индивидуальные запросы, пример: на все графические файлы поставить печать и объединить в PDF;
Выполнение анонимного блока для Oracle;
Выполнение анонимного блока для MSSQL;
Использование библиотеки WinSCP (SFTP, FTP, WebDAV, S3 and SCP client);
Использование библиотеки RabbitMQ, у нас эта очередь популярна;
Работа с почтовыми серверами;
Использование CRYPTO PRO.
У меня напрашивались отдельные модули с классами, имеющими общий интерфейс для запуска обработки, который принимает список входных параметров (имя, значение) из нескольких строк и отдает результат работы в виде такого же списка выходных параметров:
Ну и интерфейс логирования. Как видите, в него тоже добавил при реализации.
Необходимо быстрое наращивание функциональных возможностей. Тут самым простым видится поиск плагинов в каталоге службы при запуске. Прошли по DLL, нашли те, которые поддерживают интерфейс обмена, зарегистрировали для использования, несколько строк по сути при старте службы:
После реализации классов я получил набор необходимых мне инструментов для выполнения операций.
Хранение настроек проблем не вызвало. Таблица процессов (дальше я их буду называть конвейерами), таблица асинхронных вызовов того или иного класса (их буду называть тасками) и таблица связи между тасками одного конвейера. Также нужна таблица для хранения текущих значений входных и выходных параметров тасков и статус их выполнения.
В результате у меня получилась структура настроечных таблиц, позволяющая создать граф выполнения процесса. Вот пример из мониторинга системы, который тоже написан; он, конечно, обязателен, но о нем писать в этой статье излишне.
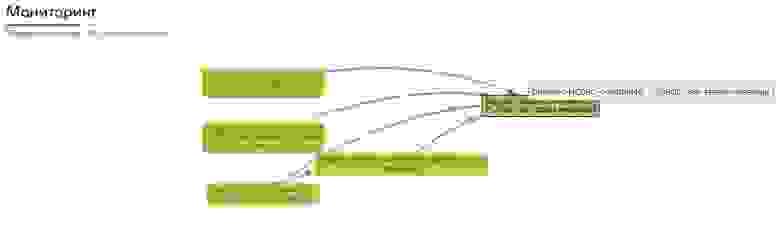
Посложнее, с долгой обработкой, на рисунке видны уже пройденные узлы (зеленые), текущее выполнение(желтые) и очередь на выполнение (серые)

Теперь мы подошли к той части, которая определит, как часто необходимо вмешательство разработчика для внесения изменений в логику работы. Напомню, хочется пойти на поводу у лени и не вмешиваться вообще, отдав в эксплуатацию инструмент, и развивать этот инструмент, не вдаваясь в проблемы «индейцев». Это можно сделать, если формирование входных данных – известный всем механизм. Поскольку используемая БД – Oracle, то механизм формирования входных данных – это запрос на PL/SQL.
Полностью на PL/SQL будут запросы для сбора данных, которым не нужны результаты работы предыдущих тасков. Например, поиск файлов в каталоге ‘C:\dir_name\’:
Когда возникает потребность в результатах работы предыдущих тасков, их надо как-то обозначить в запросе, я ввел одно макроопределение #XMLTABLE, оно при анализе запроса заменяется на подзапрос из всех результатов работы тасков (стрелочка с направлением передачи параметров на рисунках), я подробнее об этом напишу ниже. Вот как выглядят два запроса для последовательно идущих тасков, их результат – поиск в папке SFTP-файлов и перенос их в локальную шару. Поля в запросе – это параметры соединения SFTP и пути каталогов, таск их умеет обрабатывать.
Получение списка файлов:
Перенос файлов в каталог ‘C:\dir_name\’, при условии код ошибки = 0 и файл не содержит расширение ‘filepart’, т. е. он закачан полностью:
Как видите, запросы прозрачны, просты и позволяют в них быстро ориентироваться при внесении изменений.
Общая последовательность формирования входных данных такая:
Проверяются все узлы графа конвейера, и находятся те, что еще не отработали, но уже имеют отработанные таски по всем связям на входе таска;
Если есть макроопределение #XMLTABLE, то начинается работа генератора подзапроса;
Сформированный запрос готов к запуску. Каждый таск имеет необязательный параметр ‘ConnectionString’. Если он не заполнен, то запуск осуществляется в текущей служебной сессии, иначе в сессии по значению параметра;
Открыть курсор из строки и сериализовать его в строку XML в Oracle можно несколькими строчками, сделано так для того, чтобы пустые поля все равно присутствовали в XML:
Перед вызовом таска строка с XML десериализуется в объект
и передается в таск.
Еще несколько слов о генерации строки с #XMLTABLE. Я добавил к каждому таску признак динамического формирования количества входных параметров. Если он не заполнен, то из всего набора данных в XML интересуют при генерации подзапроса только поля, которые зарегистрированы входными параметрами у таска (если помните, все DLL регистрируются при каждом запуске службы, в параметры регистрации входят уникальный ID, строка соединения с БД, если нужно это соединение, набор описаний входных и выходных параметров). Если признак заполнен, то приходится опросить всю XML, вытащить все используемые поля и включить их во входные параметры – для больших XML это не быстро.
Результат
После всех изысканий и разработки мы получили такую систему автоматизации бизнес-процессов:
Нет ограничений по функционалу, недостающие операции добавляются в существующий плагин, или пишется новый плагин с новой группой операций – простая и нетрудоемкая работа, которую можно поручить даже студенту;
Простота поддержки – проблемные места выявляются в отдельном черном ящике и быстро исправляются;
Простота и однотипность создания новых бизнес-процессов, без требований к новым областям знаний: создание графа и написание к каждому узлу SELECT с необходимыми входными параметрами;
Сняты ограничения по доступности данных на разных узлах системы: например, мы можем сделать выборку из таблицы MSSQL на основе справочника из БД Oracle и имен файлов в каталоге SFTP;
Отдельный результат – написание этой статьи. 🙂
Все результаты, прошедшие через мои руки, несут огромную помощь коллег, которым хочется сказать спасибо за умные советы и качественный код.
P. S. Хочу закончить статью шуткой, не моей, а разработчиков Oracle, с которой столкнулся при тестовых парсингах XML и JSON:
Два запроса простейших, первый «летает», второй «ложится»; судя по форумам, это полечили в последнем патче Oracle. Но подозреваю, что столько нам открытий чудных готовят соединения в запросах XMLTABLE и JSON_TABLE:
Источник
Первые шаги к автоматизации бизнеса. С чего начать?

Введение
Шаг 1. Бизнес-процессы
Советы:
В первую очередь нужно автоматизировать проблемные участки, задерживающие работу всей организации.
Для каждого процесса следует определить ответственных за него сотрудников и контролирующего. Проблему можно решить быстрее, если точно знать, кто отвечает за дело на каждом этапе.
Выстраивать процессы лучше так, чтобы все данные и сроки от начала проекта и до его завершения передавались между участниками автоматически.
Шаг 2. Таблицы
Советы:
Очень важно следить за своевременным наполнением базы – не внесенная вовремя информация может оказаться необходимой, когда другие источники не будут доступны.
Не стоит составлять таблицы сразу на все случаи жизни. Лучше начать с самых важных, протестировать их, отшлифовать и только потом добавить следующие.
Следует использовать связанные поля. Так данные из одной таблицы не придется дублировать в другую: связанные поля будут заполняться автоматически. Например, список клиентов можно будет составить один раз в одной таблице – во всех остальных поля, которым такие данные нужны, заполнятся без дополнительных усилий.
Шаг 3. Доступ
Советы:
Для каждой группы нужно составить список полей под просмотр и редактирование. Все остальное по умолчанию будет закрыто.
Кроме доступа к полям, надо продумать доступ к добавлению или удалению записей, экспорту или импорту данных, доступу к отчетам.
Шаг 4. Шаблоны
Советы:
Шаблоны нужно сделать как можно более гибкими, оставив неизменяемым только основной текст. Остальная информация будет подставляться автоматически. Это избавит сотрудников от «бумажной волокиты», а сами документы – от ошибок и опечаток.
Часто в шаблон бывает необходимо подставить данные, которые не были учтены в таблице до этого. Для них всегда можно будет добавить новые поля.
Даже самый сложный договор можно привести к единому шаблону, просто добавив в него различные условия. Поэтому несколько похожих договоров удобнее будет свести в один.
Шаг 5. Рассылки
Советы:
Главная информация должна содержаться в самом тексте. Не нужно перегружать шаблон картинками и тяжелыми файлами. Большинство пользователей предпочитают отключать дополнения, а значит, для них суть письма останется неясной. Далеко не каждый сочтет это интригующим – скорее, просто закроет его и не воспользуется предложением.
При массовости рассылок стоит задуматься о спам-листах. Чтобы не попасть в них, нужно обратить внимание на возможность клиента отписаться от рассылки по собственному желанию. При этом опция должна быть очевидной – например, в виде обозначенной ссылки в письме.
Также при планировании рассылки нужно учитывать ограничение сервера на количество отсылаемых писем в час (на бесплатных серверах – в минуту). Как правило, после достижения максимального количества писем сервер блокирует аккаунт. Чтобы избежать подобной ситуации, рассылку лучше распределить на несколько циклов.
Не стоит проводить рассылки слишком часто и без особого повода. Во-первых, это раздражает подписчиков, во-вторых, вряд ли кого-то заинтересуют малоинформативные письма. Если есть уверенность в планировании, можно предупредить о частоте рассылок еще на этапе подписки – например, фразой «Наша еженедельная рассылка».
Шаг 6. Напоминания
Советы:
Напоминания должны быть информативными, чтобы с первого взгляда было понятно, о чем идет речь. Поэтому нужно указывать больше конкретной информации внутри текста. Согласитесь, есть разница между «Изменился статус заказа» и «Статус заказа № XX изменился с A на B».
Отправлять напоминания следует только в случае необходимости. Не стоит создавать напоминания на маловажные изменения или рассылать их тем, кого они не касаются. Сотрудники просто «утонут» в них и перестанут реагировать вовремя.
Шаг 7. Вычисления
Советы:
В первую очередь в систему автоматизации можно перенести те вычисления, которые уже хранились до этого в Excel или других программах.
Будет удобнее начать с простых вычислений, усложняя их по мере освоения системы автоматизации.
Необходимые для вычислений данные можно брать не только из текущей таблицы, но и из связанных с ней. Для этого нужно не забывать проставлять необходимые связи.
Шаг 8. Отчеты
Советы:
Нужно определить параметры, которые можно будет изменять при формировании отчета – например, по периоду или по группам сотрудников.
Не стоит перегружать моментально составляемые отчеты сложной информацией. Основная их задача – быстрое ознакомление с текущей ситуацией для незамедлительного реагирования на возможные затруднения.
Можно сделать отчеты простыми для восприятия. Например, визуализировать их с помощью различных графиков и схем.
Источник



