
- Дерево
- Способы обхода дерева
- Реализация дерева
- Добавление узлов в дерево
- Удаление поддерева
- Обход двоичного дерева
- Обход дерева в глубину
- Обход в ширину
- Обход бесконечных деревьев
- Обход двоичного дерева на Python
- Что такое двоичное дерево?
- Строим двоичное дерево на Python
- Обход двоичного дерева
- Pre-Order
- Post-Order
- In-Order
Дерево
Дерево – структура данных, представляющая собой древовидную структуру в виде набора связанных узлов.
Бинарное дерево — это конечное множество элементов, которое либо пусто, либо содержит элемент ( корень ), связанный с двумя различными бинарными деревьями, называемыми левым и правым поддеревьями . Каждый элемент бинарного дерева называется узлом . Связи между узлами дерева называются его ветвями .
Способ представления бинарного дерева: 
- A — корень дерева
- В — корень левого поддерева
- С — корень правого поддерева
Корень дерева расположен на уровне с минимальным значением.
Узел D , который находится непосредственно под узлом B , называется потомком B . Если D находится на уровне i , то B – на уровне i-1 . Узел B называется предком D .
Максимальный уровень какого-либо элемента дерева называется его глубиной или высотой .
Если элемент не имеет потомков, он называется листом или терминальным узлом дерева.
Остальные элементы – внутренние узлы (узлы ветвления).
Число потомков внутреннего узла называется его степенью . Максимальная степень всех узлов есть степень дерева.
Число ветвей, которое нужно пройти от корня к узлу x , называется длиной пути к x . Корень имеет длину пути равную 0 ; узел на уровне i имеет длину пути равную i .
Бинарное дерево применяется в тех случаях, когда в каждой точке вычислительного процесса должно быть принято одно из двух возможных решений.
Имеется много задач, которые можно выполнять на дереве.
Распространенная задача — выполнение заданной операции p с каждым элементом дерева. Здесь p рассматривается как параметр более общей задачи посещения всех узлов или задачи обхода дерева.
Если рассматривать задачу как единый последовательный процесс, то отдельные узлы посещаются в определенном порядке и могут считаться расположенными линейно.
Способы обхода дерева
Пусть имеем дерево, где A — корень, B и C — левое и правое поддеревья.

Существует три способа обхода дерева:
- Обход дерева сверху вниз (в прямом порядке): A, B, C — префиксная форма.
- Обход дерева в симметричном порядке (слева направо): B, A, C — инфиксная форма.
- Обход дерева в обратном порядке (снизу вверх): B, C, A — постфиксная форма.
Реализация дерева
Узел дерева можно описать как структуру:
При этом обход дерева в префиксной форме будет иметь вид
Обход дерева в инфиксной форме будет иметь вид
Обход дерева в постфиксной форме будет иметь вид
Бинарное (двоичное) дерево поиска – это бинарное дерево, для которого выполняются следующие дополнительные условия (свойства дерева поиска):
- оба поддерева – левое и правое, являются двоичными деревьями поиска;
- у всех узлов левого поддерева произвольного узла X значения ключей данных меньше, чем значение ключа данных самого узла X ;
- у всех узлов правого поддерева произвольного узла X значения ключей данных не меньше, чем значение ключа данных узла X .
Данные в каждом узле должны обладать ключами, на которых определена операция сравнения меньше.
Как правило, информация, представляющая каждый узел, является записью, а не единственным полем данных.
Для составления бинарного дерева поиска рассмотрим функцию добавления узла в дерево.
Добавление узлов в дерево
Удаление поддерева
Пример Написать программу, подсчитывающую частоту встречаемости слов входного потока.
Поскольку список слов заранее не известен, мы не можем предварительно упорядочить его. Неразумно пользоваться линейным поиском каждого полученного слова, чтобы определять, встречалось оно ранее или нет, т.к. в этом случае программа работает слишком медленно.
Один из способов — постоянно поддерживать упорядоченность уже полученных слов, помещая каждое новое слово в такое место, чтобы не нарушалась имеющаяся упорядоченность. Воспользуемся бинарным деревом.
В дереве каждый узел содержит:
- указатель на текст слова;
- счетчик числа встречаемости;
- указатель на левого потомка;
- указатель на правого потомка.
Рассмотрим выполнение программы на примере фразы
now is the time for all good men to come to the aid of their party
При этом дерево будет иметь следующий вид 
Результат выполнения 
Источник
Обход двоичного дерева
Обход дерева в глубину
В отличие от линейных структур типа односвязного списка и массива, у которых есть каноничный, прямой способ обхода, деревья можно обходить несколькими способами, в зависимости от поставленной задачи. Начиная с корня, можно применять необходимое действия (именуемое в дальнейшем «визит») как к самому узлу, так и к его левой или правой ветви. Порядок, в котором операции применяются, и будет определять способ обхода.
Наиболее простыми и понятными являются рекурсивные алгоритмы. При сведении к итеративному алгоритму, так как дерево предполагает несколько путей обхода, часть узлов придётся «откладывать» для дальнейшей обработки, для чего будут использоваться стек или очередь.
Существует три основных способа обхода в глубину.
- Прямой (pre-order)
Посетить корень
Обойти левое поддерево
Обойти правое поддерево
Рекурсивное решение полностью соответствует описанию алгоритма
Переделаем функции, чтобы они могли работать с узлами. Для этого понадобится передавать функцию, которая могла бы работать с узлом и получать дополнительные параметры. Эти параметры будут передаваться указателем типа void. Если нам понадобится передать параметры, всегда можно будет их передать указателем на структуру.
В качестве функции visit можно передавать, например, такую функцию
Рассмотрим теперь результат каждого из обходов.
inOrderTraversal выводит сначала самый левый узел, потом средний, потом правый. Если слева находилось дерево, то алгоритм применяется к нему рекурсивно. Если мы обрабатываем двоичное дерево поиска, то самым левым будет самый маленький элемент, самым правым и самым последним при обработке будет самый большой элемент. Симметричный обход выведет дерево в отсортированном по возрастанию виде. Для того, чтобы отсортировать дерево в обратном порядке, нужно сначала обработать правую ветвь, то есть функция
выведет дерево в обратном порядке.
postOrderTraversal выводит узлы слева направо, снизу вверх. Это имеет ряд применений, сейчас рассмотрим только одно – удаление дерева. Обход дерева начинается снизу, с узлов, у которых нет родителей. Их можно безболезненно удалять, так как обращение root->left и root->right происходят до удаления объекта.
Напомню, что если мы хотим изменить указатель, то нужно передавать указатель на указатель.
Итеративная реализация обхода в глубину требует использования стека. Он нужен для того, чтобы «откладывать» на потом обработку некоторых узлов (например тех, у кого есть необработанные наследники, или всех левых улов и т.д.).
Реализовывать стек будем с помощью массива, который при переполнении будет изменять свой размер. Напомню, что реализация стека требует двух функций — push, которая кладёт значение на вершину стека и pop, которая снимает значение с вершины стека и возвращает его. Кроме того, будем использовать функцию peek, которая возвращает значение с вершины, но не удаляет его.
После того, как у нас готова реализация стека, напишем обходы.
Обход в ширину
О бход в ширину подразумевает, что сначала мы посещаем корень, затем, слева направо, все ветви первого уровня, затем все ветви второго уровня и т.д.
Пусть мы находимся в корне дерева. Далее необходимо посетить всех наследников корня. Таким образом, нужно засунуть в контейнер сначала узел, затем его наследников, при этом узел далее должен быть обработан первым. То есть, элемент, который вошёл первым должен быть обработан первым. Это очередь, и в этом примере мы будем использовать готовую реализацию очереди с помощью двусвязного списка.
Реализация на си
Заменим очередь на стек
Теперь функция обходит узлы как Post-Order, только задом наперёд.
Обход бесконечных деревьев
Б ывают ситуации, когда необходимо обработать бесконечное дерево. Дерево может генерироваться, когда мы обращаемся к нему (например, мы обходим сайт, страницы которого генерируются сервером во время обращения), либо его размер просто не известен (и возможно велик).
Если дерево растёт бесконечно в глубину, то его можно обрабатывать, используя проход в ширину. То есть, известно, что если спускаться вниз по ветви, то до конца мы не дойдём, но на данном уровне дерево имеет конечный размер.
Если дерево растёт бесконечно в ширину, но при этом имеет конечную глубину (то есть, у узла не два наследника, а из бесконечно много), то можно использовать поиск в глубину.
Обработку бесконечного дерева можно заканчивать например, когда обработано достаточно большое количество узлов или их значения достигли какой-то величины.
Пусть робот «шмугл» индексирует страницы на сайте. Количество ссылок на странице конечно. (т.к. страница конечна). То есть можно рассматривать страницы как узел, ссылки с которой ведут к другим узлам. Конечно, есть ссылки, которые ведут на предыдущие страницы, есть кросс-ссылки между страницами на одном уровне вложенности и т.д., сейчас всех тонкостей рассматривать не будем. То есть, есть дерево, у каждого узла которого конечное число наследников. В лучшем случае количество ссылок конечно и охватывает весь сайт. Однако, может попасться страница, на которой есть календарь, ссылки с которого генерируются автоматически. Программист забыл, что ссылки в будущее надо запретить, поэтому в глубину мы получаем бесконечно дерево, каждый новый узел которого генерируется автоматически. Обход этого дерева закончится, например, когда будет забит канал или превышен лимит по ссылкам.
Источник
Обход двоичного дерева на Python
Да, двоичные деревья — не самая любимая тема программистов. Это одна из тех старых концепций, о целесообразности изучения которых постоянно ведутся споры. В работе вам довольно редко придется реализовывать двоичные деревья и обходить их, так зачем же уделять им так много внимания на технических собеседованиях?
Сегодня мы не будем переворачивать двоичное дерево (ффухх!), но рассмотрим пару методов его обхода. К концу статьи вы поймете, что двоичные деревья не так страшны, как кажется.
Что такое двоичное дерево?
Недавно мы разбирали реализацию связных списков на Python. Каждый такой список состоит из некоторого количества узлов, указывающих на другие узлы. А если бы узел мог указывать не на один другой узел, а на большее их число? Вот это и есть деревья. В них каждый родительский узел может иметь несколько узлов-потомков. Если у каждого узла максимум два узла-потомка (левый и правый), такое дерево называется двоичным (бинарным).
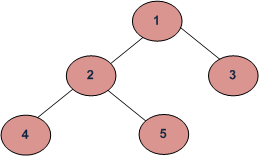
В приведенном выше примере «корень» дерева, т. е. самый верхний узел, имеет значение 1. Его потомки — 2 и 3. Узлы 3, 4 и 5 называют «листьями»: у них нет узлов-потомков.
Строим двоичное дерево на Python
Как построить дерево на Python? Реализация будет похожей на наш класс Node в реализации связного списка. В этом случае мы назовем класс TreeNode .
Определим метод __init__() . Как всегда, он принимает self . Также мы передаем в него значение, которое будет храниться в узле.
Установим значение узла, а затем определим левый и правый указатель (для начала поставим им значение None ).
И… все! Что, думали, что деревья куда сложнее? Если речь идет о двоичном дереве, единственное, что его отличает от связного списка, это то, что вместо next у нас тут есть left и right .
Давайте построим дерево, которое изображено на схеме в начале статьи. Верхний узел имеет значение 1. Далее мы устанавливаем левые и правые узлы, пока не получим желаемое дерево.
Обход двоичного дерева
Итак, вы построили дерево и теперь вам, вероятно, любопытно, как же его увидеть. Нет никакой команды, которая позволила бы вывести на экран дерево целиком, тем не менее мы можем обойти его, посетив каждый узел. Но в каком порядке выводить узлы?
Самые простые в реализации обходы дерева — прямой (Pre-Order), обратный (Post-Order) и центрированный (In-Order). Вы также можете услышать такие термины, как поиск в ширину и поиск в глубину, но их реализация сложнее, ее мы рассмотрим как-нибудь потом.
Итак, что из себя представляют три варианта обхода, указанные выше? Давайте еще раз посмотрим на наше дерево.
При прямом обходе мы посещаем родительские узлы до посещения узлов-потомков. В случае с нашим деревом мы будем обходить узлы в таком порядке: 1, 2, 4, 5, 3.
Обратный обход двоичного дерева — это когда вы сначала посещаете узлы-потомки, а затем — их родительские узлы. В нашем случае порядок посещения узлов при обратном обходе будет таким: 4, 5, 2, 3, 1.
При центрированном обходе мы посещаем все узлы слева направо. Центрированный обход нашего дерева — это посещение узлов 4, 2, 5, 1, 3.
Давайте напишем методы обхода для нашего двоичного дерева.
Pre-Order
Начнем с определения метода pre_order() . Наш метод принимает один аргумент — корневой узел (расположенный выше всех).
Дальше нам нужно проверить, существует ли этот узел. Вы можете возразить, что лучше бы проверить существование потомков этого узла перед их посещением. Но для этого нам пришлось бы написать два if-предложения, а так мы обойдемся одним.
Написать обход просто. Прямой обход — это посещение родительского узла, а затем каждого из его потомков. Мы «посетим» родительский узел, выведя его на экран, а затем «обойдем» детей, вызывая этот метод рекурсивно для каждого узла-потомка.
Просто, правда? Можем протестировать этот код, совершив обход построенного ранее дерева.
Post-Order
Переходим к обратному обходу. Возможно, вы думаете, что для этого нужно написать еще один метод, но на самом деле нам нужно изменить всего одну строчку в предыдущем.
Вместо «посещения» родительского узла и последующего «обхода» детей, мы сначала «обойдем» детей, а затем «посетим» родительский узел. То есть, мы просто передвинем print на последнюю строку! Не забудьте поменять имя метода на post_order() во всех вызовах.
В выводе мы получим:
Каждый узел-потомок посещен до посещения его родителя.
In-Order
Наконец, напишем метод центрированного обхода. Как нам обойти левый узел, затем родительский, а затем правый? Опять же, нужно переместить предложение print!
Вот и все, мы рассмотрели три простейших способа совершить обход двоичного дерева.
Источник



