
- Как найти дисперсию?
- Формула дисперсии случайной величины
- Пример нахождения дисперсии
- Вычисление дисперсии онлайн
- Видео. Полезные ссылки
- Видеоролики: что такое дисперсия и как найти дисперсию
- Полезные ссылки
- 5. Размах вариации. Среднее линейное отклонение. Генеральная и выборочная дисперсия
- Размах вариации
- среднее линейное отклонение
- Генеральная и выборочная дисперсия
Как найти дисперсию?
Дисперсия — это мера разброса значений случайной величины $X$ относительно ее математического ожидания $M(X)$ (см. как найти математическое ожидание случайной величины). Дисперсия показывает, насколько в среднем значения сосредоточены, сгруппированы около $M(X)$: если дисперсия маленькая — значения сравнительно близки друг к другу, если большая — далеки друг от друга (см. примеры нахождения дисперсии ниже).
Если случайная величина описывает физические объекты с некоторой размерностью (метры, секунды, килограммы и т.п.), то дисперсия будет выражаться в квадратных единицах (метры в квадрате, секунды в квадрате и т.п.). Ясно, что это не совсем удобно для анализа, поэтому часто вычисляют также корень из дисперсии — среднеквадратическое отклонение $\sigma(X)=\sqrt
Еще одно формальное определение дисперсии звучит так: «Дисперсия — это второй центральный момент случайной величины» (напомним, что первый начальный момент — это как раз математическое ожидание).
Формула дисперсии случайной величины
Дисперсия случайной величины Х вычисляется по следующей формуле: $$ D(X)=M(X-M(X))^2, $$ которую также часто записывают в более удобном для расчетов виде: $$ D(X)=M(X^2)-(M(X))^2. $$
Эта универсальная формула для дисперсии может быть расписана более подробно для двух случаев.
Если мы имеем дело с дискретной случайной величиной (которая задана перечнем значений $x_i$ и соответствующих вероятностей $p_i$), то формула принимает вид: $$ D(X)=\sum_
Пример нахождения дисперсии
Рассмотрим простые примеры, показывающие как найти дисперсию по формулам, введеным выше.
Пример 1. Вычислить и сравнить дисперсию двух законов распределения: $$ x_i \quad 1 \quad 2 \\ p_i \quad 0.5 \quad 0.5 $$ и $$ y_i \quad -10 \quad 10 \\ p_i \quad 0.5 \quad 0.5 $$
Для убедительности и наглядности расчетов мы взяли простые распределения с двумя значениями и одинаковыми вероятностями. Но в первом случае значения случайной величины расположены рядом (1 и 2), а во втором — дальше друг от друга (-10 и 10). А теперь посмотрим, насколько различаются дисперсии: $$ D(X)=\sum_
Ясно, что для более сложных распределений, где число значений больше и вероятности не одинаковы, картина будет более сложной, прямой зависимости от значений уже не будет (но будет как раз оценка разброса).
Пример 2. Найти дисперсию случайной величины Х, заданной дискретным рядом распределения: $$ x_i \quad -1 \quad 2 \quad 5 \quad 10 \quad 20 \\ p_i \quad 0.1 \quad 0.2 \quad 0.3 \quad 0.3 \quad 0.1 $$
Снова используем формулу для дисперсии дискретной случайной величины: $$ D(X)=M(X^2)-(M(X))^2. $$ В случае, когда значений много, удобно разбить вычисления по шагам. Сначала найдем математическое ожидание: $$ M(X)=\sum_
Пример 3. Найти дисперсию по заданному непрерывному закону распределения случайной величины Х, заданному плотностью $f(x)=x/18$ при $x \in(0,6)$ и $f(x)=0$ в остальных точках.
Используем для расчета формулу дисперсии непрерывной случайной величины: $$ D(X)=\int_<-\infty>^ <+\infty>f(x) \cdot x^2 dx — \left( \int_<-\infty>^ <+\infty>f(x) \cdot x dx \right)^2. $$ Вычислим сначала математическое ожидание: $$ M(X)=\int_<-\infty>^ <+\infty>f(x) \cdot x dx = \int_<0>^ <6>\frac
Вычисление дисперсии онлайн
Как найти дисперсию онлайн для дискретной случайной величины? Используйте калькулятор ниже.
- Введите число значений случайной величины К.
- Появится форма ввода для значений $x_i$ и соответствующих вероятностей $p_i$ (десятичные дроби вводятся с разделителем точкой, например: -10.3 или 0.5). Введите нужные значения (проверьте, что сумма вероятностей равна 1, то есть закон распределения корректный).
- Нажмите на кнопку «Вычислить».
- Калькулятор покажет вычисленное математическое ожидание $M(X)$ и затем искомое значение дисперсии $D(X)$.
Видео. Полезные ссылки
Видеоролики: что такое дисперсия и как найти дисперсию
Если вам нужно более подробное объяснение того, что такое дисперсия, как она вычисляется и какими свойствами обладает, рекомендую два видео (для дискретной и непрерывной случайной величины соответственно).
Полезные ссылки
Что еще может пригодиться? Например, для изучения основ теории вероятностей — онлайн учебник по ТВ. Для закрепления материала — еще примеры решений задач по теории вероятностей.
А если у вас есть задачи, которые надо срочно сделать, а времени нет? Можете поискать готовые решения в решебнике или заказать в МатБюро:
Источник
5. Размах вариации. Среднее линейное отклонение.
Генеральная и выборочная дисперсия
На предыдущем уроке по математической статистике мы изучили центральные показатели статистической совокупности, а именно моду, медиану, среднюю, и теперь переходим к показателям вариации. Они показывают, КАК варьируются статистические данные, а именно – насколько далеко «разбросаны» варианты относительно средних значений, да и просто друг от друга. В данной статье будут рассмотрены самые популярные показатели, и для опытных читателей сразу оглавление:
и, чтобы не «лепить» километровую простыню, разделю материал на две веб страницы:
- Во второй части будет формула для вычисления дисперсии, среднее квадратическое (стандартное) отклонение и коэффициент вариации.
Итак, прямо сейчас мы сформулируем определения этих показателей, узнаем соответствующие формулы и, конечно, потренируемся в конкретных вычислениях. Да не просто в конкретных, а в рациональных.
Но прежде систематизируем информацию о том, какие статистические данные могут оказаться в нашем распоряжении:
– они могут быть первичными (не обработанными), грубо говоря – это неупорядоченный список чисел, либо вторичными – это уже сформированный дискретный (Урок 2) или интервальный вариационный ряд (Урок 3).
– рассматриваемая статистическая совокупность может быть генеральной либо выборочной, и чаще, конечно, перед нами выборка.
…что-то не понятно по терминам? Срочно изучать основы предмета (Урок 1)! – это быстро и интересно, ну а я, сколько нужно, вас тут подожду 🙂
Размах вариации
Он уже встречался. Это разность между самым большим и самым малым значением статической совокупности:
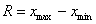
при этом не имеет значения, генеральная ли нам дана совокупность или выборочная, сгруппированы ли данные или нет.
Очевидно, что все варианты 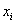 исследуемой совокупности (той или иной) заключены в отрезке
исследуемой совокупности (той или иной) заключены в отрезке  , а размах
, а размах 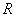 – есть не что иное, как его длина.
– есть не что иное, как его длина.
Такой вот простой, надёжный и понятный показатель. Но, несмотря на его элементарность, рассмотрим технику вычисления, и, конечно, это отличный повод размяться:
Дана статистическая совокупность
15, 17, 13, 10, 21, 17, 23, 9, 14, 19
Найти размах вариации
Решить задачу можно несколькими способами.
Способ первый, суровый – продолжаю вас готовить к борьбе с киборгами :)) Это когда под рукой нет вычислительной техники. Или когда она есть, но вы сами понимаете, как важно «прокачать» свои человеческие способности.
Если чисел не так много (наш случай), то максимальное и минимальное значения легко углядеть устно: 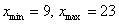 и размах равен:
и размах равен: 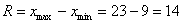 единиц.
единиц.
Если чисел больше (20-30 и даже больше), то надёжен следующий алгоритм:
1) Ищем минимальное значение. Сначала самым маленьким будет первое число: 15. Второе число (17) больше, и поэтому его пропускаем. Третье число (13) меньше, чем 15, и теперь 13 – самое малое число. И так далее, пока не закончится список.
2) Ищем максимальное значение. Сначала самым большим будет первое число: 15. Второе число (17) больше и теперь оно становится самым большим. И так далее – до конца списка.
Способ второй, более быстрый (обычно). Использование программного обеспечения, при этом числа можно просто отсортировать (по возрастанию либо убыванию) или использовать специальные функции:
Запишем ответ 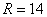 ед. и с нетерпением перейдём к другим показателям, которые характеризуют степень рассеяния вариант относительно центра совокупности, прежде всего, относительно средней.
ед. и с нетерпением перейдём к другим показателям, которые характеризуют степень рассеяния вариант относительно центра совокупности, прежде всего, относительно средней.
О смысле и важности этих показателей я рассказал в курсе теории вероятностей (статья о дисперсии дискретной случайной величины), но коротко повторю и сейчас. Рассмотрим двух студентов, каждый из которых в среднем учится на 3,5 балла. Но есть один нюанс. Один стабильно получает тройки-четвёрки, а другой то пятёрки, то двойки. И поэтому важно знать меру рассеяния оценок относительно средней величины. Чем она меньше – тем стабильнее учится студент.
Эту меру можно оценить следующим образом: из каждой оценки 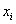 (пусть их будет
(пусть их будет 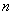 штук) вычитаем среднее значение
штук) вычитаем среднее значение 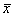 . Величина
. Величина 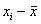 называется отклонением (значения
называется отклонением (значения 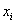 ) от средней.
) от средней.
Теперь эти отклонения нужно просуммировать, но тут появляется проблема: среди разностей 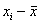 есть как положительные, так и отрицательные, и при их суммировании будет происходить взаимоуничтожение отклонений. Более того, итоговая сумма равна нулю:
есть как положительные, так и отрицательные, и при их суммировании будет происходить взаимоуничтожение отклонений. Более того, итоговая сумма равна нулю: 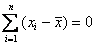 , и мы не получаем желаемого результата.
, и мы не получаем желаемого результата.
Вопрос можно решить с помощью модуля, который уничтожает минусы: 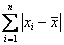 , после чего осталось разделить сумму на объём совокупности
, после чего осталось разделить сумму на объём совокупности 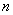 и получить:
и получить:
среднее линейное отклонение
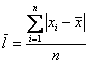 – есть среднее арифметическое абсолютных отклонений всех значений статистической совокупности от средней. Это формула для несгруппированных статистических данных.
– есть среднее арифметическое абсолютных отклонений всех значений статистической совокупности от средней. Это формула для несгруппированных статистических данных.
Если же в нашем распоряжении есть сформированный дискретный либо интервальный вариационный ряд, то формула будет такой:
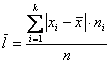 , где
, где 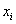 – варианты (для дискретного ряда) либо середины частичных интервалов (для интервального ряда), а
– варианты (для дискретного ряда) либо середины частичных интервалов (для интервального ряда), а 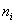 – соответствующие частоты.
– соответствующие частоты.
Напоминаю, что маленькая буква 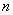 обычно используется для выборочной совокупности, а большая – для генеральной:
обычно используется для выборочной совокупности, а большая – для генеральной: 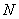 – объём ген. совокупности,
– объём ген. совокупности, 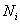 – частоты.
– частоты.
И начнём мы с малого:
В результате 10 независимых измерений некоторой величины, выполненных с одинаковой точностью, полученные опытные данные, которые представлены в таблице 
Требуется вычислить среднее линейное отклонение
Решение: очевидно, что перед нами первичные данные и выборочная совокупность (теоретически измерений можно провести бесконечно много). На первом шаге вычислим выборочную среднюю: 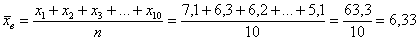
Теперь находим модули отклонений от средней: 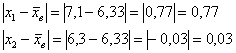
…
и так далее до: 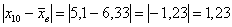
Вычисления удобно проводить на калькуляторе или в Экселе, а результаты заносить в таблицу: 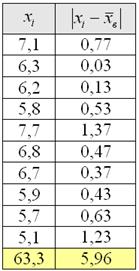
На завершающем этапе рассчитываем сумму модулей:
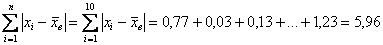 и среднее линейное отклонение:
и среднее линейное отклонение:
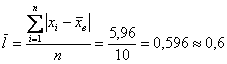 ед. – оно означает, что измеренные значения
ед. – оно означает, что измеренные значения 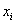 в среднем отличаются от
в среднем отличаются от 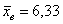 примерно на 0,6 ед.
примерно на 0,6 ед.
Но помимо этого, для оценки рассеяния вариант относительно средней существует более совершенный и распространённый подход. Он состоит в том, чтобы использовать не модули, а возведение отклонений в квадрат: 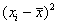 (чтобы ликвидировать встречающиеся отрицательные значения).
(чтобы ликвидировать встречающиеся отрицательные значения).
Генеральная и выборочная дисперсия
Дисперсия с латыни так и переводится – рассеяние.
…не сломать бы язык 🙂 …так… Выборочная дисперсия – это среднее арифметическое квадратов отклонений всех вариант выборки от её средней:
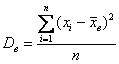 – для несгруппированных данных, и:
– для несгруппированных данных, и:
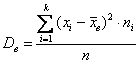 – для сформированного вариационного ряда, где
– для сформированного вариационного ряда, где 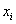 – кратные (одинаковые по значению) варианты в дискретном случае либо середины частичных интервалов – в интервальном, и
– кратные (одинаковые по значению) варианты в дискретном случае либо середины частичных интервалов – в интервальном, и 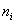 – соответствующие частоты.
– соответствующие частоты.
Еще раз не спеша и ОСМЫСЛЕННО прочитайте определение и выполните
Сформулировать и записать (на бумагу!) определение генеральной дисперсии и соответствующие формулы.
Свериться можно, как обычно, в конце урока.
После чего следует
продолжение Примера 13
По тем же исходным данным вычислить выборочную дисперсию
Без проблем. Вместо модулей рассчитываем квадраты отклонений: 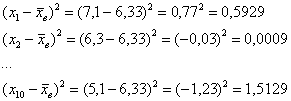
заполняем табличку: 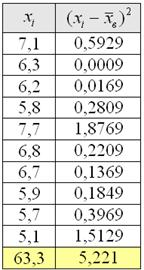
и порядок:
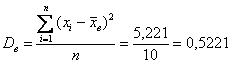 квадратных (!) единиц – коль скоро, мы возводили в квадрат. И, чтобы вернуться в размерность задачи, из дисперсии следует извлечь корень. Но мы не будем торопить события, лучше посмотрим, как выполнять вычисления в Экселе:
квадратных (!) единиц – коль скоро, мы возводили в квадрат. И, чтобы вернуться в размерность задачи, из дисперсии следует извлечь корень. Но мы не будем торопить события, лучше посмотрим, как выполнять вычисления в Экселе:
Ответ: 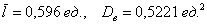
Разобранная задача де-факто встречается в лабораторных работах по физике (да и не только) – когда некоторая величина замеряется раз 10 и затем рассчитывается среднее значение.
А теперь представьте, что вся ваша группа выполняет лабу по физике, и каждый провёл по 10 испытаний в схожих условиях. Очевидно, что у всех получились несколько разные выборочные значения 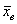 , но все они без какой-либо закономерности (в общем случае) будут варьироваться вокруг истинного значения показателя
, но все они без какой-либо закономерности (в общем случае) будут варьироваться вокруг истинного значения показателя 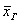 (роль генеральной средней может играть некий теоретический эталон). Это свойство (отсутствие закономерности) называется несмещённостью оценки генеральной средней, и справедливо оно, как мы увидим ниже, не для всех показателей.
(роль генеральной средней может играть некий теоретический эталон). Это свойство (отсутствие закономерности) называется несмещённостью оценки генеральной средней, и справедливо оно, как мы увидим ниже, не для всех показателей.
Теперь пару ласковых об отклонениях. В чём их смысл? Всё просто: у кого эти показатели ниже, тот качественнее проводит опыты (плавнее выполняет действия, точнее снимает показания с приборов, засекает время и т.п.). В идеале эти отклонения равны нулю, но это только в идеале – сам эмпиризм ситуации порождает генеральное линейное отклонение 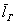 и генеральную дисперсию
и генеральную дисперсию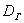 , которые обусловлены человеческим фактором, погрешностью приборов и так далее – вплоть до магнитных бурь.
, которые обусловлены человеческим фактором, погрешностью приборов и так далее – вплоть до магнитных бурь.
В случае с полученными линейными отклонениями 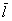 – всё то же самое, они будут безо всякой закономерности варьироваться вокруг генерального значения
– всё то же самое, они будут безо всякой закономерности варьироваться вокруг генерального значения 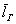 . Но вот с дисперсией всё не так. Полученные значения выборочной дисперсии
. Но вот с дисперсией всё не так. Полученные значения выборочной дисперсии 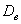 будут давать систематически заниженную оценку генеральной дисперсии
будут давать систематически заниженную оценку генеральной дисперсии 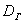 . И поэтому выборочную дисперсию следует «поправить» по формуле:
. И поэтому выборочную дисперсию следует «поправить» по формуле:
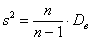 – желающие могут найти обоснование этого факта и этой формулы в специализированной литературе по математической статистике.
– желающие могут найти обоснование этого факта и этой формулы в специализированной литературе по математической статистике.
Показатель 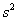 так и называется – исправленная выборочная дисперсия, и вот она уже является несмещённой оценкой генеральной дисперсии.
так и называется – исправленная выборочная дисперсия, и вот она уже является несмещённой оценкой генеральной дисперсии.
Таким образом, каждый студент должен поправить свою дисперсию, в частности, для Примера 13: 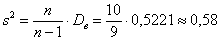
Следует отметить, что для большой выборки (от 100 и даже от 30 вариант) этой поправкой можно пренебречь, так как при 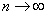 дробь
дробь 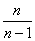 стремится к единице и
стремится к единице и 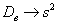 .
.
И иногда дисперсию можно вовсе не поправлять. Так, в разобранном примере от нас требовалось просто вычислить выборочную дисперсию и всё. А если хочется что-то додумать, то пусть этого захочет преподаватель 🙂 Но вот если дисперсия будет «участвовать» в дальнейших действиях, то, конечно, приводим её к виду 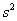 .
.
Более того, встречаются задачи, где вообще не понятно – выборочная ли дана совокупность или генеральная, и тогда разумно проявить аккуратность и использовать обозначения без подстрочных индексов, в частности, 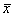 и
и 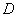 .
.
Теперь случай, когда дан готовый вариационный ряд. У меня опять есть подходящая советская задача про телефонную станцию, но я скорректирую условие в соответствии с современными реалиями:
В результате выборочного исследования звонков, статистик МТС получил следующие данные (за некоторый временной промежуток): 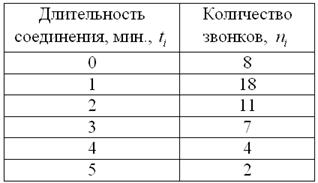
…у ОпСоСов, как известно, своя статистика – с округлением до ближайшей целой минуты :), впрочем, это тоже устареет…, как метко заметил современник, дети дружно играли во дворе – каждый в своём смартфоне(
Найти размах вариации, среднее линейное отклонение и выборочную дисперсию. Дать несмещённую оценку генеральной дисперсии и пояснить, что это означает.
Решить данную задачу в Экселе (данные и гайд уже там) либо на бумаге с помощью калькулятора.
Краткое решение и ответ совсем близко, поскольку 1-я часть урока подошла к концу, и я жду вас во 2-й части, где мы рассмотрим формулу для вычисления дисперсии, среднее квадратическое отклонение и коэффициент вариации.
Решения и ответы:
Задание. Генеральная дисперсия – это среднее арифметическое квадратов отклонений всех вариант генеральной совокупности от её средней: 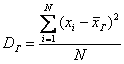 , где
, где 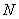 – объём генеральной совокупности.
– объём генеральной совокупности.
Для сформированного вариационного ряда формула принимает вид: 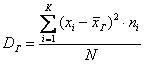 , где
, где 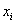 – либо варианты дискретного ряда, либо середины частичных интервалов интервального ряда, а
– либо варианты дискретного ряда, либо середины частичных интервалов интервального ряда, а 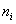 – соответствующие частоты.
– соответствующие частоты.
Пример 14. Решение: найдём размах вариации: 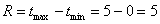 мин.
мин.
Вычислим объём совокупности 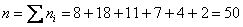 , произведения
, произведения 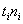 , их сумму и выборочную среднюю
, их сумму и выборочную среднюю 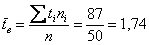 мин.
мин.
Рассчитаем 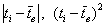 , произведения
, произведения 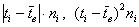 и их суммы:
и их суммы: 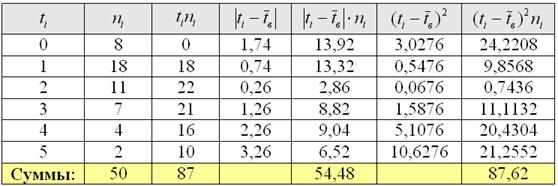
Среднее линейное отклонение:
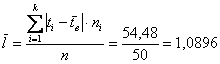 мин.
мин.
Выборочная дисперсия:
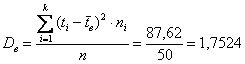 мин. в квадрате.
мин. в квадрате.
Несмещённой оценкой генеральной дисперсии является исправленная выборочная дисперсия:
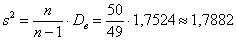 мин. в квадрате.
мин. в квадрате.
Несмещённость означает, что если в схожих условиях проводить аналогичные выборки, то полученные значения 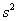 будут безо всякой закономерности варьироваться вокруг генерального значения
будут безо всякой закономерности варьироваться вокруг генерального значения 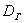 .
.
Ответ: 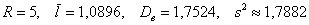
Автор: Емелин Александр
(Переход на главную страницу)
 «Всё сдал!» — онлайн-сервис помощи студентам
«Всё сдал!» — онлайн-сервис помощи студентам
Источник



