
- Моделирование данных: зачем нужно и как реализовать
- Моделирование данных
- Что такое моделирование данных
- Типы моделей данных
- Процесс моделирования данных
- Типы моделирования данных
- Инструменты для моделирования данных
- Способ представления моделей.
- Статьи к прочтению:
- Лекция 9: Способы представления информации в ЭВМ и методы адресации
- Похожие статьи:
Моделирование данных: зачем нужно и как реализовать
Моделирование данных ощутимо упрощает взаимодействие между разработчиками, аналитиками и маркетологами, как и сам процесс создания отчетов. Поэтому я перевела статью IBM Cloud Education о ценности моделирования и от себя добавила инфо о способах трансформации данных для моделирования.
Моделирование данных
Узнайте, как моделирование данных использует абстракцию для представления и лучшего понимания природы данных в информационной системе предприятия.
Что такое моделирование данных
Моделирование данных — это создание визуального представления о всей информационной системе либо ее части. Цель в том, чтобы проиллюстрировать типы данных, которые используются и хранятся в системе, отношения между этими типами данных, способы группировки и организации данных, их форматы и атрибуты.
Модели данных строятся на основе бизнес-потребностей. Правила и требования к модели данных определяются заранее на основе обратной связи с бизнесом, поэтому их можно включить в разработку новой системы или адаптировать к существующей.
Данные можно моделировать на различных уровнях абстракции. Процесс начинается со сбора бизнес-требований от заинтересованных сторон и конечных пользователей. Эти бизнес-правила затем преобразуются в структуры данных. Модель данных можно сравнить с дорожной картой, планом архитектора или любой формальной схемой, которая способствует более глубокому пониманию того, что разрабатывается.
Моделирование данных использует стандартизированные схемы и формальные методы. Это обеспечивает последовательный и предсказуемый способ управления данными в организации или за ее пределами.
В идеале модели данных — это живые документы, которые развиваются вместе с потребностями бизнеса. Они играют важную роль в поддержке бизнес-процессов и планировании ИТ-архитектуры и стратегии. Моделями данных можно делиться с поставщиками, партнерами и коллегами.
Преимущества моделирования данных
Моделирование упрощает просмотр и понимание взаимосвязей между данными для разработчиков, архитекторов данных, бизнес-аналитиков и других заинтересованных лиц. Кроме того, моделирование данных помогает:
Уменьшить количество ошибок при разработке программного обеспечения и баз данных.
Унифицировать документацию на предприятии.
Повысить производительность приложений и баз данных.
Упростить отображение данных по всей организации.
Улучшить взаимодействие между разработчиками и командами бизнес-аналитики.
Упростить и ускорить процесс проектирования базы данных на концептуальном, логическом и физическом уровнях.
Типы моделей данных
Разработка баз данных и информационных систем начинается с высокого уровня абстракции и с каждым шагом становится все точнее и конкретнее. В зависимости от степени абстракции модели данных можно разделить на три категории. Процесс начинается с концептуальной модели, переходит к логической модели и завершается физической моделью.
Концептуальные модели данных. Также они называются моделями предметной области и описывают общую картину: что будет содержать система, как она будет организована и какие бизнес-правила будут задействованы. Концептуальные модели обычно создаются в процессе сбора исходных требований к проекту. Как правило, они включают классы сущностей (вещи, которые бизнесу важно представить в модели данных), их характеристики и ограничения, отношения между сущностями, требования к безопасности и целостности данных. Любые обозначения обычно просты.

Логические модели данных уже не так абстрактны и предоставляют более подробную информацию о концепциях и взаимосвязях в рассматриваемой области. Они содержат атрибуты данных и показывают отношения между сущностями. Логические модели данных не определяют никаких технических требований к системе. Этот этап часто пропускается в agile или DevOps-практиках. Логические модели данных могут быть полезны для проектов, ориентированных на данные по своей природе. Например, для проектирования хранилища данных или разработки системы отчетности.
Физические модели данных представляют схему того, как данные будут храниться в базе. По сути, это наименее абстрактные из всех моделей. Они предлагают окончательный дизайн, который может быть реализован как реляционная база данных, включающая ассоциативные таблицы, которые иллюстрируют отношения между сущностями, а также первичные и внешние ключи для связи данных.
Процесс моделирования данных
Моделирование данных начинается с договоренности о том, какие символы используются для представления данных, как размещаются модели и как передаются бизнес-требования. Это формализованный рабочий процесс, включающий ряд задач, которые должны выполняться итеративно. Сам процесс обычно выглядят так:
Определите сущности. На этом этапе идентифицируем объекты, события или концепции, представленные в наборе данных, который необходимо смоделировать. Каждая сущность должна быть целостной и логически отделенной от всех остальных.
Определите ключевые свойства каждой сущности. Каждый тип сущности можно отличить от всех остальных, поскольку он имеет одно или несколько уникальных свойств, называемых атрибутами. Например, сущность «клиент» может обладать такими атрибутами, как имя, фамилия, номер телефона и т.д. Сущность «адрес» может включать название и номер улицы, город, страну и почтовый индекс.
Определите связи между сущностями. Самый ранний черновик модели данных будет определять характер отношений, которые каждая сущность имеет с другими. В приведенном выше примере каждый клиент «живет по» адресу. Если бы эта модель была расширена за счет включения сущности «заказы», каждый заказ также был бы отправлен на адрес. Эти отношения обычно документируются с помощью унифицированного языка моделирования (UML).
Полностью сопоставьте атрибуты с сущностями. Это гарантирует, что модель отражает то, как бизнес будет использовать данные. Широко используются несколько формальных шаблонов (паттернов) моделирования данных. Объектно-ориентированные разработчики часто применяют шаблоны для анализа или шаблоны проектирования, в то время как заинтересованные стороны из других областей бизнеса могут обратиться к другим паттернам.
Назначьте ключи по мере необходимости и определите степень нормализации. Нормализация — это метод организации моделей данных, в которых числовые идентификаторы (ключи) назначаются группам данных для установления связей между ними без повторения данных. Например, если каждому клиенту назначен ключ, этот ключ можно связать как с его адресом, так и с историей заказов, без необходимости повторять эту информацию в таблице с именами клиентов. Нормализация помогает уменьшить объем дискового пространства, необходимого для базы данных, но может сказываться на производительности запросов.
Завершите и проверьте модель данных. Моделирование данных — это итеративный процесс, который следует повторять и совершенствовать под потребности бизнеса.
Типы моделирования данных
Моделирование данных развивалось вместе с системами управления базами данных (СУБД), при этом типы моделей усложнялись по мере роста потребностей предприятий в хранении данных.
Иерархические модели данных представляют отношения «один ко многим» в древовидном формате. В модели этого типа каждая запись имеет единственный корень или родительский элемент, который сопоставляется с одной или несколькими дочерними таблицами. Эта модель была реализована в IBM Information Management System (IMS) в 1966 году и быстро нашла широкое применение, особенно в банковской сфере. Хотя этот подход менее эффективен, чем недавно разработанные модели баз данных, он все еще используется в системах расширяемого языка разметки (XML) и географических информационных системах (ГИС).
Реляционные модели данных были предложены исследователем IBM Э. Ф. Коддом в 1970 году. Они до сих пор встречаются во многих реляционных базах данных, обычно используемых в корпоративных вычислениях. Реляционное моделирование не требует детального понимания физических свойств используемого хранилища данных. В нем сегменты данных объединяются с помощью таблиц, что упрощает базу данных.
Реляционные базы данных часто используют язык структурированных запросов (SQL) для управления данными. Эти базы подходят для поддержания целостности данных и минимизации избыточности. Они часто используются в кассовых системах, а также для других типов обработки транзакций.
В ER-моделях данных используют диаграммы для представления взаимосвязей между сущностями в базе данных. ER-модель представляет собой формальную конструкцию, которая не предписывает никаких графических средств её визуализации. В качестве стандартной графической нотации, с помощью которой можно визуализировать ER-модель, была предложена диаграмма «сущность-связь» (Entity-Relationship diagram). Однако для визуализации ER-моделей могут использоваться и другие графические нотации, либо визуализация может вообще не применяться (например, только текстовое описание).
Объектно-ориентированные модели данных получили распространение как объектно-ориентированное программирование и стали популярными в середине 1990-х годов. Вовлеченные «объекты» — это абстракции сущностей реального мира. Объекты сгруппированы в иерархии классов и имеют связанные черты. Объектно-ориентированные базы данных могут включать таблицы, но могут также поддерживать более сложные связи. Этот подход часто используется в мультимедийных и гипертекстовых базах данных.
Размерные модели данных разработал Ральф Кимбалл для быстрого поиска данных в хранилище. Реляционные и ER-модели делают упор на эффективное хранение и уменьшают избыточность данных, а размерные модели упорядочивает данные таким образом, чтобы легче было извлекать информацию и создавать отчеты. Это моделирование обычно используется в системах OLAP.
Две популярные размерные модели данных — это схемы «звезда» и «снежинка». В схеме «звезда» данные организованы в факты (измеримые элементы) и измерения (справочная информация), где каждый факт окружен связанными с ним измерениями в виде звездочки. Схема «снежинка» напоминает схему «звезда», но включает дополнительные слои связанных измерений, что усложняет схему ветвления.
Инструменты для моделирования данных
Сегодня широко используются многочисленные коммерческие и CASE-решения с открытым исходным кодом, в том числе различные инструменты моделирования данных, построения диаграмм и визуализации. Вот несколько примеров:
erwin Data Modeler — это инструмент моделирования данных, основанный на языке IDEF1X, который теперь поддерживает и другие нотации, включая нотацию для размерного моделирования.
Enterprise Architect — это инструмент визуального моделирования и проектирования, который поддерживает моделирование корпоративных информационных систем и архитектур, программных приложений и баз данных. Он основан на объектно-ориентированных языках и стандартах.
ER/Studio — это программа для проектирования баз данных, совместимая с некоторыми из самых популярных СУБД. Она поддерживает как реляционное, так и размерное моделирование данных.
Бесплатные инструменты моделирования данных включают решения с открытым исходным кодом, такие как Open ModelSphere.
Для того, чтобы преобразовать данные в структуру, которая соответствует требованиям модели, можно использовать встроенный механизм регулярных запросов, которые выполняются в Google BigQuery, Scheduled Queries и AppScript. Их легко можно освоить, потому что это привычный SQL, но проводить отладку в Scheduled Queries практически нереально. Особенно, если это какой-то сложный запрос или каскад запросов.
Есть специализированные инструменты для управления SQL-запросами, например, dbt и Dataform.
dbt (data build tool) — это фреймворк с открытым исходным кодом для выполнения, тестирования и документирования SQL-запросов, который позволяет привнести элемент программной инженерии в процесс анализа данных. Он помогает оптимизировать работу с SQL-запросами: использовать макросы и шаблоны JINJA, чтобы не повторять в сотый раз одни и те же фрагменты кода.
Главная проблема, которую решают специализированные инструменты — это уменьшение времени, необходимого на поддержку и обновление. Это достигается за счет удобства отладки.
Источник
Способ представления моделей.
Классификация по области использования
Если рассматривать модели с позиции для чего, с какой целью они используются, то можно применять классификацию, изображенную на рисунке 3.

Учебные модели используются при обучении. Это могут быть наглядные пособия, различные тренажеры, обучающие программы.
Опытные модели – это уменьшенные или увеличенные копии проектируемого объекта. Их называют также натурными моделями, и используют для исследования объекта и прогнозирования его будущих характеристик.
Научно-технические модели создаются для исследования процессов и явлений. К таким моделям можно отнести прибор для получения грозового электрического разряда, модель движения планет Солнечной системы, модель работы двигателя внутреннего сгорания.
Игровые модели– это различного рода игры: деловые, экономические, военные. С помощью таких моделей можно разрешать конфликтные ситуации, оказывать психологическую помощь, проигрывать поведение объекта в различных ситуациях.
Имитационные модели не просто отражают реальность с той или иной степенью точности, а имитируют ее. Эксперимент с моделью либо многократно повторяется при разных исходных данных, чтобы изучить и оценить последствия каких-либо действий на реальную обстановку, либо проводится одновременно со многими другими похожими объектами, но поставленными в разные условия. По результатам исследования делаются выводы. Подобный метод выбора правильного решения называется методом проб и ошибок. К примеру, в ряде опытов на мышах испытывается новое лекарственное средство, чтобы выявить побочные действия и уточнить дозировки.
Классификация с учетом временного фактора
Классификация моделей с учетом временного фактора приведена на рисунке 4.
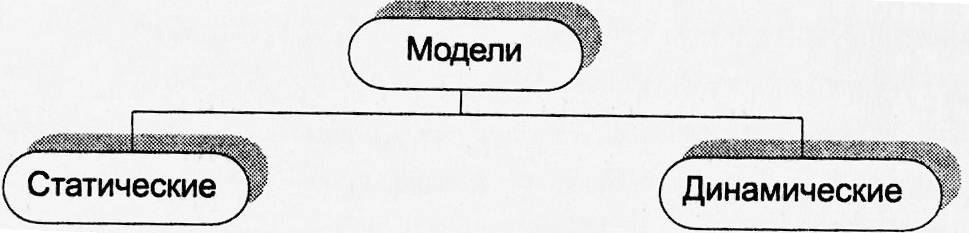
Статические моделиотражают объект в определенный момент времени, без учета происходящих с ним изменений.В этих моделях отсутствует временной фактор.
Примером статической модели может служить макет или рисунок молекулы воды, состоящей из атомов водорода и кислорода.
Динамические моделиотражают процесс изменения объекта во времени.
Химический опыт, проводимый в лаборатории, является примером динамической модели.
Один и тот же объект возможно изучать, применяя и статическую и динамическую модели.
Классификация по отрасли знаний
Здесь можно выделить следующие виды моделей:
Классификация по способу представления
Классификация моделей по способу представления приведена на рисунке 6.
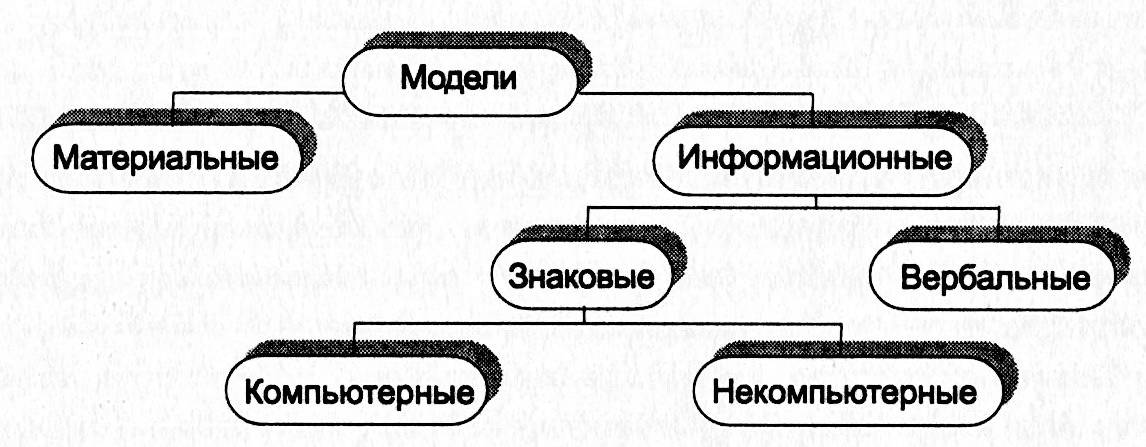
В соответствии с этой классификацией модели делятся на две большие группы: материальные (иначе их называют предметные) и информационные (абстрактные).
Материальные моделииначе можно назвать предметными, физическими. Они воспроизводят геометрические и физические свойства оригинала, и всегда имеют реальное воплощение.
Информационная модель – совокупность информации, характеризующая свойства и состояния объекта, процесса, явления, а также взаимосвязь с внешним миром. Информационная модель–это описание объекта.
Знаковые и вербальные информационные модели. К информационным моделям можно отнести вербальные (от лат. «verbalis» – устный) модели, полученные в результате раздумий, умозаключений. Они могут остаться мысленными или быть выражены словесно. К таким моделям можно отнести идею, возникшую у изобретателя, и музыкальную тему, промелькнувшую в голове композитора, и рифму, прозвучавшую пока еще в сознании поэта.
Вербальная модель – информационная модель в мысленной или разговорной форме.
Знаковая модель – информационная модель, выраженная специальными знаками, т.е. средствами любого формального языка.
К знаковым моделям относятся:
математические модели – это модели, построенные с использованием математических понятий и формул;
специальные – представлены на специальных языках (ноты, химические формулы);
Существуют и другие подходы к классификации информационных моделей.
В зависимости от структуры информационные модели делятся на:
Компьютерные и некомпьютерные модели. В информатике рассматриваются модели, которые можно создавать и исследовать с помощью компьютера. В этом случае модели делят на компьютерные и некомпьютерные.
Компьютерная модель – это модель, реализованная средствами программной среды.
В настоящее время выделяют два вида компьютерных моделей:
структурно-функциональные, которые представляют собой условный образ объекта, описанный с помощью компьютерных технологий;
имитационные, представляющие собой программу или комплекс программ, позволяющий воспроизводить процессы функционирования объекта в разных условиях.
Основные этапы компьютерного моделирования
Все этапы определяются поставленной задачей и целями моделирования. В общем случае процесс построения и исследования модели можно представить следующей схемой (рисунок 7):
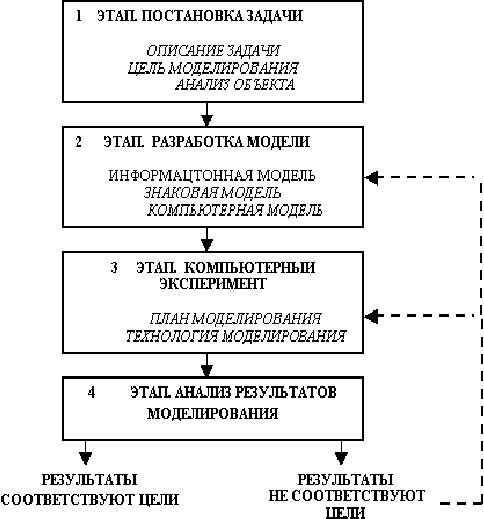
Первый этап – постановка задачи включает в себя стадии: описание задачи, определение цели моделирования, анализ объекта. Ошибки при постановке задачи приводят к наиболее тяжелым последствиям!
Описание задачи. Задача формулируется на обычном языке. По характеру постановки все задачи можно разделить на две основные группы. К первой группе можно отнести задачи, в которых требуется исследовать, как изменятся характеристики объекта при некотором воздействии на него, «что будет, если… ?».
Например, что будет, если магнитный диск положить рядом с магнитом?
В задачах, относящихся ко второй группе, требуется определить, какое надо произвести воздействие на объект, чтобы его параметры удовлетворяли некоторому заданному условию, «как сделать, чтобы…?».
Определение цели моделирования. На этой стадии необходимо среди многих характеристик (параметров) объекта выделить существенные.
Анализ объекта подразумевает четкое выделение моделируемого объекта и его основных свойств.
Второй этап – формализация задачи связан с созданием формализованной модели, то есть модели, записанной на каком-либо формальном языке. Например, данные переписи населения, представленные в виде таблицы или диаграммы – это формализованная модель.
В общем смыслеформализация– это приведение существенных свойств и признаков объекта моделирования к выбранной форме.
Третий этап – разработка компьютерной модели начинается с выбора инструмента моделирования, другими словами, программной среды, в которой будет создаваться, и исследоваться модель.
От этого выбора зависит алгоритм построения компьютерной модели, а также форма его представления. В среде программирования – это программа, написанная на соответствующем языке. В прикладных средах (электронные таблицы, СУБД, графических редакторах и т. д.) – это последовательность технологических приемов, приводящих к решению задачи.
Следует отметить, что одну и ту же задачу можно решить, используя различные среды. Выбор инструмента моделирования зависит, в первую очередь, от реальных возможностей, как технических, так и материальных.
Четвертый этап – компьютерный эксперимент включает две стадии: тестирование модели и проведение исследования.
Тестирование модели– процесс проверки правильности построения модели.
На этой стадии проверяется разработанный алгоритм построения модели и адекватность полученной модели объекту и цели моделирования.
Для проверки правильности алгоритма построения модели используется тестовые данные, для которых конечный результат заранее известен (обычно его определяют ручным способом). Если результаты совпадают, то алгоритм разработан верно, если нет – надо искать и устранять причину их несоответствия.
Тестирование должно быть целенаправленным и систематизированным, а усложнение тестовых данных должно происходить постепенно. Чтобы убедиться, что построенная модель правильно отражает существенные для цели моделирования свойства оригинала, то есть является адекватной, необходимо подбирать тестовые данные, которые отражают реальную ситуацию.
Уровни тестирования программного обеспечения (ПО):
Модульное тестирование (юнит-тестирование) – тестируется минимально возможный для тестирования компонент, например, отдельный класс или функция. Часто модульное тестирование осуществляется разработчиками ПО.
Интеграционное тестирование – тестируются интерфейсы между компонентами, подсистемами. При наличии резерва времени на данной стадии тестирование ведётся итерационно, с постепенным подключением последующих подсистем.
Системное тестирование – тестируется интегрированная система на её соответствие требованиям.
Альфа-тестирование – имитация реальной работы с системой штатными разработчиками, либо реальная работа с системой потенциальными пользователями/заказчиком. Чаще всего альфа-тестирование проводится на ранней стадии разработки продукта, но в некоторых случаях может применяться для законченного продукта в качестве внутреннего приёмочного тестирования.
Бета-тестирование – в некоторых случаях выполняется распространение версии с ограничениями (по функциональности или времени работы) для некоторой группы лиц, с тем, чтобы убедиться, что продукт содержит достаточно мало ошибок. Иногда бета-тестирование выполняется для того, чтобы получить обратную связь о продукте от его будущих пользователей.
Часто для свободного/открытого ПО стадия альфа-тестирования характеризует функциональное наполнение кода, а бета-тестирования — стадию исправления ошибок. При этом, как правило, на каждом этапе разработки промежуточные результаты работы доступны конечным пользователям.
Тестирование «белого ящика». В терминологии профессионалов тестирования, фразы «тестирование белого ящика» и «тестирование чёрного ящика» относятся к тому, имеет ли разработчик тестов доступ к исходному коду тестируемого ПО.
Тестирование «белого ящика» – это тестирование, при котором тестировщик имеет доступ к коду. Кроме того, что тестировщик может просматривать код, он еще и сам может писать код, который использует библиотеки существующего программного продукта.
Другое название этого метода – структурное тестирование.
Тестирование «чёрного ящика». Тестирование методом «черного ящика» базируется на том, что поведение системы можно определить только посредством изучения ее входных и соответствующих выходных данных. Другое название этого метода – функциональное тестирование.
Испытатель подставляет в компонент или систему входные данные и исследует соответствующие выходные данные. Метод обработки данных, и каким образом получаются выходные данные – неизвестно, это закрыто «черным ящиком».
Пятый этап – анализ результатов является ключевым для процесса моделирования. Именно по итогам этого этапа принимается решение: продолжать исследование или закончить.
Если результаты не соответствуют целям поставленной задачи, значит, на предыдущих этапах были допущены ошибки. В этом случае необходимо корректировать модель, то есть возвращаться к одному из предыдущих этапов. Процесс повторяется до тех пор, пока результаты компьютерного эксперимента не будут отвечать целям моделирования.
Системный подход в моделировании
Окружающий нас мир состоит из множества различных объектов, каждый из которых имеет разнообразные свойства, и при этом объекты взаимодействуют между собой. Например, такие объекты, как планеты Солнечной системы, имеют различные свойства (массу, геометрические размеры и пр.) и по закону всемирного тяготения взаимодействуют с Солнцем и друг с другом. Планеты входят в состав более крупного объекта — Солнечной системы, а Солнечная система – в состав нашей галактики «Млечный путь». С другой стороны, планеты состоят из атомов различных химических элементов, а атомы — из элементарных частиц. Можно сделать вывод, что практически каждый объект состоит из других объектов, то есть представляет собой систему.
Важным признаком системы является ее целостное функционирование. Система является не набором отдельных элементов, а совокупностью взаимосвязанных элементов. Например, компьютер является системой, состоящей из различных устройств, при этом устройства связаны между собой и аппаратно (физически подключены друг к другу) и функционально (между устройствами происходит обмен информацией).
Система является совокупностью взаимосвязанных объектов, которые называются элементами системы.
Состояние системы характеризуется ее структурой, то есть составом и свойствами элементов, их отношениями и связями между собой. Система сохраняет свою целостность под воздействием различных внешних воздействий и внутренних изменений до тех пор, пока она сохраняет неизменной свою структуру. Если структура системы меняется (например, удаляется один из элементов), то система может перестать функционировать как целое. Так, если удалить одно из устройств компьютера (например, процессор), компьютер выйдет из строя, то есть прекратит свое существование как система.
Любая система существует в пространстве и во времени. В каждый момент времени система находится в определенном состоянии, которое характеризуется составом элементов, значениями их свойств, величиной и характером взаимодействия между элементами и так далее.
Так, состояние Солнечной системы в любой момент времени характеризуется составом входящих в нее объектов (Солнце, планеты и др.), их свойствами (размерами, положением в пространстве и др.), величиной и характером взаимодействия между собой (силами тяготения, с помощью электромагнитных волн и др.).
Модели, описывающие состояние системы в определенный момент времени, называются статическими информационными моделями.
Статьи к прочтению:
Лекция 9: Способы представления информации в ЭВМ и методы адресации
Похожие статьи:
ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ ПРОФЕССИОНАЛЬНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ МОСКОВСКОЙ ОБЛАСТИ «ВОСКРЕСЕНСКИЙ КОЛЛЕДЖ» РЕФЕРАТ ПО ИНФОРМАТИКЕ И ИКТ на тему:…
Обычно бывает трудно, а иногда и невозможно проследить за поведением реальных систем в разных условиях или изменить эти системы. Решить данную проблему…
Источник



