
- Сравнение алгоритмов сортировки
- Алгоритмы и структуры данных для начинающих: сортировка
- Авторизуйтесь
- Алгоритмы и структуры данных для начинающих: сортировка
- Метод Swap
- Пузырьковая сортировка
- Сортировка вставками
- Сортировка выбором
- Сортировка слиянием
- Разделяй и властвуй
- Сортировка слиянием
- Быстрая сортировка
- Заключение
Сравнение алгоритмов сортировки
В данной статье рассматриваются алгоритмы сортировки массивов. Для начала представляются выбранные для тестирования алгоритмы с кратким описанием их работы, после чего производится непосредственно тестирование, результаты которого заносятся в таблицу и производятся окончательные выводы.
Алгоритмы сортировок очень широко применяются в программировании, но иногда программисты даже не задумываются какой алгоритм работает лучше всех (под понятием «лучше всех» имеется ввиду сочетание быстродействия и сложности как написания, так и выполнения).
В данной статье постараемся это выяснить. Для обеспечения наилучших результатов все представленные алгоритмы будут сортировать целочисленный массив из 200 элементов. Компьютер, на котором будет проводится тестирование имеет следующие характеристики: процессор AMD A6-3400M 4×1.4 GHz, оперативная память 8 GB, операционная система Windows 10 x64 build 10586.36.
Для проведения исследования были выбраны следующие алгоритмы сортировки:
Selection sort (сортировка выбором) – суть алгоритма заключается в проходе по массиву от начала до конца в поиске минимального элемента массива и перемещении его в начало. Сложность такого алгоритма O(n2).
Bubble sort (сортировка пузырьком) – данный алгоритм меняет местами два соседних элемента, если первый элемент массива больше второго. Так происходит до тех пор, пока алгоритм не обменяет местами все неотсортированные элементы. Сложность данного алгоритма сортировки равна O(n^2).
Insertion sort (сортировка вставками) – алгоритм сортирует массив по мере прохождения по его элементам. На каждой итерации берется элемент и сравнивается с каждым элементом в уже отсортированной части массива, таким образом находя «свое место», после чего элемент вставляется на свою позицию. Так происходит до тех пор, пока алгоритм не пройдет по всему массиву. На выходе получим отсортированный массив. Сложность данного алгоритма равна O(n^2).
Quick sort (быстрая сортировка) – суть алгоритма заключается в разделении массива на два под-массива, средней линией считается элемент, который находится в самом центре массива. В ходе работы алгоритма элементы, меньшие чем средний будут перемещены в лево, а большие в право. Такое же действие будет происходить рекурсивно и с под-массива, они будут разделяться на еще два под-массива до тех пор, пока не будет чего разделать (останется один элемент). На выходе получим отсортированный массив. Сложность алгоритма зависит от входных данных и в лучшем случае будет равняться O(n×2log2n). В худшем случае O(n^2). Существует также среднее значение, это O(n×log2n).
Comb sort (сортировка расческой) – идея работы алгоритма крайне похожа на сортировку обменом, но главным отличием является то, что сравниваются не два соседних элемента, а элементы на промежутке, к примеру, в пять элементов. Это обеспечивает от избавления мелких значений в конце, что способствует ускорению сортировки в крупных массивах. Первая итерация совершается с шагом, рассчитанным по формуле (размер массива)/(фактор уменьшения), где фактор уменьшения равен приблизительно 1,247330950103979, или округлено до 1,3. Вторая и последующие итерации будут проходить с шагом (текущий шаг)/(фактор уменьшения) и будут происходить до тех пор, пока шаг не будет равен единице. Практически в любом случае сложность алгоритма равняется O(n×log2n).
Для проведения тестирования будет произведено по 5 запусков каждого алгоритма и выбрано наилучшее время. Наилучшее время и используемая при этом память будут занесены в таблицу. Также будет проведено тестирование скорости сортировки массива размером в 10, 50, 200 и 1000 элементов чтобы определить для каких задач предназначен конкретный алгоритм.
Полностью неотсортированный массив:

Частично отсортированный массив (половина элементов упорядочена):

Результаты, предоставленые в графиках:


В результате проведенного исследования и полученных данных, для сортировки неотсортированного массива, наиболее оптимальным из представленных алгоритмов для сортировки массива является быстрая сортировка. Несмотря на более длительное время выполнения алгоритм потребляет меньше памяти, что может быть важным в крупных проектах. Однако такие алгоритмы как сортировка выбором, обменом и вставками могут лучше подойти для научных целей, например, в обучении, где не нужно обрабатывать огромное количество данных. При частично отсортированном массиве результаты не сильно отличаются, все алгоритмы сортировки показывают время примерно на 2-3 миллисекунды меньше. Однако при сортировке частично отсортированного массива быстрая сортировка срабатывает намного быстрее и потребляет меньшее количество памяти.
Источник
Алгоритмы и структуры данных для начинающих: сортировка
Авторизуйтесь
Алгоритмы и структуры данных для начинающих: сортировка
В этой части мы посмотрим на пять основных алгоритмов сортировки данных в массиве. Начнем с самого простого — сортировки пузырьком — и закончим «быстрой сортировкой» (quicksort).
Для каждого алгоритма, кроме объяснения его работы, мы также укажем его сложность по памяти и времени в наихудшем, наилучшем и среднем случае.
Метод Swap
Для упрощения кода и улучшения читаемости мы введем метод Swap , который будет менять местами значения в массиве по индексу.
Пузырьковая сортировка
| Сложность | Наилучший случай | В среднем | Наихудший случай |
| Время | O(n) | O(n 2 ) | O(n 2 ) |
| Память | O(1) | O(1) | O(1) |
Сортировка пузырьком — это самый простой алгоритм сортировки. Он проходит по массиву несколько раз, на каждом этапе перемещая самое большое значение из неотсортированных в конец массива.
3–5 декабря, Онлайн, Беcплатно
Например, у нас есть массив целых чисел:

При первом проходе по массиву мы сравниваем значения 3 и 7. Поскольку 7 больше 3, мы оставляем их как есть. После чего сравниваем 7 и 4. 4 меньше 7, поэтому мы меняем их местами, перемещая семерку на одну позицию ближе к концу массива. Теперь он выглядит так:

Этот процесс повторяется до тех пор, пока семерка не дойдет почти до конца массива. В конце она сравнивается с элементом 8, которое больше, а значит, обмена не происходит. После того, как мы обошли массив один раз, он выглядит так:

Поскольку был совершен по крайней мере один обмен значений, нам нужно пройти по массиву еще раз. В результате этого прохода мы перемещаем на место число 6.

И снова был произведен как минимум один обмен, а значит, проходим по массиву еще раз.
При следующем проходе обмена не производится, что означает, что наш массив отсортирован, и алгоритм закончил свою работу.
Сортировка вставками
| Сложность | Наилучший случай | В среднем | Наихудший случай |
| Время | O(n) | O(n 2 ) | O(n 2 ) |
| Память | O(1) | O(1) | O(1) |
Сортировка вставками работает, проходя по массиву и перемещая нужное значение в начало массива. После того, как обработана очередная позиция, мы знаем, что все позиции до нее отсортированы, а после нее — нет.
Важный момент: сортировка вставками обрабатывает элементы массива по порядку. Поскольку алгоритм проходит по элементам слева направо, мы знаем, что все, что слева от текущего индекса — уже отсортировано. На этом рисунке показано, как увеличивается отсортированная часть массива с каждым проходом:
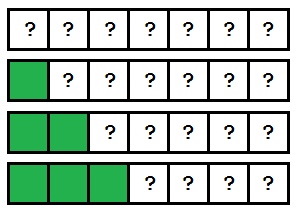
Постепенно отсортированная часть массива растет, и, в конце концов, массив окажется упорядоченным.
Давайте взглянем на конкретный пример. Вот наш неотсортированный массив, который мы будем использовать:

Алгоритм начинает работу с индекса 0 и значения 3. Поскольку это первый индекс, массив до него включительно считается отсортированным.
Далее мы переходим к числу 7. Поскольку 7 больше, чем любое значение в отсортированной части, мы переходим к следующему элементу.
На этом этапе элементы с индексами 0..1 отсортированы, а про элементы с индексами 2..n ничего не известно.
Следующим проверяется значение 4. Так как оно меньше семи, мы должны перенести его на правильную позицию в отсортированную часть массива. Остается вопрос: как ее определить? Это осуществляется методом FindInsertionIndex . Он сравнивает переданное ему значение (4) с каждым значением в отсортированной части, пока не найдет место для вставки.
Итак, мы нашли индекс 1 (между значениями 3 и 7). Метод Insert осуществляет вставку, удаляя вставляемое значение из массива и сдвигая все значения, начиная с индекса для вставки, вправо. Теперь массив выглядит так:
Теперь часть массива, начиная от нулевого элемента и заканчивая элементом с индексом 2, отсортирована. Следующий проход начинается с индекса 3 и значения 4. По мере работы алгоритма мы продолжаем делать такие вставки.
Когда больше нет возможностей для вставок, массив считается полностью отсортированным, и работа алгоритма закончена.
Сортировка выбором
| Сложность | Наилучший случай | В среднем | Наихудший случай |
| Время | O(n) | O(n 2 ) | O(n 2 ) |
| Память | O(1) | O(1) | O(1) |
Сортировка выбором — это некий гибрид между пузырьковой и сортировкой вставками. Как и сортировка пузырьком, этот алгоритм проходит по массиву раз за разом, перемещая одно значение на правильную позицию. Однако, в отличие от пузырьковой сортировки, он выбирает наименьшее неотсортированное значение вместо наибольшего. Как и при сортировке вставками, упорядоченная часть массива расположена в начале, в то время как в пузырьковой сортировке она находится в конце.
Давайте посмотрим на работу сортировки выбором на нашем неотсортированном массиве.

При первом проходе алгоритм с помощью метода FindIndexOfSmallestFromIndex пытается найти наименьшее значение в массиве и переместить его в начало.
Имея такой маленький массив, мы сразу можем сказать, что наименьшее значение — 3, и оно уже находится на правильной позиции. На этом этапе мы знаем, что на первой позиции в массиве (индекс 0) находится самое маленькое значение, следовательно, начало массива уже отсортировано. Поэтому мы начинаем второй проход — на этот раз по индексам от 1 до n — 1.
На втором проходе мы определяем, что наименьшее значение — 4. Мы меняем его местами со вторым элементом, семеркой, после чего 4 встает на свою правильную позицию.

Теперь неотсортированная часть массива начинается с индекса 2. Она растет на один элемент при каждом проходе алгоритма. Если на каком-либо проходе мы не сделали ни одного обмена, это означает, что массив отсортирован.
После еще двух проходов алгоритм завершает свою работу:

Сортировка слиянием
| Сложность | Наилучший случай | В среднем | Наихудший случай |
| Время | O(n·log n) | O(n·log n) | O(n·log n) |
| Память | O(n) | O(n) | O(n) |
Разделяй и властвуй
До сих пор мы рассматривали линейные алгоритмы. Они используют мало дополнительной памяти, но имеют квадратичную сложность. На примере сортировки слиянием мы посмотрим на алгоритм типа «разделяй и властвуй» (divide and conquer).
Алгоритмы этого типа работают, разделяя крупную задачу на более мелкие, решаемые проще. Мы пользуемся ими каждый день. К примеру, поиск в телефонной книге — один из примеров такого алгоритма.
Если вы хотите найти человека по фамилии Петров, вы не станете искать, начиная с буквы А и переворачивая по одной странице. Вы, скорее всего, откроете книгу где-то посередине. Если попадете на букву Т, перелистнете несколько страниц назад, возможно, слишком много — до буквы О. Тогда вы пойдете вперед. Таким образом, перелистывая туда и обратно все меньшее количество страниц, вы, в конце концов, найдете нужную.
Насколько эффективны эти алгоритмы?
Предположим, что в телефонной книге 1000 страниц. Если вы открываете ее на середине, вы отбрасываете 500 страниц, в которых нет искомого человека. Если вы не попали на нужную страницу, вы выбираете правую или левую сторону и снова оставляете половину доступных вариантов. Теперь вам надо просмотреть 250 страниц. Таким образом мы делим нашу задачу пополам снова и снова и можем найти человека в телефонной книге всего за 10 просмотров. Это составляет 1% от всего количества страниц, которые нам пришлось бы просмотреть при линейном поиске.
Сортировка слиянием
При сортировке слиянием мы разделяем массив пополам до тех пор, пока каждый участок не станет длиной в один элемент. Затем эти участки возвращаются на место (сливаются) в правильном порядке.
Давайте посмотрим на такой массив:

Разделим его пополам:

И будем делить каждую часть пополам, пока не останутся части с одним элементом:

Теперь, когда мы разделили массив на максимально короткие участки, мы сливаем их в правильном порядке.

Сначала мы получаем группы по два отсортированных элемента, потом «собираем» их в группы по четыре элемента и в конце собираем все вместе в отсортированный массив.
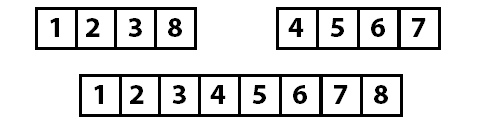
Для работы алгоритма мы должны реализовать следующие операции:
- Операцию для рекурсивного разделения массива на группы (метод Sort ).
- Слияние в правильном порядке (метод Merge ).
Стоит отметить, что в отличие от линейных алгоритмов сортировки, сортировка слиянием будет делить и склеивать массив вне зависимости от того, был он отсортирован изначально или нет. Поэтому, несмотря на то, что в худшем случае он отработает быстрее, чем линейный, в лучшем случае его производительность будет ниже, чем у линейного. Поэтому сортировка слиянием — не самое лучшее решение, когда надо отсортировать частично упорядоченный массив.
Быстрая сортировка
| Сложность | Наилучший случай | В среднем | Наихудший случай |
| Время | O(n·log n) | O(n·log n) | O(n 2 ) |
| Память | O(1) | O(1) | O(1) |
Быстрая сортировка — это еще один алгоритм типа «разделяй и властвуй». Он работает, рекурсивно повторяя следующие шаги:
- Выбрать ключевой индекс и разделить по нему массив на две части. Это можно делать разными способами, но в данной статье мы используем случайное число.
- Переместить все элементы больше ключевого в правую часть массива, а все элементы меньше ключевого — в левую. Теперь ключевой элемент находится в правильной позиции — он больше любого элемента слева и меньше любого элемента справа.
- Повторяем первые два шага, пока массив не будет полностью отсортирован.
Давайте посмотрим на работу алгоритма на следующем массиве:

Сначала мы случайным образом выбираем ключевой элемент:

Теперь, когда мы знаем ключевой индекс (4), мы берем значение, находящееся по этому индексу (6), и переносим значения в массиве так, чтобы все числа больше или равные ключевому были в правой части, а все числа меньше ключевого — в левой. Обратите внимание, что в процессе переноса значений индекс ключевого элемента может измениться (мы увидим это вскоре).
Перемещение значений осуществляется методом partition .

На этом этапе мы знаем, что значение 6 находится на правильной позиции. Теперь мы повторяем этот процесс для правой и левой частей массива.
Мы рекурсивно вызываем метод quicksort на каждой из частей. Ключевым элементом в левой части становится пятерка. При перемещении значений она изменит свой индекс. Главное — помнить, что нам важно именно ключевое значение, а не его индекс.
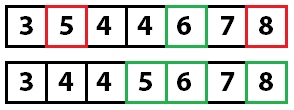
Снова применяем быструю сортировку:
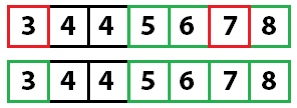
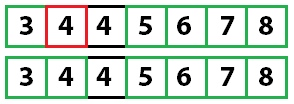
У нас осталось одно неотсортированное значение, а, поскольку мы знаем, что все остальное уже отсортировано, алгоритм завершает работу.
Заключение
На этом мы заканчиваем наш цикл статей по алгоритмам и структурам данных для начинающих. За это время мы рассмотрели связные списки, динамические массивы, двоичное дерево поиска и множества с примерами кода на C#.
Источник



