
Хранение информации




![]()
![]()
Хранение и накопление являются одними из основных действий, осуществляемых над информацией и главным средством обеспечения ее доступности в течение некоторого промежутка времени. В настоящее время определяющим направлением реализации этой операции является концепция базы данных и склада (хранилища) данных.
База данных может быть определена как совокупность взаимосвязанных данных, используемых несколькими пользователями и хранящихся с регулируемой избыточностью. Хранимые данные не зависят от программ пользователей, для модификации и внесения изменений применяется общий управляющий метод.
Банк данных — система, представляющая определенные услуги по хранению и поиску данных определенной группе пользователей по определенной тематике.
Система баз данных — совокупность управляющей системы, прикладного программного обеспечения, базы данных, операционной системы и технических средств, обеспечивающих информационное обслуживание пользователей.
Хранилище данных (ХД, используют также термины Data Warehouse, «склад данных», «информационное хранилище») — это база, хранящая данные, агрегированные по многим измерениям. Основные отличия ХД от БД: агрегирование данных; данные из ХД никогда не удаляются; пополнение ХД происходит на периодической основе; формирование новых агрегатов данных, зависящих от старых — автоматическое; доступ к ХД осуществляется на основе многомерного куба или гиперкуба.
Альтернативой хранилищу данных является концепция витрин данных (Data Mart). Витрины данных — множество тематических БД, содержащих информацию, относящуюся к отдельным информационным аспектам предметной области.
Еще одним важным направлением развития баз данных являются репозитарии. Репозитарий, в упрощенном виде, можно рассматривать просто как базу данных, предназначенную для хранения не пользовательских, а системных данных. Технология репозитариев проистекает из словарей данных, которые по мере обогащения новыми функциями и возможностями приобретали черты инструмента для управления метаданными.
Каждый из участников действия (пользователь, группа пользователей, «физическая память») имеет свое представление об информации
По отношению к пользователям применяют трехуровневое представление для описания предметной области: концептуальное, логическое и внутреннее (физическое).
Концептуальный уровень связан с частным представлением данных группы пользователей в виде внешней схемы, объединяемых общностью используемой информации. Каждый конкретный пользователь работает с частью БД и представляет ее в виде внешней модели. Этот уровень характеризуется разнообразием используемых моделей: модель «сущность-связь» (ER-модель, модель Чена), бинарные и инфологические модели, семантические сети.
Логический уровень является обобщенным представлением данных всех пользователей в абстрактной форме. Используются три вида моделей: иерархические, сетевые и реляционные.
Сетевая модель является моделью объектов-связей, допускающей только бинарные связи «многие к одному» и использует для описания модель ориентированных графов.
Иерархическая модель является разновидностью сетевой, являющейся совокупностью деревьев (лесом).
Реляционная модель использует представление данных в виде таблиц (реляций), в ее основе лежит математическое понятие теоретико-множественного отношения, она базируется на реляционной алгебре и теории отношений.
Физический (внутренний) уровень связан со способом фактического хранения данных в физической памяти ЭВМ. Во многом определяется конкретным методом управления. Основными компонентами физического уровня являются хранимые записи, объединяемые в блоки; указатели, необходимые для поиска данных; данные переполнения; промежутки между блоками; служебная информация.
По наиболее характерным признакам БД можно классифицировать следующим образом:
по способу хранения информации:
по типу пользователя
по характеру использования данных:

В настоящее время при проектировании БД используют два подхода. Первый из них основан на стабильности данных, что обеспечивает наибольшую гибкость и адаптируемость к используемым приложениям. Применение такого подхода целесообразно в тех случаях, когда не предъявляются жесткие требования к эффективности функционирования (объему памяти и продолжительности поиска), существует большое число разнообразных задач с изменяемыми и непредсказуемыми запросами.
Второй подход базируется на стабильности процедур запросов к БД и является предпочтительным при жестких требованиях к эффективности функционирования, особенно это касается быстродействия.
Другим важным аспектом проектирования БД является проблема интеграции и распределения данных. Господствовавшая до недавнего времени концепция интеграции данных при резком увеличении их объема, оказалась несостоятельной. Этот факт, а также увеличение объемов памяти внешних запоминающих устройств при их удешевлении, широкое внедрение сетей передачи данных способствовало внедрению распределенных БД. Распределение данных по месту их использования может осуществляться различными способами:
1.Копируемые данные. Одинаковые копии данных хранятся в различных местах использования, так как это дешевле передачи данных. Модификация данных контролируется централизованно.
2.Подмножество данных. Группы данных, совместимые с исходной базой данных, хранятся отдельно для местной обработки.
3.Реорганизованные данные. Данные в системе интегрируются при передаче на более высокий уровень.
4.Секционированные данные. На различных объектах используются одинаковые структуры, но хранятся разные данные.
5.Данные с отдельной подсхемой. На различных объектах используются различные структуры данных, объединяемые в интегрированную систему.
6.Несовместимые данные. Независимые базы данных, спроектированные без координации, требующие объединения.
Важное влияние на процесс создания БД оказывает внутреннее содержание информации. Существует два направления:
• прикладные БД, ориентированные на конкретные приложения, например, может быть создана БД для учета и контроля поступления материалов;
• предметные БД, ориентированные на конкретный класс данных, например, предметная БД «Материалы», которая может быть использована для различных приложений.
Конкретная реализация системы баз данных с одной стороны определяется спецификой данных предметной области, отраженной в концептуальной модели, а с другой стороны типом конкретной СУБД (МБД), устанавливающей логическую и физическую организацию.
Для работы с БД используется специальный обобщенный инструментарий в виде СУБД (МБД), предназначенный для управления БД и обеспечения интерфейса пользователя.
Основные стандарты СУБД:
• независимость данных на концептуальном, логическом, физическом уровнях;
• универсальность (по отношению к концептуальному и логическому уровням, типу ЭВМ);
• безопасность и целостность данных;
• актуальность и управляемость.
Существуют два основных направления реализации СУБД: программное и аппаратное.
Программная реализация (в дальнейшем СУБД) представляет собой набор программных модулей, работает под управлением конкретной ОС и выполняет следующие функции:
· описание данных на концептуальном и логическом уровнях;
· поиск и ответ на запрос (транзакцию);
· обеспечение безопасности и целостности.
· обеспечивает пользователя следующими языковыми средствами:
o языком описания данных (ЯОД);
o языком манипулирования данными (ЯМД);
o прикладным (встроенным) языком данных (ПЯД, ВЯД).
Аппаратная реализация предусматривает использование так называемых машин баз данных (МБД). Их появление вызвано возросшими объемами информации и требованиями к скорости доступа. Слово «машина» в термине МБД означает вспомогательный периферийный процессор. Термин «компьютер БД» — автономный процессор баз данных или процессор, поддерживающий СУБД.
Основные направления МБД:
• фильтры данных и др.
Совокупность процедур проектирования БД можно объединить в четыре этапа. На этапе формулирования и анализа требований устанавливаются цели организации, определяются требования к БД. Эти требования документируются в форме, доступной конечному пользователю и проектировщику БД. Обычно при этом используется методика интервьюирования персонала различных уровней управления.
Этап концептуального проектирования заключается в описании и синтезе информационных требований пользователей в первоначальный проект БД. Результатом этого этапа является высокоуровневое представление информационных требований пользователей на основе различных подходов.
В процессе логического проектирования высокоуровневое представление данных преобразуется в структуре используемой СУБД. Полученная логическая структура БД может быть оценена количественно с помощью различных характеристик (число обращений к логическим записям, объем данных в каждом приложении, общий объем данных и т.д.). На основе этих оценок логическая структура может быть усовершенствована с целью достижения большей эффективности.
На этапе физического проектирования решаются вопросы, связанные с производительностью системы, определяются структуры хранения данных и методы доступа.
Весь процесс проектирования БД является итеративным, при этом каждый этап рассматривается как совокупность итеративных процедур, в результате выполнения которых получают соответствующую модель.
Взаимодействие между этапами проектирования и словарной системой необходимо рассматривать отдельно. Процедуры проектирования могут использоваться независимо в случае отсутствия словарной системы. Сама словарная система может рассматриваться как элемент автоматизации проектирования.
Этап расчленения БД связан с разбиением ее на разделы и синтезом различных приложений на основе модели. Основными факторами, определяющими методику расчленения, являются: размер каждого раздела (допустимые размеры); модели и частоты использования приложений; структурная совместимость; факторы производительности БД. Связь между разделом БД и приложениями характеризуется идентификатором типа приложения, идентификатором узла сети, частотой использования приложения и его моделью.
Модели приложений могут быть классифицированы следующим образом:
1. Приложения, использующие единственный файл.
2. Приложения, использующие несколько файлов, в том числе:
• допускающие независимую параллельную обработку;
• допускающие синхронизированную обработку.
Сложность реализации этапа размещения БД определяется многовариантностью. Поэтому на практике рекомендуется в первую очередь рассмотреть возможность использования определенных допущений, упрощающих функции СУБД, например, допустимость временного рассогласования БД, осуществление процедуры обновления БД из одного узла и др. Такие допущения оказывают большое влияние на выбор СУБД и рассматриваемую фазу проектирования.
Средства проектирования и оценочные критерии используются на всех стадиях разработки. Любой метод проектирования (аналитический, эвристический, процедурный), реализованный в виде программы, становится инструментальным средством проектирования, практически не подверженным влиянию стиля проектирования.
В настоящее время неопределенность при выборе критериев является наиболее слабым местом в проектировании БД. Это связано с трудностью описания и идентификации бесконечного числа альтернативных решений. При этом следует иметь в виду, что существует много признаков оптимальности, являющихся неизмеримыми, им трудно дать количественную оценку или представить их в виде целевой функции. Поэтому оценочные критерии принято делить на количественные и качественные. Наиболее часто используемые критерии оценки БД, сгруппированные в такие категории, представлены ниже.
Количественные критерии: время, необходимое для ответа на вопрос, стоимость модификации, стоимость памяти, время на создание, стоимость на реорганизацию.
Качественные критерии: гибкость, адаптивность, доступность для новых пользователей, совместимость с другими системами, возможность конвертирования в другую вычислительную среду, возможность восстановления, возможность распределения и расширения.
Трудность в оценке проектных решений связана также с различной чувствительностью и временем действия критериев. Например, критерий эффективности обычно является краткосрочным и чрезвычайно чувствительным к проводимым изменениям, а такие понятия, как адаптируемость и конвертируемость, проявляются на длительных временных интервалах и менее чувствительны к воздействию внешней среды.
Предназначение склада данных — информационная поддержка принятия решений, а не оперативная обработка данных. Потому база данных и склад данных не являются одинаковыми понятиями.
Источник
Логика хранения данных
Логическая структура — то, с чем работает операционная система компьютера. Это всегда иерархия: диск ^ раздел ^ каталог ^ файл. Со стороны интерфейса любой накопитель представляется последовательностью логических блоков. При чтении компьютер запрашивает у накопителя блок с определенным порядковым номером и получает в ответ содержимое этого блока в виде последовательности байтов. При записи, наоборот, последовательность байтов посылается в указанный блок. Границей между аппаратным и логическим уровнями можно считать интерфейсный кабель.
С самого начала условились, что стандартная длина блока составляет 512 байтов. Как раз таков был размер физических секторов на дискетах и первых винчестерах — отсюда и принято говорить о секторах. Хотя впоследствии производители компьютерного «железа» и разработчики файловых систем стали оперировать более крупными порциями данных (кластерами, блоками), в основе все равно лежит сектор размером 512 байтов.
В действительности на винчестере полный объем физического сектора равен 571 байту. Из них 512 байтов предназначены для записи данных (data), а оставшиеся 59 байтов — служебные сведения о внутреннем номере сектора, контрольные суммы и т. д. Часть этой информации записывается в ходе низкоуровневой разметки диска еще на заводе, частью «заведует» микропрограмма. Через стандартный интерфейс скрытые 59 байтов недоступны. Так что «видимая» длина сектора — всегда 512 байтов.
Разделы
Верхний уровень логической структуры диска — разделы (partitions). Идея разделов применима к жестким дискам: диск разбивается на несколько частей, каждая из которых несет свою файловую систему и далее представляется ОС вполне самостоятельным носителем.
Флеш-диски и оптические диски обычно «пропускают» этот уровень. В сущности такой носитель весь является одним разделом и несет только файловую систему.
Главная загрузочная запись и таблица разделов
Начальный сектор диска содержит главную загрузочную запись (англ. master boot record, MBR). Синоним — основная загрузочная запись. MBR состоит из программного кода загрузчика, таблицы разделов (partition table) и заканчивается сигнатурой (подписью). Все вместе это занимает 512 байтов. Структура главной загрузочной записи приведена в табл.
| Смещение от начала диска | Длина, байт | Содержание |
| Код программы-загрузчика | ||
| 01BE | Таблица разделов: Раздел 1 | |
| 01CE | Таблица разделов: Раздел 2 | |
| 01DE | Таблица разделов: Раздел 3 | |
| 01EE | Таблица разделов: Раздел 4 | |
| 01FE | Сигнатура MBR (всегда AA55) |
Первые 446 байтов отводятся под код загрузчика (Boot Record). При загрузке с диска эту короткую программу считывает и выполняет BIOS компьютера. Код загрузчика зависит от того, какой программой создавалась главная загрузочная запись. Например, если вы форматировали (точнее, инициализировали) диск стандартными средствами Windows, код загрузчика один, если с помощью Partition Magic — другой, если с помощью программ семейства Acronis — третий. Стандартным считается загрузчик, записываемый утилитой fdisk или установщиком Windows.
В адреса 01B8-01BB программа, которой форматировался диск, может записать сигнатуру диска. Например, ОС семейства Windows NT по этим значениям «запоминают» диск, который однажды подключался к системе, и «узнают» его, даже если потом он будет переставлен на другой канал IDE или SATA.
Следующие четыре группы по 16 байтов служат для записи сведений о разделах диска. Вместе они образуют таблицу разделов (Partition Table). Пока на диске не создавались разделы, все эти группы содержат нули. На диске можно создать максимум 4 основных (basic) раздела — больше структурой MBR не предусмотрено. Каждая группа состоит из 10 полей (табл).
Таблица Структура поля таблицы разделов
| Смещение от начала группы | Длина, байт | Описание |
| Флаг активности раздела (80 — активный, 0 — не активный) | ||
| Начало раздела — головка H | ||
| Начало раздела — сектор S (биты 0-5), цилиндр C (биты 6,7) | ||
| Начало раздела — цилиндр C (старшие биты 8,9 хранятся в предыдущем байте) | ||
| Код типа раздела | ||
| Конец раздела — головка H | ||
| Конец раздела — сектор S (биты 0-5), цилиндр C (биты 6,7) | ||
| Конец раздела — цилиндр C (старшие биты 8,9 хранятся в предыдущем байте) | ||
| Смещение первого сектора раздела в координатах LBA | ||
| 000C | Количество секторов раздела |
Нулевой байт — флаг активности раздела. Из всех разделов диска активным может быть только один (или ни одного). При загрузке компьютера BIOS, прочитав и выполнив код загрузчика MBR, будет искать «продолжение», т. е. загрузчик операционной системы, в активном разделе. Больше этот флаг ни на что не влияет.
Следующие 3 байта содержат координаты начала раздела, а байты с пятого по седьмой — координаты его конца. Координаты выражены через значения CHS.
Относительно головок, секторов и цилиндров придется сделать отступление. Исторически сначала появилась «трехмерная» адресация секторов на жестких дисках, или система адресации CHS. В ней каждый сектор обозначался тремя числами: C (номером цилиндра, т. е. дорожек, лежащих одна под другой), H (номером головки, т. е. пластины) и S (номером сектора на дорожке). Это отражало реальную «геометрию» винчестеров того времени (рис. 2.8).
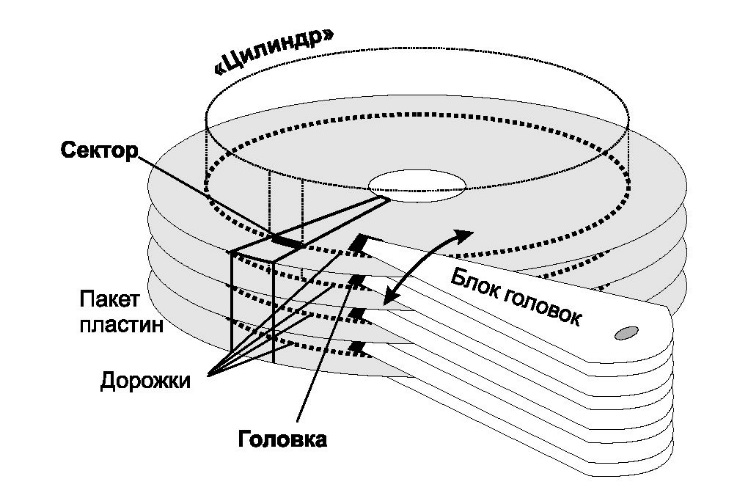
Рис Геометрия винчестера: дорожки, головки и секторы
Тогда же сложилась спецификация таблицы разделов, которая действует и до сих пор. В ней под номер цилиндра C отведено 10 битов, и цилиндров может быть не более 2 10 = 1024. Под номер сектора S отдано 6 битов, и секторов может быть не более 2 6 — 1 = 63 (нумерация секторов начинается с единицы). Соответственно, головок может быть не более 2 8 = 256. Итого, адресуемый объем диска теоретически не может превышать 1024 • 63 • 256 • 512 = 8 455 716 864 байта, чуть больше 7,8 Гбайт.
В дальнейшем, когда емкость винчестеров превысила 7 Гбайт, была принята «линейная» адресация LBA (Logical Block Addressing, адресация логических блоков). В ней все секторы «выстроены в ряд», и у сектора есть только порядковый номер. При таком типе адресации данные считываются логическими блоками, состоящими из нескольких секторов.
Адресация LBA преобразуется в CHS и наоборот. Примерно так же на строевом смотре воинское подразделение из «коробки» в несколько шеренг развертывается в колонну или шеренгу по одному, а затем вновь выстраивается в «коробку». За нулевой принимается блок, который начинается в первом секторе нулевой головки нулевого цилиндра. Блоки (секторы) LBA нумеруются с нуля, а не с единицы, как секторы CHS.
Если начало раздела лежит за пределами адресации CHS, то в соответствующие поля таблицы разделов записываются максимально возможные значения: C = 1023 (3FFh), H = 255 (FFh), S = 63 (3Fh), а для обращения к разделу система будет применять адресацию LBA.
Если в MBR под запись каждого адреса LBA отводится 4 байта (32 бита), то через LBA теоретически можно адресовать до 2 32 • 512 = 2 199 023 255 552 байта (около 2 Тбайт).
Четвертый байт — код (идентификатор) типа раздела. Если значение этого байта равно 00, считается, что такого раздела не существует, и его содержимое игнорируется. Любое другое значение указывает на раздел определенного типа. Некоторые идентификаторы приведены в табл.
Таблица Коды типа раздела
| Код | Тип раздела |
| Раздел отсутствует | |
| FAT12, CHS | |
| FAT16 (от 32 680 до 65 535 секторов или 16-33 Мбайт), CHS | |
| Расширенный раздел (extended partition), CHS | |
| Код | Тип раздела |
| FAT16 (до 32 680 секторов или до 16 Мбайт), CHS | |
| NTFS или exFAT | |
| 0B | FAT32, CHS |
| 0C | FAT32, LBA |
| 0E | FAT16, LBA |
| 0F | Расширенный раздел (extended partition), LBA |
| Динамический диск Windows NT, LBA | |
| Linux swap | |
| Linux native | |
| NTFS массива RAID0 | |
| B7 | NTFS master-раздела массива RAID1 |
| C7 | NTFS slave-раздела массива RAID1 |
Добавление к коду типа раздела шестнадцатеричного числа 10 делает раздел «скрытым» (hidden). Например, если идентификатор 0C указывает на раздел FAT32, то идентификатор 0C + 10 = 1C соответствует скрытому разделу FAT32.
Скрытые разделы недоступны большинству ОС — для них это «раздел неизвестного типа», следовательно, он не должен содержать файловую систему. Однако в скрытых разделах часто располагают средства восстановления системы. Например, Зона безопасности Acronis является скрытым разделом FAT32, а на ноутбуках Acer скрытый раздел несет утилиту e -Recovery (специализированная ОС на базе Linux) и образ системного диска. В таком случае программа, создающая скрытый раздел, заменяет стандартный загрузчик MBR своим, модифицированным. Такой «хитрый» загрузчик предлагает в процессе загрузки нажать какое-либо сочетание клавиш, чтобы загрузить компьютер со скрытого раздела.
Если на диске нужно создать больше четырех разделов, применяется специальный тип раздела с кодом 05 — расширенный раздел (Extended Partition). В терминологии Windows отформатированные расширенные разделы называются логическими дисками.
Расширенный раздел отличается от всех других типов разделов. Он описывает не сам раздел, а область пространства накопителя, в которой начинается описание логических дисков. Сектор, который указан в таблице разделов MBR как начальный сектор расширенного раздела, фактически содержит еще одну загрузочную запись — Extended Boot Record (EBR). Загрузочного кода в ней нет, есть только таблица разделов из двух записей и сигнатура.
Записи EBR устроены точно так же, как записи таблицы разделов в MBR. Если логический диск, на который ссылается указатель, занимает не все пространство, то в EBR заполняется второй элемент — указатель на следующий расширенный раздел. Он вновь описывает оставшееся пространство как Extended Partition и указывает на следующую расширенную загрузочную запись (EBR). В секторе, на который ссылается эта запись, точно так же описывается один раздел (логический диск) и, если осталось место, делается очередная запись об Extended Partition. Так продолжается до тех пор, пока пространство не будет разделено.
Схема на рис. поясняет соотношение между основными и расширенными разделами. В качестве примера левый диск разбит на 3 основных раздела. На правом создано два основных раздела и расширенный, в котором размещены 3 логических диска.
Все записи о расширенных разделах образуют цепь (Extended Partition Chain), в которой от дискового пространства последовательно отрезаются фрагменты (логические диски). Ошибка в любом элементе этой цепи приводит к ее обрыву. Все разделы, которые описаны после обрыва цепи, операционная система найти не сможет. Занимаемое этими расширенными разделами пространство она будет считать незанятым.
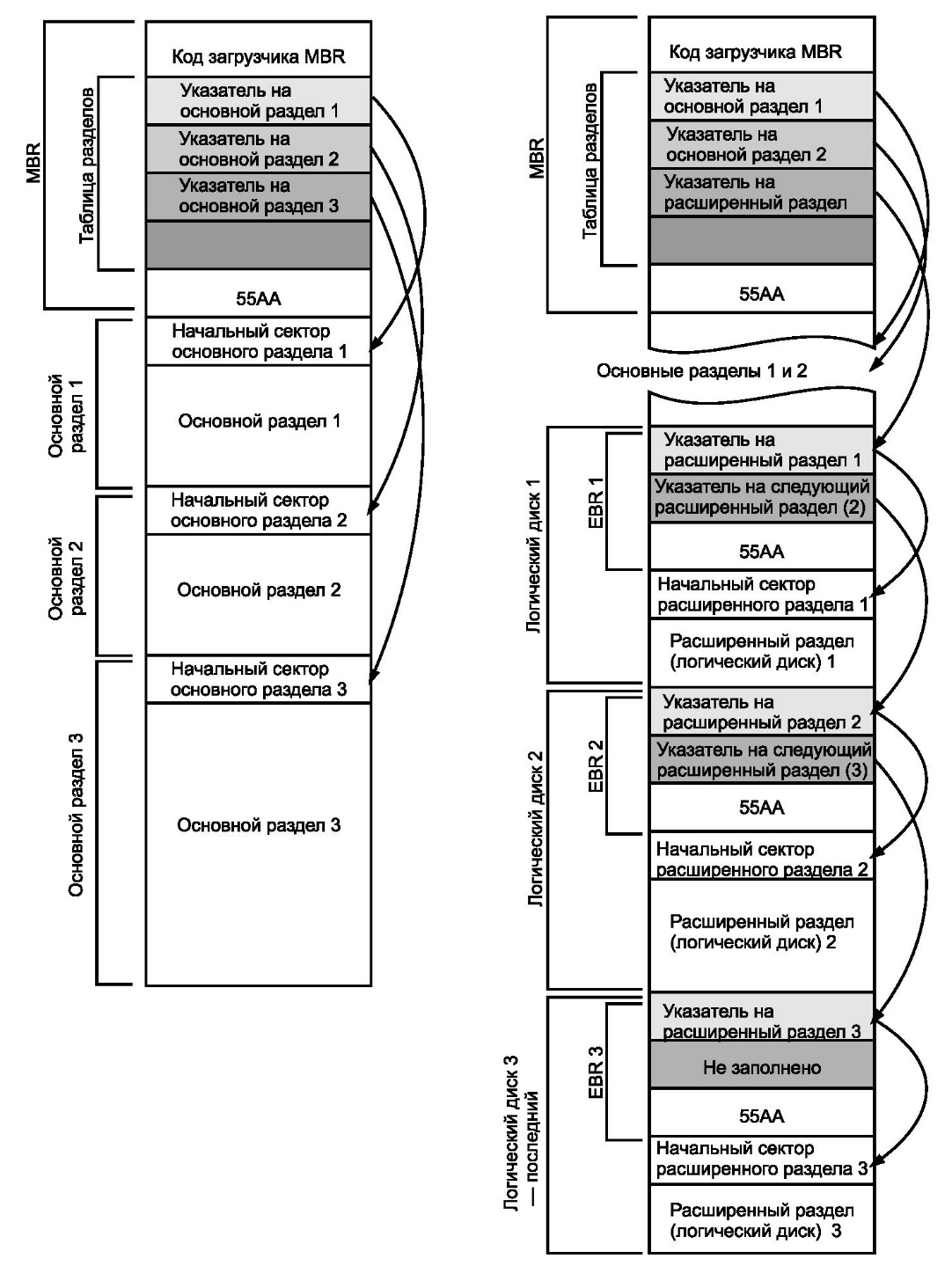
Рис. Основные и расширенные разделы
GPT — таблица разделов GUID
Как уже сказано, диски объемом более 2 Тбайт на наших глазах становятся реальностью. Что же нужно, чтобы компьютер смог работать с такими винчестерами?
□ Контроллер дисков и BIOS материнской платы должны, как минимум, поддерживать 48-битную адресацию LBA. Когда под номер сектора отводится 48 битов, можно адресовать на диске до 2 48
2,8 • 10 14 байтов, т. е. почти 300 терабайт. Эта поддержка появляется в «железе», выпущенном после 2008 г. В идеале материнская плата должна соответствовать спецификации Extensible Firmware Interface (EFI), но пока это «экзотика».
□ На диске должна быть создана таблица разделов нового типа — GPT (англ. GUID Partition Table, таблица разделов GUID).
□ Операционная система должна «уметь» работать с таблицей разделов GPT. Таковы Windows 7, 64-битные предыдущие версии Windows и некоторые сборки Linux.
GUID (Globally Unique Identifier, глобально уникальный идентификатор)- это концепция, согласно которой каждой цифровой «железке» и программному компоненту в мире желательно присвоить статистически уникальный 128-битный идентификатор. Активное участие в ее разработке и продвижении принимают корпорация Microsoft и другие гиганты индустрии.
Одно отражение идея GUID нашла в сетевом протоколе IPv6. В результате у каждого компьютера на Земле появляется уникальный IP-адрес, адресация в цифровых сетях становится довольно простой и прозрачной, а многие проблемы отпадают сами собой.
Другое воплощение идеи — архитектура EFI (Extensible Firmware Interface, расширяемый интерфейс микропрограмм). Эта архитектура призвана заменить BIOS при загрузке компьютеров и взаимодействии аппаратных компонентов.
Попросту говоря, BIOS обращается к диску, подключенному к указанному порту, потом загрузчик MBR передает загрузку загрузочному сектору того раздела, который помечен как активный, последний отправляет к загрузочным файлам ОС и т. д. Материнская плата с EFI сразу же обратится к тому разделу, уникальный идентификатор (GUID) которого прописан в ее настройках. Для этого на диске и нужна структура GPT.
В нулевом секторе диска с GPT все равно находится MBR. Эта запись делается лишь из соображений совместимости и безопасности. Поэтому ее называют наследственной или защитной (Protective MBR). ОС и утилиты, поддерживающие GPT, эту запись игнорируют.
В Protective MBR описан всего один раздел, занимающий весь диск. Разделу присвоен тип 00EE. Благодаря этому старые ОС и программы, не поддерживающие GPT, «видят» через MBR один раздел неизвестного им типа и не пытаются что- либо писать на диск.
Следующие 33 сектора занимает структура GPT. Общая схема диска с GPT приведена на рис.
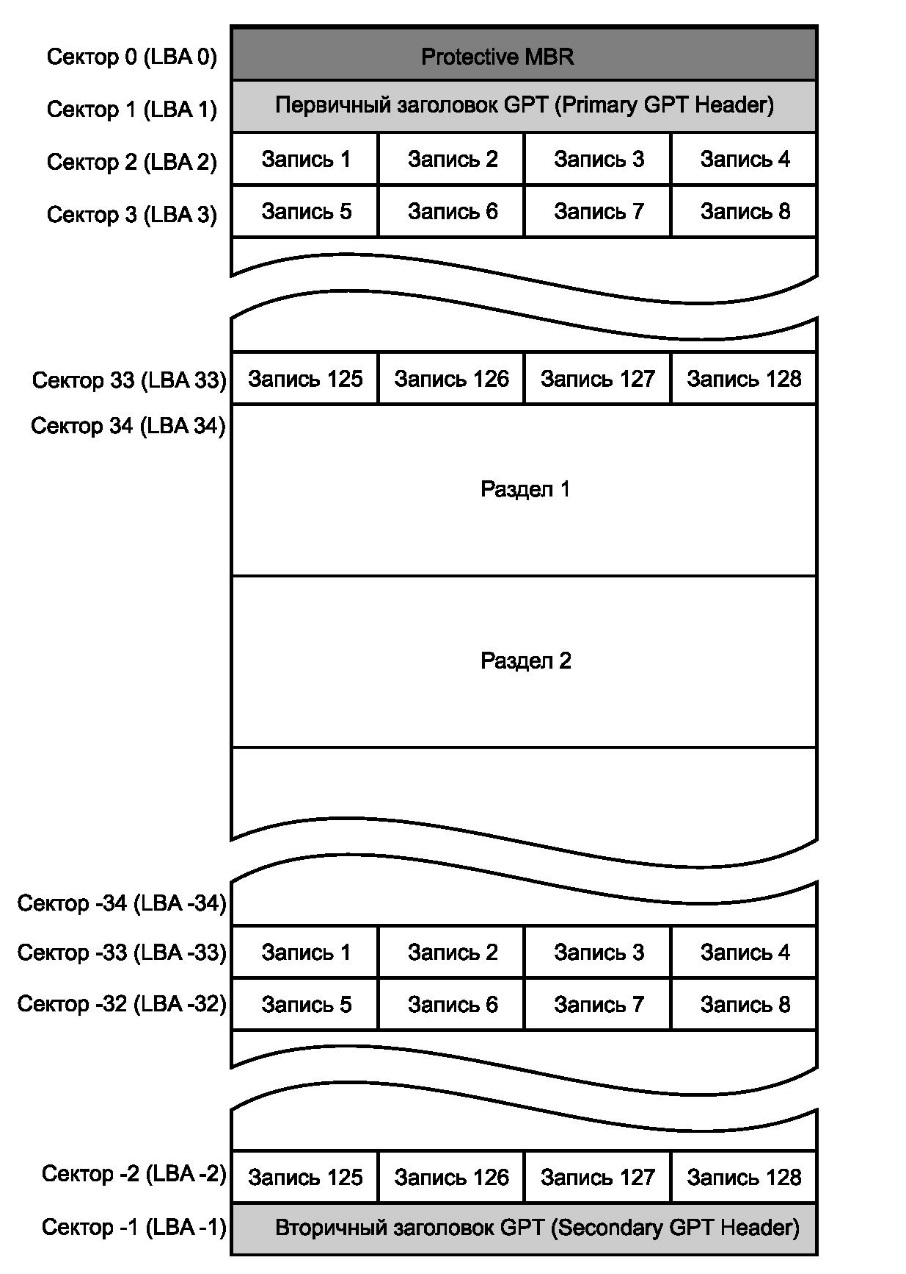
В первом секторе расположен первичный заголовок GPT. Он как раз и содержит GUID диска, сведения о собственном размере и ссылку на расположение вторичного (запасного) оглавления и запасной таблицы разделов, которые всегда находятся в последних секторах диска.
Кроме того, в заголовке хранятся две контрольные суммы (CRC32): самого заголовка и таблицы разделов. При загрузке компьютера микропрограмма EFI проверяет по этим контрольным суммам целостность GPT.
Секторы со второго по тридцать третий занимает таблица разделов. Она состоит из записей длиной по 128 байтов. Всего таких записей и, соответственно, разделов на диске может быть не более 128.
Первые 16 байтов записи содержат GUID типа раздела. Это напоминает код типа раздела в MBR. Например, GUID системного раздела EFI имеет вид C12A7328-
F81F-11D2-BA4B-00A0C93EC93B. Следующие 16 байтов — уникальный идентификатор (GUID) конкретного раздела. Фактически, это его «серийный номер». Далее могут быть записаны данные о начале и конце раздела в 64-битных координатах LBA (не обязательно). Затем следуют метка (имя) и атрибуты раздела.
В конце диска расположена резервная копия GPT — вторичный заголовок (Secondary GPT Header) и точно такая же таблица разделов. Номера секторов здесь обозначают отрицательными числами: -1 — последний сектор, -2 — предпоследний и т. д.
Простое редактирование GPT с помощью HEX-редакторов без вычисления и обновления контрольных сумм приводит к тому, что содержимое заголовка или таблицы перестает соответствовать контрольным суммам. Если микропрограмма EFI при проверке выявит такое расхождение, она перезапишет Primary GPT из вторичной копии. Если же обе записи GPT будут содержать неверные контрольные суммы, доступ к диску станет невозможным.
Таким образом, GPT обладает отказоустойчивостью и позволяет создать на диске до 128 основных разделов.
Дата добавления: 2017-05-18 ; просмотров: 997 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
Источник



