
- Краткое объяснение кодирования текстовой информации. Информатика
- Содержание:
- Кодирование текстовой информации
- Кодирование текстовой информации и компьютеры
- Кодирование текстовой информации и таблицы кодировок
- Кодирование текстовой информации
- Основные способы кодирования текстовой информации
- Стенография
- Готовые работы на аналогичную тему
- Криптография
- Числовое кодирование текстовой информации
- Кодирование информации — основные виды, способы и правила
- Трактовка понятий
- Двоичная методика
- Текстовое значение
- Растровое изображение
- Звуки и их разрядность
- Машинные команды
- Заключение
Краткое объяснение кодирования текстовой информации. Информатика
Содержание:
Кодирование текстовой информации — очень распространенное явление. Один и тот же текст может быть закодирован в нескольких форматах. Принято считать, что кодирование текстовой информации появилось с приходом компьютеров. Это и так и не так одновременно. Кодировка в том виде, в котором мы ее знаем, действительно к нам пришла с приходом компьютеров. Но над самим процессом кодирования люди бьются уже много сотен лет. Ведь, по большому счету, сама письменность уже является способом закодировать человеческую речь, для ее дальнейшего использования. Вот и получается, что любая окружающая нас информация никогда не бывает представленной в чистом виде, потому что она уже каким-то образом закодирована. Но сейчас не об этом.
Кодирование текстовой информации
Самый распространенный способ кодирования текстовой информации — это ее двоичное представление, которое сплошь и рядом используется в каждом компьютере, роботе, станке и т. д. Все кодируется в виде слов в двоичном представлении.
Сама технология двоичного представления информации зародилась еще задолго до появления первых компьютеров. Среди первых устройств, которые использовали двоичный метод кодирования, был аппарат Бодо — телеграфный аппарат, который кодировал информацию в 5 битах в двоичном представлении. Суть кодировки заключалась в простой последовательности электрических импульсов:
- 0 — импульс отсутствует;
- 1 — импульс присутствует.
В компьютерный мир такая кодировка пришла вместе с персонализацией самих компьютеров. То есть в первых компьютерах не было такой кодировки. Но как только компьютеры стали уходить «в массы», то резко обнаружилась потребность обрабатывать компьютерами большое количество именно текстовой информации, которую нужно было как-то кодировать. Тенденция обрабатывать большое количество текстовой информации сохранилась и в современных устройствах.
Так получилось, что двоичное кодирование в компьютерах связано только с двумя символами «0» и «1», которые выстраиваются в определенной логической последовательности. А сам язык подобной кодировки стал называться машинным.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Мы вводим текст в компьютер при помощи клавиатуры, символы которой мы прекрасно понимаем. Нажимая на какую-то букву, мы отправляем в оперативную память компьютера двоичное представление нажатых клавиш. Каждый отдельный символ будет представлен 8-битной кодировкой. Например буква «А» — это «11000000». Получается, что один символ — это 1 байт или 8 бит. При такой кодировке, путем нехитрых подсчетов можно посчитать, что мы можем зашифровать 256 символов. Для кодирования текстовой информации данного количества символов более чем предостаточно.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Кодирование текстовой информации и таблицы кодировок
Таблица кодировки — это место, где прописано какому символу какой код относится. Все таблицы кодировки являются согласованными — это нужно, чтобы не возникало путаницы между документами, закодированными по одной таблице, но на разных устройствах.
На сегодняшний день существует множество таблиц кодировок. Из-за этого часто возникают проблемы с переносом текстовых документов между устройствами. Так получается, что если текстовая информация была закодирована по одной какой-то таблице, то и раскодирована она может быть только по этой таблице. Если попытаться раскодировать другой таблицей, то в результате получим только набор непонятных символов, но никак не читабельный текст.
Источник
Кодирование текстовой информации
Вы будете перенаправлены на Автор24
Чаще всего кодированию подвергаются тексты, написанные на естественных языках (русском, немецком и др.).
Основные способы кодирования текстовой информации
Существует несколько основных способов кодирования текстовой информации:
- графический, в котором текстовая информация кодируется путем использования специальных рисунков или знаков;
- символьный, в котором тексты кодируются с использованием символов того же алфавита, на котором написан исходник;
- числовой, в котором текстовая информация кодируется с помощью чисел.
Процесс чтения текста представляет собой процесс, обратный его написанию, в результате которого письменный текст преобразуется в устную речь. Чтение – это ничто иное, как декодирование письменного текста.
А сейчас обратите внимание на то, что существует много способов кодирования одного и того же текста на одном и том же языке.
Поскольку мы русские, то и текст привыкли записывать с помощью алфавита своего родного языка. Однако тот же самый текст можно записать, используя латинские буквы. Иногда это приходится делать, когда мы отправляем SMS по мобильному телефону, клавиатура которого не содержит русских букв, или же электронное письмо на русском языке за границу, если у адресата нет русифицированного программного обеспечения. Например, фразу «Здравствуй, дорогой Саша!» можно записать как: «Zdravstvui, dorogoi Sasha!».
Стенография
Стенография — это один из способов кодирования текстовой информации с помощью специальных знаков. Она представляет собой быстрый способ записи устной речи. Навыками стенографии могут владеть далеко не все, а лишь немногие специально обученные люди, которых называют стенографистами. Эти люди успевают записывать текст синхронно с речью выступающего человека, что, на наш взгляд, достаточно сложно. Однако для них это не проблема, поскольку в стенограмме целое слово или сочетание букв могут обозначаться одним знаком. Скорость стенографического письма превосходит скорость обычного в $4-7$ раз. Расшифровать (декодировать) стенограмму может только сам стенографист.
Готовые работы на аналогичную тему
На рисунке представлен пример стенографии, в которой написано следущее: «Говорить умеют все люди на свете. Даже у самых примитивных племен есть речь. Язык — это нечто всеобщее и самое человеческое, что есть на свете»:
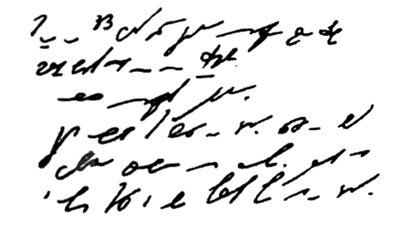
Стенография позволяет не только вести синхронную запись устной речи, но и рационализировать технику письма.
Приведёнными примерами мы проиллюстрировали важное правило: для кодирования одной и той же информации можно использовать разные способы, при этом их выбор будет зависеть от цели кодирования, условий и имеющихся средств.
Если нам нужно записать текст в темпе речи, сделаем это с помощью стенографии; если нужно передать текст за границу, воспользуемся латинским алфавитом; если необходимо представить текст в виде, понятном для грамотного русского человека, запишем его по всем правилам грамматики русского языка.
Также немаловажен выбор способа кодирования информации, который, в свою очередь, может быть связан с предполагаемым способом её обработки.
Рассмотрим пример представления чисел количественной информации. Используя буквы русского алфавита, можно записать число «тридцать пять». Используя же алфавит арабской десятичной системы счисления, запишем: $35$. Допустим нам необходимо произвести вычисления. Естественно, что для выполнения расчётов мы выберем удобную для нас запись числа арабскими цифрами, хотя можно примеры описывать и словами, но это будет довольно громоздко и не практично.
Заметим, что приведенные выше записи одного и того же числа используют разные языки: первая — естественный русский язык, вторая — формальный язык математики, не имеющий национальной принадлежности. Переход от представления на естественном языке к представлению на формальном языке можно также рассматривать как кодирование.
Криптография
В некоторых случаях возникает потребность засекречивания текста сообщения или документа, для того чтобы его не смогли прочитать те, кому не положено. Это называется защитой от несанкционированного доступа. В таком случае секретный текст шифруется. В давние времена шифрование называлось тайнописью.
Шифрование представляет собой процесс превращения открытого текста в зашифрованный, а дешифрование — процесс обратного преобразования, при котором восстанавливается исходный текст. Шифрование — это тоже кодирование, но с засекреченным методом, известным только источнику и адресату. Методами шифрования занимается наука криптография.
Криптография — это наука о методах и принципах передачи и приема зашифрованной с помощью специальных ключей информации. Ключ — секретная информация, используемая криптографическим алгоритмом при шифровании/расшифровке сообщений.
Числовое кодирование текстовой информации
В каждом национальном языке имеется свой алфавит, который состоит из определенного набора букв, следующих друг за другом, а значит и имеющих свой порядковый номер.
Каждой букве сопоставляется целое положительное число, которое называют кодом символа. Именно этот код и будет хранить память компьютера, а при выводе на экран или бумагу преобразовывать в соответствующий ему символ. Помимо кодов самих символов в памяти компьютера хранится и информация о том, какие именно данные закодированы в конкретной области памяти. Это необходимо для различия представленной информации в памяти компьютера (числа и символы).
Используя соответствия букв алфавита с их числовыми кодами, можно сформировать специальные таблицы кодирования. Иначе можно сказать, что символы конкретного алфавита имеют свои числовые коды в соответствии с определенной таблицей кодирования.
Однако, как известно, алфавитов в мире большое множество (английский, русский, китайский и др.). Соответственно возникает вопрос, каким образом можно закодировать все используемые на компьютере алфавиты.
Чтобы ответить на данный вопрос, нам придется заглянуть назад в прошлое.
В $60$-х годах прошлого века в американском национальном институте стандартизации (ANSI) была разработана специальная таблица кодирования символов, которая затем стала использоваться во всех операционных системах. Эта таблица называется ASCII (American Standard Code for Information Interchange, что означает в переводе с английского «американский стандартный код для обмена информацией»).
В данной таблице представлен $7$-битный стандарт кодирования, при использовании которого компьютер может записать каждый символ в одну $7$-битную ячейку запоминающего устройства. При этом известно, что в ячейке, состоящей из $7$ битов, можно сохранять $128$ различных состояний. В стандарте ASCII каждому из этих $128$ состояний соответствует какая-то буква, знак препинания или же специальный символ.
В процессе развития вычислительной техники стало ясно, что $7$-битный стандарт кодирования достаточно мал, поскольку в $128$ состояниях $7$-битной ячейки нельзя закодировать буквы всех письменностей, имеющихся в мире.
Чтобы решить эту проблему, разработчики программного обеспечения начали создавать собственные 8-битные стандарты кодировки текста. За счет дополнительного бита диапазон кодирования в них был расширен до $256$ символов. Во избежание путаницы, первые $128$ символов в таких кодировках, как правило, соответствуют стандарту ASCII. Оставшиеся $128$ — реализуют региональные языковые особенности.
Как мы знаем национальных алфавитов огромное количество, поэтому и расширенные таблицы ASCII-кодов представлены множеством вариантов. Так для русского языка существует также несколько вариантов, наиболее распространенные Windows-$1251$ и Koi8-r. Большое количество вариантов кодировочных таблиц создает определенные трудности. К примеру, мы отправляем письмо, представленное в одной кодировке, а получатель при этом пытается прочесть его в другой. В результате на экране у него появляется непонятная абракадабра, что говорит о том, что получателю для прочтения письма требуется применить иную кодировочную таблицу.
Существует и другая проблема, которая заключается в том, что алфавиты некоторых языков содержат слишком много символов, которые не позволяют помещаться им в отведенные позиции с $128$ до $255$ однобайтовой кодировки.
Следующая проблема возникает тогда, когда в тексте используют несколько языков (например, русский, английский и немецкий). Нельзя же использовать обе таблицы сразу.
Для решения этих проблем в начале $90$-х годов прошлого столетия был разработан новый стандарт кодирования символов, который назвали Unicode. С помощью этого стандарта стало возможным использование в одном тексте любых языков и символов.
Данный стандарт для кодирования символов предоставляет $31$ бит, что составляет $4$ байта за минусом $1$ бита. Количество возможных комбинаций при использовании данной кодировочной таблицы очень велико: $231 = 2 \ 147 \ 483 \ 684$ (т.е. более $2$ млрд.). Это возможно стало в связи с тем, что Unicode описывает алфавиты всех известных языков, даже «мертвых» и выдуманных, включает многие математические и другие специальные символы. И все-таки информационная емкость $31$-битового Unicode слишком велика, И как следствие, наиболее часто используют именно сокращенную $16$-битовую версию ($216 = 65 \ 536$ значений), в которой представлены все современные алфавиты. В Unicode первые $128$ кодов совпадают с таблицей ASCII.
Источник
Кодирование информации — основные виды, способы и правила
Информация бывает разных видов, таких как запах, вкус, звук; символы и знаки. В различных отраслях науки, техники и культуры применяются особые формы и методики для кодирования и записи информации.
Рассмотрим, например, персональные компьютеры, которые предназначены для обработки графических изображений, воспроизведения музыки и видеофайлов, организации видео конференций, научных расчетов. Для предоставления данных в виде, понимаемом компьютерами, проводится кодирование информации путём составления специальной модели явления либо объекта. Именно процесс преобразования сообщения в комбинацию символов называется кодированием.
- Числовой способ — с помощью чисел.
- Символьный способ — информация кодируется с помощью символов того же алфавита, что и исходящий текст.
- Графический способ — информация кодируется с помощью рисунков или значков.
Системы счисления делятся на позиционные и непозиционные. Пример непозиционной системы счисления — римская: несколько чисел приняты за основные (например, I, V, X, L, C, D, M), а остальные получаются из основных путем сложения (как VI, VII) или вычитания (как IV, IX). В непозиционных системах счисления от положения цифры в записи числа не зависит величина, которую она обозначает.

Трактовка понятий
Человеческие мысли выражаются в виде текста, который состоит из слов. Подобное представление информации называется алфавитным, так как основа языка — алфавит. Он считается конечным набором различных знаков любой природы. Их используют для составления сообщений.
Вам известно что для обозначения количества мы пользуемся цифрами, для обозначения звуков на письме буквами. Можно сказать что цифры и буквы это коды. Одна и тажа информация может быть закодирована по разному. Например китайские и японские иероглифы являются символами которыми кодируется буква или слово. Основу любого языка составляет алфавит — конечный набор различных знаков (символов) любой природы, из которых складывается сообщение на данном языке. То есть символизация информации – это описание объектов или явлений с помощью символов того или иного алфавита. Под мощностью алфавита понимают количество символов, составляющий данный алфавит, что в свою очередь определяет количество возможных комбинаций (слов) которые можно составить из символов данного алфавита в соответствии с определенными правилами.
Как правило представления сообщения, подбираются так что бы его передача была как можно быстрее и надежней, а его обработка была как можно более удобной для адресата. Одно и тоже сообщение можно кодировать по разному. Одной систем кодирования является азбука. Можно кодировать и звуки одна из таких систем кодирования — ноты. Хранить можно не только текстовую и звуковую информацию, в виде кодов хранятся и изображения. Если рассмотреть рисунок через увеличительное стекло то видно что он состоит из точек. Координаты каждой точки можно запомнить в виде чисел. Цвет каждой точки можно запомнить так же в виде чисел. Такие числа могут храниться в памяти компьютера и передаваться на расстояния.
Чтобы зашифровать данные, необходимо знать правила записи кодов (условные обозначения информации). Понятие кодирование связано с преобразованием сообщений в комбинацию символов с учётом кодов. При общении люди используют русский либо другой национальный язык. В процессе разговора код передаётся звуками, а при письменном общении с помощью букв. У водителей или у пилотов обработка информации также осуществляется световыми сигналами, специальнвми символами — знаками.
Количество и графическое отображение символов в алфавитах естественных языков сложилось исторически и характеризуется особенностями языка (произносимыми звуками). Например русский алфавит имеет 33 символа, латинский – 26, китайский несколько тысяч.
К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Двоичная методика
Современный компьютер может обрабатывать числовую, текстовую, графическую, звуковую и видео информацию. В процессе хранения, обработки и передачи информации в компьютере используется особая двоичная система кодирования, алфавит которой состоит всего из двух знаков «0» и «1». Дело в том, что компьютер способен обрабатывать и хранить только лишь один вид представления данных – цифровой. Связано это с тем, что в цифровой электронике удобнее всего представлять информацию в виде последовательности электрических импульсов: техническое устройство, безошибочно различающее 2 разных состояния сигнала, оказалось проще создать, чем то, которое бы безошибочно различало 5 или 10 различных состояний. Поэтому любую входящую в него информацию необходимо переводить в цифровой вид. Такое кодирование информации принято называть двоичным, на его основе работают все окружающие нас компьютеры, смартфоны и т.п.
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Двоичное кодирование информации привлекает тем, что легко реализуется технически. Электронные схемы для обработки двоичных кодов должны находиться только в одном из двух состояний: есть сигнал/нет сигнала или высокое напряжение/низкое напряжение. В результате любая информация кодируется в компьютерах с помощью последовательностей лишь двух цифр — 0 и 1.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
- 1 бит <0,1>;
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позво ляет размещать в нем любой из алфавитно-цифровых символов. Первые 128 сим волов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 0000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
Первоначально в кодах ASCII было 7 бит информации. В последующем ее расширили до 8-битной (1 байт) кодировки. Обьем 7-битного кодирования по сравнению с 8-битным в 2 раза меньше. 2 7 =128 8 =256.
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Растровое изображение
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную. Мы рассмотрим самую распространенный, растровый формат кодирования изображения.
Графические данные на мониторе представляются в качестве растрового изображения. Если более пристально рассмотреть графическое изображение на экране монитора компьютера, то можно увидеть большое количество разноцветных точек (пикселов – от англ. pixel, образованного от picture element – элемент изображения), которые, будучи собраны вместе, и образуют данное графическое изображение. Каждому пикселю присвоен особый код, в котором хранится информация об оттенке пикселя. Из этого можно сделать вывод: графическое изображение в компьютере определенным образом кодируется и должно быть представлено в виде графического файла.
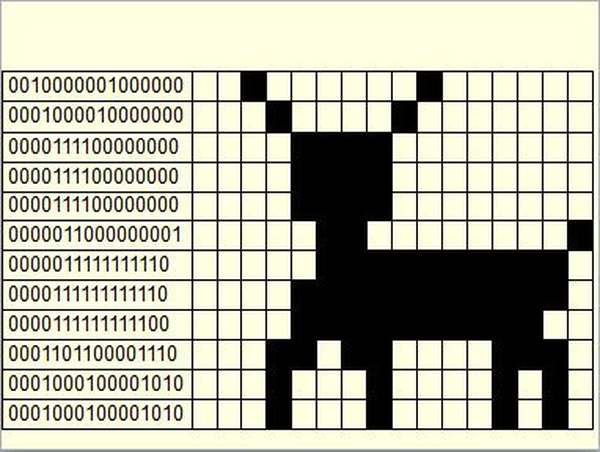
Файлы, созданные на основе растровой графики, предполагают хранение данных о каждой отдельной точке изображения. Для отображения растровой графики не требуется сложных математических расчетов, достаточно лишь получить данные о каждой точке изображения (ее координаты и цвет) и отобразить их на экране монитора компьютера.
Что делать, если рисунок цветной? Формирование цветного изображения на мониторе осуществляется путём смешивания 3-х основных цветов: синего, красного и зелёного. В этом случае для кодирования цвета пикселя уже не обойтись одним битом. В системе кодирования цветных изображений RGB (R — красный, G — зеленый и B — синий) яркость каждой цветовой составляющей (или, как говорят, каждого канала) кодируется целым числом от 0 до 255. При этом код цвета — это тройка чисел (R,G,B), яркости отдельных каналов. Цвет (0,0,0) — это черный цвет, а (255,255,255) — белый. Если все составляющие имеют равную яркость, получаются оттенки серого цвета, от черного до белого. При кодировании цвета на веб-страницах также используется модель RGB, но яркости каналов записываются в шестнадцатеричной системе счисления (от 0016 до FF16), а перед кодом цвета ставится знак #. Например, код красного цвета записывается как #FF0000, а код синего — как #0000FF.
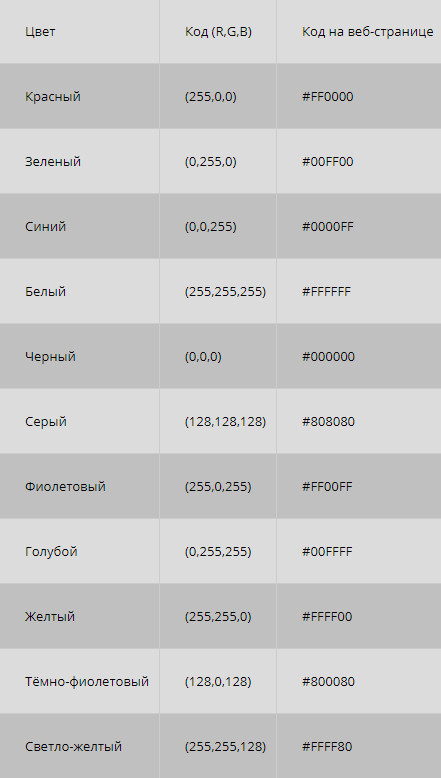
Всего есть по 256 вариантов яркости каждого из трех цветов. Это позволяет закодировать 256 3 = 16 777 216 оттенков, что более чем достаточно для человека. Так как 256 = 2 8 , каждая из трех составляющих занимает в памяти 8 бит или 1 байт, а вся информация о каком-то цвете — 24 бита (или 3 байта). Эта величина называется глубиной цвета.
Звуки и их разрядность
Человек воспринимает звуковые волны (колебания воздуха) с помощью слуха в форме звука различных громкости и тона. Чем больше интенсивность звуковой волны, тем громче звук, чем больше частота волны, тем выше тон звука. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую дискретную форму с помощью временной дискретизации. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, для каждого такого участка устанавливается определенная величина интенсивности звука.
В каждом современном компьютере предусмотрена звуковая плата, колонки, микрофон. С их помощью производится запись, сохраняются и воспроизводятся звуки — волны с определённой частотой и амплитудой. Программное обеспечение для компьютеров преобразовывает звуковые сигналы в последовательность нулей и единиц. Для этого использунтся аудиоадаптер или звуковая плата. Устройство подключается к компьютеру с целью преобразования электроколебаний звуковой частоты в двоичный код. Процесс преобразования выполняется как при вводе звуков в компьютер так и при обратном их преобразовании.
Для человека звук тем громче, чем больше амплитуда сигнала, и тем выше тон, чем больше частота сигнала. Компьютер — устройство цифровое, поэтому непрерывный звуковой сигнал должен быть преобразован в последовательность электрических импульсов (нулей и единиц). Оцифровку звука выполняет специальное устройство на звуковой плате. Называется оно аналого-цифровой преобразователь (АЦП). Обратный процесс — воспроизведение закодированного звука производится с помощью цифро-аналогового преобразователя (ЦАП).
В процессе кодирования непрерывного звукового сигнала производится его дискретизация по времени, или, как говорят, «временная дискретизация».
Для записи аналогового звука и г го преобразования в цифровую форму используется микрофон, подключенный к звуковой плате. Качество полученного цифрового звука зависит от количества измерений уровня громкости звука в единицу времени, т. е. частоты дискретизации. Чем большее количество измерений производится за 1 секунду (чем больше частота дискретизации), тем точнее «лесенка» цифрового звукового сигнала повторяет кривую аналогового звукового сигнала.
Глубина кодирования звука — это количество бит, используемое для кодирования различных уровней сигнала или состояний. Современные звуковые карты обеспечивают 16-битную глубину кодирования звука, и тогда общее количество различных уровней громкомти, который сможет распознать компьютер будет: N = 2 16 = 65536.
Частота дискретизации- это количество измерений уровня звукового сигнала в единицу времени. Эта характеристика показывает качество и точность процедуры двоичного кодирования. Измеряется в герцах (Гц).
Одно измерение за одну секунду соответствует частоте 1 Гц, 1000 измерений за одну секунду — 1 килогерц (кГц). Частота дискретизации звукового сигнала может принимать значения от 8 до 196 кГц. При частоте 8 кГц качество дискретизированного звукового сигнала соответствует качеству радиотрансляции, а при частоте 48 кГц — качеству звучания аудио-CD. Достаточно высокое качество звучания достигается при частоте дискретизации 44 кГц и глубины кодирования звука, равной 16 бит.
Оцифрованный сигнал в виде набора последовательных значений амплитуды уже можно сохранить в памяти компьютера. В случае, когда записываются абсолютные значения амплитуды, такой формат записи называется PCM ( Pulse Code Modulation). Стандартный аудио компакт-диск (CD-DA), применяющийся с начала 80-х годов 20-го столетия, хранит информацию в формате PCM с частотой дискретизации 44.1 кГц и разрядностью квантования 16 бит.
Подробнее о свойствах звука можно прочитать в статье Звук
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК).
Машинная команда представляет собой закодированное по определенным правилам указание микропроцессору на выполнение некоторой операции или действия. Каждая команда содержит элементы, определяющие:
- указание на то, какие действия должен сделать микропроцессор (ответ па этот вопрос дает часть команды, которая называется кодом операции (КОП));
- указание на объекты, над которыми надо провести какие-то действия (эти элементы машинной команды называются операндами);
- указание на способ действия (эти элементы называются типами операндов).
Структура машинной команды состоит из операционной и адресной части. В операционной части содержится код операции. Чем длиннее операционная часть, тем большее количество операций можно в ней закодировать.
В адресной части машинной команды содержится информация об адресах операндов. Это либо значения адресов ячеек памяти, в которых размещаются сами операнды (абсолютная адресация), либо информация, по которой процессор определяет значения их адресов в памяти (относительная адресация). Абсолютная адресация использовалась только в машинах 1 и 2-го поколений. Начиная с машин 3-го поколения, наряду с абсолютной используется относительная адресация.
Подробнее о поколениях компьютеров смотрите в статье История развития компьютеров
Заключение
Итак, кодирование информации — процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки (Цифровое кодирование, аналоговое кодирование, таблично-символьное кодирование, числовое кодирование). Процесс преобразования сообщения в комбинацию символов в соответствии с кодом называется кодированием, процесс восстановления сообщения из комбинации символов называется декодированием.
Кодирование информации — процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Информацию необходимо представлять в какой — либо форме, т.е. кодировать. Для представления дискретной информации используется некоторый алфавит. Однако однозначное соответствие между информацией и алфавитом отсутствует. Другими словами, одна и та же информация может быть представлена посредством различных алфавитов. В связи с такой возможностью возникает проблема перехода от одного алфавита к другому, причём, такое преобразование не должно приводить к потере информации.
Источник



