
Код шеннона фано табличный способ
Коды Фано и Хаффмана являются оптимальными и префиксными. При построении искомых кодов будем применять как традиционный табличный способ кодирования, так и использовать «кодовые деревья».
При кодировании по Фано все сообщения записываются в таблицу по степени убывания вероятности и разбиваются на две группы примерно (насколько это возможно) равной вероятности. Соответственно этой процедуре из корня кодового дерева исходят два ребра, которым в качестве весов присваиваются полученные вероятности. Двум образовавшимся вершинам приписывают кодовые символы 0 и 1. Затем каждая из групп вероятностей вновь делится на две подгруппы примерно равной вероятности. В соответствии с этим из каждой вершины 0 и 1 исходят по два ребра с весами, равными вероятностям подгрупп, а вновь образованным вершинам приписывают символы 00 и 01, 10 и 11. В результате многократного повторения процедуры разделения вероятностей и образования вершин приходим к ситуации, когда в качестве веса, приписанного ребру бинарного дерева, выступает вероятность одного из данных сообщений. В этом случае вновь образованная вершина оказывается листом дерева, т.к. процесс деления вероятностей для нее завершен. Задача кодирования считается решенной, когда на всех ветвях кодового бинарного дерева образуются листья.
Пример 151. Закодировать по Фано сообщения, имеющие следующие вероятности:
| сообщение | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| вероятность | 0,4 | 0,2 | 0,1 | 0,1 | 0,1 | 0,05 | 0,05 |
Решение 1 (с использованием кодового дерева)
Листья кодового дерева представляют собой кодируемые сообщения с присвоенными им кодовыми словами.
Решение 2 (табличный способ)
Цена кодирования (средняя длина кодового слова является критерием степени оптимальности кодирования. Вычислим ее в нашем случае.
Для того, чтобы закодировать сообщения по Хаффману, предварительно преобразуется таблица, задающая вероятности сообщений. Исходные данные записываются в столбец, две последние (наименьшие) вероятности в котором складываются, а полученная сумма становится новым элементом таблицы, занимающим соответствующее место в списке убывающих по величине вероятностей. Эта процедура продолжается до тех пор, пока в столбце не останутся всего два элемента.
Пример 152. Закодировать сообщения из предыдущего примера по методу Хаффмана.
Решение 1. Первый шаг
Вторым шагом производим кодирование, «проходя» по таблице справа налево (обычно это проделывается в одной таблице):
Решение 2. Построение кодового дерева начинается с корня. Двум исходящим из него ребрам приписывается в качестве весов вероятности 0,6 и 0,4, стоящие в последнем столбце. Образовавшимся при этом вершинам дерева приписываются кодовые символы 0 и 1. Далее «идем» по таблице справа налево. Поскольку вероятность 0,6 является результатом сложения двух вероятностей 0,4 и 0,2, из вершины 0 исходят два ребра с весами 0,4 и 0,2 соответственно, что приводит к образованию двух новых вершин с кодовыми символами 00 и 01. Процедура продолжается до тех пор, пока в таблице остаются вероятности, получившиеся в результате суммирования. Построение кодового дерева заканчивается образованием семи листьев, соответствующих данным сообщениям с присвоенными им кодами. Дерево, полученное в результате кодирования по Хаффману, имеет следующий вид:
Листья кодового дерева представляют собой кодируемые сообщения с присвоенными им кодовыми словами. Таблица кодов имеет вид:
| сообщение | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| код | 1 | 01 | 0010 | 0011 | 0000 | 00010 | 00011 |
Цена кодирования здесь будет равна
Для передачи данных сообщений можно перейти от побуквенного (поцифрового) кодирования к кодированию «блоков», состоящих из фиксированного числа последовательных «букв».
Пример 153. Провести кодирование по методу Фано двухбуквенных комбинаций, когда алфавит состоит из двух букв и , имеющих вероятности = 0,8 и = 0,2.
Цена кода , и на одну букву алфавита приходится 0,78 бита информации. При побуквенном кодировании на каждую букву приходится следующее количество информации:
Пример 154. Провести кодирование по Хаффману трехбуквенных комбинаций для алфавита из предыдущего примера.
Построим кодовое дерево.
Найдем цену кодирования
На каждую букву алфавита приходится в среднем 0,728 бита, в то время как при побуквенном кодировании — 0,72 бита.
Большей оптимизации кодирования можно достичь еще и использованием трех символов — 0, 1, 2 — вместо двух. Тринарное дерево Хаффмана получается, если суммируются не две наименьшие вероятности, а три, и приписываются каждому левому ребру 0, правому — 2, а серединному — 1.
Пример 155. Построить тринарное дерево Хаффмана для кодирования трехбуквенных комбинаций из примера 153 .
Решение. Составим таблицу тройного «сжатия» по методу Хаффмана
Тогда тринарное дерево выглядит следующим образом:
Вопросы для самоконтроля
1. Как определяется среднее число элементарных сигналов, приходящихся на одну букву алфавита?
2. Префиксные коды.
3. Сколько требуется двоичных знаков для записи кодированного сообщения?
4. На чем основано построение кода Фано?
5. Что такое сжатие алфавита?
6. Какой код самый выгодный?
7. Основная теорема о кодировании.
8. Энтропия конкретных типов сообщений.
I 301. Проведите кодирование по методу Фано алфавита из четырех букв, вероятности которых равны 0,4; 0,3; 0,2 и 0,1.
302. Алфавит содержит 7 букв, которые встречаются с вероятностями 0,4; 0,2; 0,1; 0,1; 0,1; 0,05; 0,05. Осуществите кодирование по методу Фано.
303. Алфавит состоит из двух букв, и , встречающихся с вероятностями = 0,8 и = 0,2. Примените метод Фано к кодированию всевозмож-ных двухбуквенных и трехбуквенных комбинаций.
304. Проведите кодирование по методу Хаффмана трехбуквенных слов из предыдущей задачи.
305. Проведите кодирование 7 букв из задачи 302 по методу Хаффмана.
306. Проведите кодирование по методам Фано и Хаффмана пяти букв, равновероятно встречающихся.
II 307. Осуществите кодирование двухбуквенных комбинаций четырех букв из задачи 301.
308. Проведите кодирование всевозможных четырехбуквенных слов из задачи 303.
III 309. Сравните эффективность кодов Фано и Хаффмана при кодировании алфавита из десяти букв, которые встречаются с вероятностями 0,3; 0,2; 0,1; 0,1; 0,1; 0,05; 0,05; 0,04; 0,03; 0,03.
310. Сравните эффективность двоичного кода Фано и кода Хаффмана при кодировании алфавита из 16 букв, которые встречаются с вероятностями 0,25; 0,2; 0,1; 0,1; 0,05; 0,04; 0,04; 0,04; 0,03; 0,03; 0,03; 0,03; 0,02; 0,02; 0,01; 0,01.
Источник
Алгоритм вычисления кодов Шеннона-Фано




![]()
![]()
Код Шеннона-Фано строится с помощью дерева. Построение этого дерева начинается от корня. Всё множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем.
Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона-Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n + 1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути ещё не гарантирует оптимальности всей совокупности действий.
Поэтому код Шеннона-Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона-Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона-Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
Пример кодового дерева
Исходные символы:
A (частота встречаемости 50)
B (частота встречаемости 39)
C (частота встречаемости 18)
D (частота встречаемости 49)
E (частота встречаемости 35)
F (частота встречаемости 24)
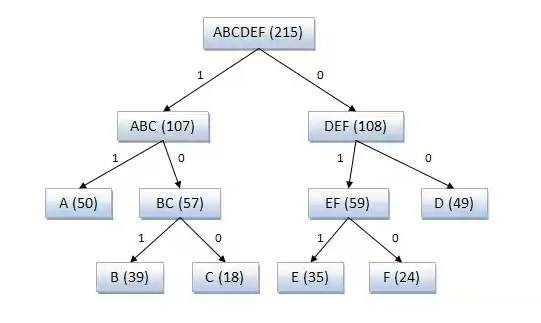
Полученный код: A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Кодирование Шеннона-Фано является достаточно старым методом сжатия, и на сегодняшний день оно не представляет особого практического интереса. В большинстве случаев, длина последовательности, сжатой по данному методу, равна длине сжатой последовательности с использованием кодирования Хаффмана. Но на некоторых последовательностях могут сформироваться неоптимальные коды Шеннона-Фано, поэтому более эффективным считается сжатие методом Хаффмана.
Пример 1. Закодируем буквы алфавита в коде Шеннона-Фано.
Пусть имеется случайная величина X (x1, x2, x3, x4, x5, x6, x7, x8), имеющая восемь состояний с распределением вероятностей 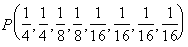
Для кодирования алфавита из восьми букв без учета вероятностей равномерным двоичным кодом нам понадобятся три символа:
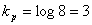 Это 000, 001, 010, 011, 100, 101, 110, 111
Это 000, 001, 010, 011, 100, 101, 110, 111
Чтобы ответить, хорош этот код или нет, необходимо сравнить его с оптимальным значением, то есть определить энтропию
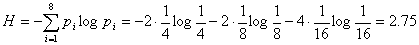
Определив избыточность L по формуле L=1-H/H0=1-2,75/3=0,084, видим, что возможно сокращение длины кода на 8,4%.
Все буквы записываются в порядке убывания их вероятностей, затем делятся на равновероятные группы, которые обозначаются 0 и 1, затем вновь делятся на равновероятные группы и т.д. (см.табл.4.1)
| X | P | Коды | |
| x1 | 1/4 | ——- | ——- |
| x2 | 1/4 | ——- | ——- |
| x3, | 1/8 | ——- | |
| x4 | 1/8 | ——- | |
| x5 | 1/16 | ||
| x6 | 1/16 | ||
| x7 | 1/16 | ||
| x8 | 1/16 |
Средняя длина полученного кода будет равна
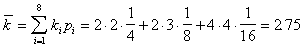
Итак, мы получили оптимальный код. Длина этого кода совпала с энтропией. Данный код оказался удачным, так как величины вероятностей точно делились на равновероятные группы.
Возьмем 32 две буквы русского алфавита. Частоты этих букв известны. В алфавит включен и пробел, частота которого составляет 0,145. Метод кодирования представлен в таблице
| Буква | Рi | Код | ||
| ? | 0.145 | — | ||
| о | 0.095 | — | ||
| е | 0.074 | |||
| а | 0.064 | |||
| и | 0.064 | |||
| н | 0.056 | |||
| т | 0.056 | … | … | — |
| с | 0.047 | … | … | |
| . | … | |||
| ф | 0.03 |
Средняя длина данного кода будет равна, 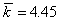 бит/букву;
бит/букву;
Энтропия H=4.42 бит/буква. Эффективность полученного кода можно определить как отношение энтропии к средней длине кода. Она равна 0,994. При значении равном единице код является оптимальным. Если бы мы кодировали кодом равномерной длины 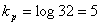 , то эффективность была бы значительно ниже.
, то эффективность была бы значительно ниже. 
Источник
Кодирование Шеннона-Фано
Алгоритм Шеннона-Фано — один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано. Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет позже. Алгоритм использует коды переменной длины: часто встречающийся символ кодируется кодом меньшей длины, редко встречающийся — кодом большей длины. Коды Шеннона-Фано префиксные, то есть, никакое кодовое слово не является префиксом любого другого. Это свойство позволяет однозначно декодировать любую последовательность кодовых слов.
Содержание
Основные сведения
Кодирование Шеннона-Фано (англ. Shannon-Fano coding) — алгоритм префиксного неоднородного кодирования. Относится к вероятностным методам сжатия (точнее, методам контекстного моделирования нулевого порядка). Подобно алгоритму Хаффмана алгоритм Шеннона-Фано использует избыточность сообщения, заключённую в неоднородном распределении частот символов его (первичного) алфавита, то есть заменяет коды более частых символов короткими двоичными последовательностями, а коды более редких символов — более длинными двоичными последовательностями.
Алгоритм был независимо друг от друга разработан Шенноном (публикация «Математическая теория связи», 1948 год) и, позже, Фано (опубликовано как технический отчёт).
Основные этапы
- Символы первичного алфавита m1 выписывают в порядке убывания вероятностей.
- Символы полученного алфавита делят на две части, суммарные вероятности символов которых максимально близки друг другу.
- В префиксном коде для первой части алфавита присваивается двоичная цифра «0», второй части — «1».
- Полученные части рекурсивно делятся и их частям назначаются соответствующие двоичные цифры в префиксном коде.
Когда размер подалфавита становится равен нулю или единице, то дальнейшего удлинения префиксного кода для соответствующих ему символов первичного алфавита не происходит, таким образом, алгоритм присваивает различным символам префиксные коды разной длины. На шаге деления алфавита существует неоднозначность, так как разность суммарных вероятностей p0 − p1 может быть одинакова для двух вариантов разделения (учитывая, что все символы первичного алфавита имеют вероятность, большую нуля).
Алгоритм вычисления кодов Шеннона-Фано
Код Шеннона-Фано строится с помощью дерева. Построение этого дерева начинается от корня. Все множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем. Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона-Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n+1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути еше не гарантирует оптимальности всей совокупности действий. Поэтому код Шеннона-Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона-Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона-Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
Пример кодового дерева
A (частота встречаемости 50), B (частота встречаемости 39), C (частота встречаемости 18), D (частота встречаемости 49), E (частота встречаемости 35), F (частота встречаемости 24).

A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Кодирование Шеннона-Фано является достаточно старым методом сжатия, и на сегодняшний день оно не представляет особого практического интереса. В большинстве случаев, длина сжатой последовательности, по данному методу, равна длине сжатой последовательности с использованием кодирования Хаффмана. Но на некоторых последовательностях всё же формируются неоптимальные коды Шеннона-Фано, поэтому сжатие методом Хаффмана принято считать более эффективным.
Литература
- А. М. Яглом, И. М. Яглом. Вероятность и информация. — М.: «Наука», 1973.
Ссылки
Методы сжатия
| Информация | Собственная · Взаимная · Энтропия · Условная энтропия · Сложность · Избыточность |
|---|---|
| Единицы измерения | Бит · Нат · Ниббл · Хартли · Формула Хартли |
| Энтропийное сжатие | Алгоритм Хаффмана · Адаптивный алгоритм Хаффмана · Арифметическое кодирование ( Алгоритм Шеннона — Фано · Интервальное) · Коды Голомба · Дельта · Универсальный код (Элиаса · Фибоначчи) |
|---|---|
| Словарные методы | RLE · · LZ ( · LZSS · LZW · LZWL · · · LZX · LZRW · LZJB · LZT) |
| Прочее | RLE · CTW · BWT · PPM · DMC |
| Теория | Свёртка · PCM · Алиасинг · Дискретизация · Теорема Котельникова |
|---|---|
| Методы | LPC (LAR · LSP) · WLPC · CELP · ACELP · A-закон · μ-закон · MDCT · Преобразование Фурье · Психоакустическая модель |
| Прочее | Dynamic range compression · Сжатие речи · Полосное кодирование |
| Термины | Цветовое пространство · Пиксел · Chroma subsampling · Артефакты сжатия |
|---|---|
| Методы | RLE · DPCM · Фрактальный · Wavelet · EZW · SPIHT · LP · ДКП · ПКЛ |
| Прочее | Битрейт · Test images · PSNR · Квантование |
| Термины | Характеристики видео · Кадр · Типы кадров · Качество видео |
|---|---|
| Методы | Компенсация движения · ДКП · Квантование |
| Прочее | Видеокодек · Rate distortion theory (CBR · ABR · VBR) |
Wikimedia Foundation . 2010 .
Полезное
Смотреть что такое «Кодирование Шеннона-Фано» в других словарях:
Алгоритм Шеннона — Фано — Алгоритм Шеннона Фано один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано (англ. Fano). Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет … Википедия
Код Шеннона-Фано — Алгоритм Шеннона Фано один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано. Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет позже. Алгоритм… … Википедия
Кодирование энтропии — кодирование словами (кодами) переменной длины, при которой длина кода символа имеет обратную зависимость от вероятности появления символа в передаваемом сообщении. Обычно энтропийные кодировщики используют для сжатия данных коды, длины которых… … Википедия
Кодирование с минимальной избыточностью — Кодирование энтропии кодирование словами (кодами) переменной длины, при которой длина кода символа имеет обратную зависимость от вероятности появления символа в передаваемом сообщении. Обычно энтропийные кодировщики используют для сжатия данных… … Википедия
Кодирование длин серий — (англ. Run length encoding, RLE) или Кодирование повторов простой алгоритм сжатия данных, который оперирует сериями данных, то есть последовательностями, в которых один и тот же символ встречается несколько раз подряд. При кодировании… … Википедия
Кодирование Хаффмана — Алгоритм Хаффмана (англ. Huffman) адаптивный жадный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году доктором Массачусетского технологического института Дэвидом Хаффманом. В настоящее… … Википедия
Шеннона теорема — Теорема Котельникова (в англоязычной литературе теорема Найквиста) гласит, что, если аналоговый сигнал x(t) имеет ограниченный спектр, то он может быть восстановлен однозначно и без потерь по своим дискретным отсчётам, взятым с частотой более… … Википедия
Кодирование Голомба — Коды Голомба это семейство энтропийных кодеров, являющихся общим случаем унарного кода. Также под кодом Голомба может подразумеваться один из представителей этого семейства. Код Голомба позволяет представить последовательность символов в виде… … Википедия
Алгоритм Шеннона — Алгоритм Шеннона Фано один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано (англ. Robert Fano). Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на… … Википедия
Энтропийное кодирование — Для термина «Кодирование» см. другие значения. Энтропийное кодирование кодирование последовательности значений с возможностью однозначного восстановления с целью уменьшения объёма данных (длины последовательности) с помощью усреднения… … Википедия
Источник



