
Логическая организация кэш-памяти процессора
На днях решил систематизировать знания, касающиеся принципов отображения оперативной памяти на кэш память процессора. В результате чего и родилась данная статья.
Кэш память процессора используется для уменьшения времени простоя процессора при обращении к RAM.
Основная идея кэширования опирается на свойство локальности данных и инструкций: если происходит обращение по некоторому адресу, то велика вероятность, что в ближайшее время произойдет обращение к памяти по тому же адресу либо по соседним адресам.
Логически кэш-память представляет собой набор кэш-линий. Каждая кэш-линия хранит блок данных определенного размера и дополнительную информацию. Под размером кэш-линии понимают обычно размер блока данных, который в ней хранится. Для архитектуры x86 размер кэш линии составляет 64 байта.
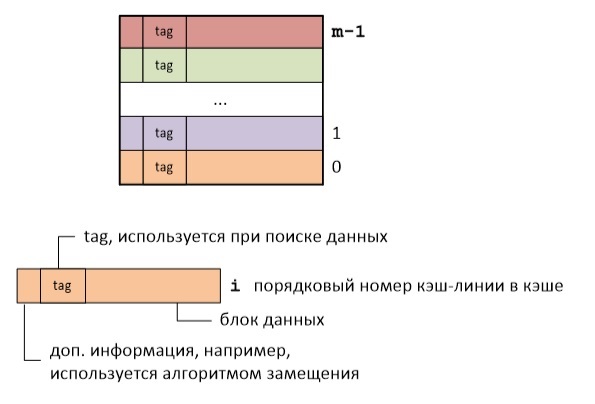
Так вот суть кэширования состоит в разбиении RAM на кэш-линии и отображении их на кэш-линии кэш-памяти. Возможно несколько вариантов такого отображения.
DIRECT MAPPING
Основная идея прямого отображения (direct mapping) RAM на кэш-память состоит в следующем: RAM делится на сегменты, причем размер каждого сегмента равен размеру кэша, а каждый сегмент в свою очередь делится на блоки, размер каждого блока равен размеру кэш-линии.

Блоки RAM из разных сегментов, но с одинаковыми номерами в этих сегментах, всегда будут отображаться на одну и ту же кэш-линию кэша:
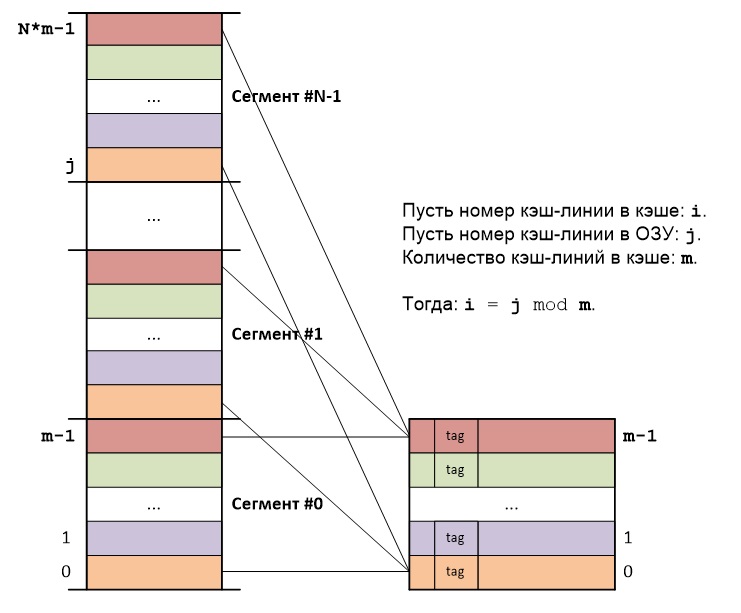
Адрес каждого байта представляет собой сумму порядкового номера сегмента, порядкового номера кэш-линии внутри сегмента и порядкового номера байта внутри кэш-линии. Отсюда следует, что адреса байт различаются только старшими частями, представляющими собой порядковые номера сегментов, а порядковые номера кэш-линий внутри сегментов и порядковые номера байт внутри кэш-линий — повторяются.
Таким образом нет необходимости хранить полный адрес кэш-линии, достаточно сохранить только старшую часть адреса. Тэг (tag) каждой кэш-линии как раз и хранит старшую часть адреса первого байта в данной кэш-линии.
b — размер кэш-линии.
m — количество кэш-линий в кэше.
Для адресации b байт внутри каждой кэш-линии потребуется: log2b бит.
Для адресации m кэш-линий внутри каждого сегмента потребуется: log2m бит.
m = Объем кэш-памяти/Размер кэш линии.
Для адресации N сегментов RAM: log2N бит.
N = Объем RAM/Размер сегмента.
Для адресации байта потребуется: log2N + log2m + log2b бит.
Этапы поиска в кэше:
1. Извлекается средняя часть адреса (log2m), определяющая номер кэш-линии в кэше.
2. Тэг кэш-линии с данным номером сравнивается со старшей частью адреса (log2N).
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
FULLY ASSOCIATIVE MAPPING
Основная идея полностью ассоциативного отображения (fully associative mapping) RAM на кэш-память состоит в следующем: RAM делится на блоки, размер которых равен размеру кэш-линий, а каждый блок RAM может сохраняться в любой кэш-линии кэша:
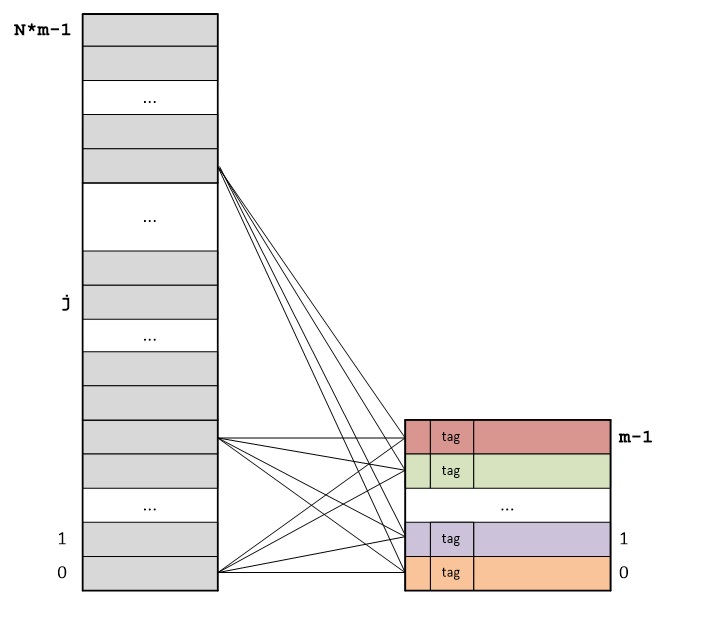
Адрес каждого байта представляет собой сумму порядкового номера кэш-линии и порядкового номера байта внутри кэш-линии. Отсюда следует, что адреса байт различаются только старшими частями, представляющими собой порядковые номера кэш-линий. Порядковые номера байт внутри кэш-линий повторяются.
Тэг (tag) каждой кэш-линии хранит старшую часть адреса первого байта в данной кэш-линии.
b — размер кэш-линии.
m — количество кэш-линий, умещающихся в RAM.
Для адресации b байт внутри каждой кэш-линии потребуется: log2b бит.
Для адресации m кэш-линий: log2m бит.
m = Размер RAM/Размер кэш-линии.
Для адресации байта потребуется: log2m + log2b бит.
Этапы поиска в кэше:
1. Тэги всех кэш-линий сравниваются со старшей частью адреса одновременно.
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
SET ASSOCIATIVE MAPPING
Основная идея наборно ассоциативного отображения (set associative mapping) RAM на кэш-память состоит в следующем: RAM делится также как и в прямом отображении, а сам кэш состоит из k кэшей (k каналов), использующих прямое отображение.

Кэш-линии, имеющие одинаковые номера во всех каналах, образуют set (набор, сэт). Каждый set представляет собой кэш, в котором используется полностью ассоциативное отображение.
Блоки RAM из разных сегментов, но с одинаковыми номерами в этих сегментах, всегда будут отображаться на один и тот же set кэша. Если в данном сете есть свободные кэш-линии, то считываемый из RAM блок будет сохраняться в свободную кэш-линию, если же все кэш-линии сета заняты, то кэш-линия выбирается согласно используемому алгоритму замещения.
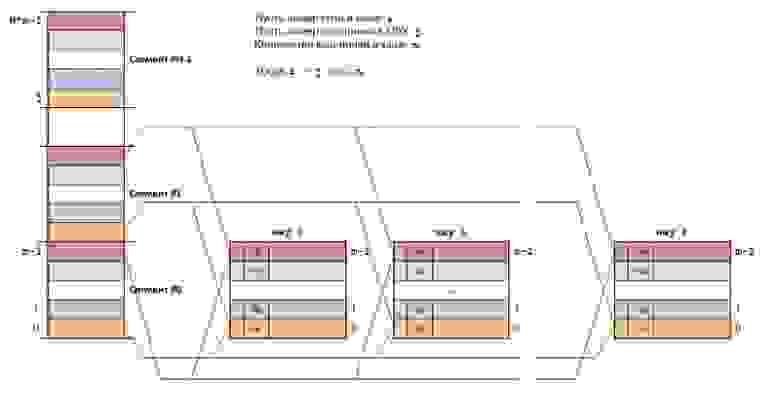
Структура адреса байта в точности такая же, как и в прямом отображении: log2N + log2m + log2b бит, но т.к. set представляет собой k различных кэш-линий, то поиск в кэше немного отличается.
Этапы поиска в кэше:
1. Извлекается средняя часть адреса (log2m), определяющая номер сэта в кэше.
2. Тэги всех кэш-линий данного сета сравниваются со старшей частью адреса (log2N) одновременно.
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
Т.о количество каналов кэша определяет количество одновременно сравниваемых тэгов.
Источник
Организация и принципы работы кэш-памяти
Общие принципы функционирования кэш-памяти
Кэш-память (КП), или кэш, представляет собой организованную в виде ассоциативного запоминающего устройства (АЗУ) быстродействующую буферную память ограниченного объема, которая располагается между регистрами процессора и относительно медленной основной памятью и хранит наиболее часто используемую информацию совместно с ее признаками (тегами), в качестве которых выступает часть адресного кода.
В процессе работы отдельные блоки информации копируются из основной памяти в кэш — память . При обращении процессора за командой или данными сначала проверяется их наличие в КП. Если необходимая информация находится в кэше, она быстро извлекается. Это кэш-попадание. Если необходимая информация в КП отсутствует ( кэш-промах ), то она выбирается из основной памяти, передается в микропроцессор и одновременно заносится в кэш — память . Повышение быстродействия вычислительной системы достигается в том случае, когда кэш-попадания реализуются намного чаще, чем кэш-промахи.
Зададимся вопросом: «А как определить наиболее часто используемую информацию? Неужели сначала кто-то анализирует ход выполнения программы, определяет, какие команды и данные чаще используются, а потом, при следующем запуске программы, эти данные переписываются в кэш — память и уже тогда программа выполняется эффективно?» Конечно нет. Хотя в современных микропроцессорах имеется определенный механизм, который позволяет в некоторой степени реализовать этот принцип. Но в основном, конечно, кэш — память сама отбирает информацию, которая чаще всего используется. Рассмотрим, как это происходит.
Механизм сохранения информации в кэш-памяти
При включении микропроцессора в работу вся информация в его кэш-памяти недостоверна.
При обращении к памяти микропроцессор, как уже отмечалось, сначала проверяет, не содержится ли искомая информация в кэш-памяти.
Для этого сформированный им физический адрес сравнивается с адресами ячеек памяти, которые были ранее кэшированы из ОЗУ в КП.
При первом обращении такой информации в кэш -памяти, естественно, нет, и это соответствует кэш-промаху. Тогда микропроцессор проводит обращение к оперативной памяти, извлекает нужную информацию, использует ее в своей работе, но одновременно записывает эту информацию в кэш .
Если бы в кэш — память заносилась только востребованная микропроцессором в данный момент информация , то, скорее всего, при следующем обращении вновь произошел бы кэш-промах: вряд ли следующее обращение произойдет к той же самой команде или к тому же самому операнду. Кэш-попадания происходили бы лишь после того, как в КП накопится достаточно большой фрагмент программы, содержащий некоторые циклические участки кода, или фрагмент данных, подлежащих повторной обработке. Для того чтобы уже следующее обращение к КП приводило как можно чаще к кэш-попаданиям, передача из оперативной памяти в кэш — память происходит не теми порциями (байтами или словами), которые востребованы микропроцессором в данном обращении, а так называемыми строками. То есть кэш — память и оперативная память с точки зрения кэширования организуются в виде строк. Длина строки превышает максимально возможную длину востребованных микропроцессором данных. Обычно она составляет от 16 до 64 байт и выровнена в памяти по границе соответствующего раздела (рис. 4.1).
Высокий процент кэш-попаданий в этом случае обеспечивается благодаря тому, что в большинстве случаев программы обращаются к ячейкам памяти, расположенным вблизи от ранее использованных. Это свойство, называемое принципом локальности ссылок, обеспечивает эффективность использования КП. Оно подразумевает, что при исполнении программы в течение некоторого относительно малого интервала времени происходит обращение к памяти в пределах ограниченного диапазона адресов (как по коду программы, так и по данным).
Например, микропроцессору для своей работы потребовалось 2 байта информации. Если строка имеет длину 16 байт , то в кэш переписываются не только нужные 2 байта, но и некоторое их окружение. Когда микропроцессор обращается за новой информацией, в силу локальности ссылок, скорее всего, обращение произойдет по соседнему адресу. Затем опять по соседнему, опять по соседнему и т. д. Таким образом, ряд следующих обращений будет происходить непосредственно к кэш -памяти, минуя оперативную память (кэш-попадания). Когда очередной сформированный микропроцессором физический адрес выйдет за пределы строки кэш -памяти (произойдет кэш-промах ), будет выполнена подкачка в кэш новой строки, и вновь ряд последующих обращений вызовет кэш-попадания.
Чем длиннее используемая при обмене между оперативной и кэшпамятью строка, тем больше вероятность того, что следующее обращение произойдет в пределах этой строки. Но в то же время чем длиннее строка, тем дольше она будет перекачиваться из оперативной памяти в кэш . И если очередная команда окажется командой перехода или выборка данных начнется из нового массива, то есть следующее обращение произойдет не по соседнему адресу, то время, затраченное на передачу длинной строки, будет использовано напрасно. Поэтому при выборе длины строки должен быть разумный компромисс между соотношением времени обращения к оперативной и кэш -памяти и вероятностью достаточно удаленного перехода от текущего адреса при выполнении программы. Обычно длина строки определяется в результате моделирования аппаратно-программной структуры системы .
После того как в КП накопится достаточно большой объем информации, увеличивается вероятность того, что формирование очередного адреса приведет к кэш-попаданию. Особенно велика вероятность этого при выполнении циклических участков программы.
Старая информация по возможности сохраняется в кэш -памяти. Ее замена на новую определяется емкостью, организацией и стратегией обновления кэша.
Типы кэш-памяти
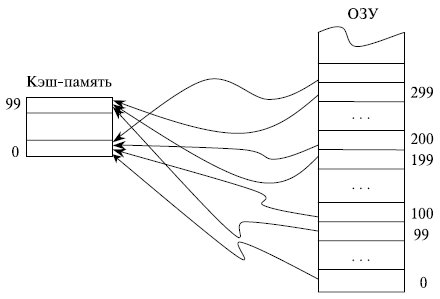
Если каждая строка ОЗУ имеет только одно фиксированное место , на котором она может находиться в кэш -памяти, то такая кэш — память называется памятью с прямым отображением.
Предположим, что ОЗУ состоит из 1000 строк с номерами от 0 до 999, а кэш — память имеет емкость только 100 строк. В кэш -памяти с прямым отображением строки ОЗУ с номерами 0, 100, 200, . 900 могут сохраняться только в строке 0 КП и нигде иначе, строки 1, 101, 201, …, 901
ОЗУ — в строке 1 КП, строки ОЗУ с номерами 99, 199, …, 999 сохраняются в строке 99 кэш -памяти (рис. 4.2). Такая организация кэш -памяти обеспечивает быстрый поиск в ней нужной информации: необходимо проверить ее наличие только в одном месте. Однако емкость КП при этом используется не в полной мере: несмотря на то, что часть кэш -памяти может быть не заполнена, будет происходить вытеснение из нее полезной информации при последовательных обращениях, например, к строкам 101, 301, 101 ОЗУ .
Кэш — память называется полностью ассоциативной, если каждая строка ОЗУ может располагаться в любом месте кэш -памяти.
В полностью ассоциативной кэш -памяти максимально используется весь ее объем: вытеснение сохраненной в КП информации проводится лишь после ее полного заполнения. Однако поиск в кэш -памяти, организованной подобным образом, представляет собой трудную задачу.
Компромиссом между этими двумя способами организации кэш -памяти служит множественно-ассоциативная КП, в которой каждая строка ОЗУ может находиться по ограниченному множеству мест в кэш -памяти.
При необходимости замещения информации в кэш -памяти на новую используется несколько стратегий замещения. Наиболее известными среди них являются:
- LRU — замещается строка, к которой дольше всего не было обращений;
- FIFO — замещается самая давняя по пребыванию в кэш-памяти строка;
- Random — замещение проходит случайным образом.
Последний вариант, существенно экономя аппаратные средства по сравнению с другими подходами, в ряде случаев обеспечивает и более эффективное использование кэш -памяти. Предположим, например, что КП имеет объем 4 строки, а некоторый циклический участок программы имеет длину 5 строк. В этом случае при стратегиях LRU и FIFO кэш — память окажется фактически бесполезной ввиду отсутствия кэш -попаданий. В то же время при использовании стратегии случайного замещения информации часть обращений к КП приведет к кэш -попаданиям.
Некоторые эвристические оценки вероятности кэш -промаха при разных стратегиях замещения (в процентах) представлены в табл. 4.1.
| Размер кэша,Кбайт | Организация кэш-памяти | |||||
|---|---|---|---|---|---|---|
| 2-канальная ассоциативная | 4-канальная ассоциативная | 8-канальная ассоциативная | ||||
| LRU | Random | LRU | Random | LRU | Random | |
| 16 | 5.2 | 5.7 | 4.7 | 5.3 | 4.4 | 5.0 |
| 64 | 1.9 | 2.0 | 1.5 | 1.7 | 1.4 | 1.5 |
| 256 | 1.15 | 1.17 | 1.13 | 1.13 | 1.12 | 1.12 |
Анализ таблицы показывает, что:
- увеличением емкости кэша, естественно, уменьшается вероятность кэш-промаха, но даже при незначительной на сегодняшний день емкости кэш-памяти в 16 Кбайт около 95 % обращений происходят к КП, минуя оперативную память;
- чем больше степень ассоциативности кэш-памяти, тем больше вероятность кэш-попадания за счет более полного заполнения КП (время поиска информации в КП в данном анализе не учитывается);
- механизм LRU обеспечивает более высокую вероятность кэш-попадания по сравнению с механизмом случайного замещения Random , однако этот выигрыш не очень значителен.
Соответствие между данными в оперативной памяти и в кэш -памяти обеспечивается внесением изменений в те области ОЗУ , для которых данные в кэш -памяти подверглись изменениям. Существует два основных способа реализации этих действий: со сквозной записью ( writethrough ) и с обратной записью ( write-back ).
При считывании оба способа работают идентично. При записи кэширование со сквозной записью обновляет основную память параллельно с обновлением информации в КП. Это несколько снижает быстродействие системы, так как микропроцессор впоследствии может вновь обратиться по этому же адресу для записи информации, и предыдущая пересылка строки кэш -памяти в ОЗУ окажется бесполезной. Однако при таком подходе содержимое соответствующих друг другу строк ОЗУ и КП всегда идентично. Это играет большую роль в мультипроцессорных системах с общей оперативной памятью.
Кэширование с обратной записью модифицирует строку ОЗУ лишь при вытеснении строки кэш -памяти, например, в случае необходимости освобождения места для записи новой строки из ОЗУ в уже заполненную КП. Операции обратной записи также инициируются механизмом поддержания согласованности кэш -памяти при работе мультипроцессорной системы с общей оперативной памятью.
Промежуточное положение между этими подходами занимает способ, при котором все строки, предназначенные для передачи из КП в ОЗУ , предварительно накапливаются в некотором буфере. Передача осуществляется либо при вытеснении строки, как в случае кэширования с обратной записью, либо при необходимости согласования кэш -памяти нескольких микропроцессоров в мультипроцессорной системе, либо при заполнении буфера. Такая передача проводится в пакетном режиме, что более эффективно, чем передача отдельной строки.
Источник



