
- Алгоритмы и структуры данных для начинающих: сортировка
- Авторизуйтесь
- Алгоритмы и структуры данных для начинающих: сортировка
- Метод Swap
- Пузырьковая сортировка
- Сортировка вставками
- Сортировка выбором
- Сортировка слиянием
- Разделяй и властвуй
- Сортировка слиянием
- Быстрая сортировка
- Заключение
- Алгоритмы сортировки
- Определение
- Визуализация алгоритмов сортировки
- Классификация алгоритмов
- Простые сортировки
- Сортировка выборкой
- Пузырьковая сортировка
- Сортировка вставками
- Эффективные сортировки
- Сортировка методом слияния
- Быстрая сортировка
- Основной алгоритм работы
- Недостатки алгоритма
- Пирамидальная сортировка
Алгоритмы и структуры данных для начинающих: сортировка
Авторизуйтесь
Алгоритмы и структуры данных для начинающих: сортировка
В этой части мы посмотрим на пять основных алгоритмов сортировки данных в массиве. Начнем с самого простого — сортировки пузырьком — и закончим «быстрой сортировкой» (quicksort).
Для каждого алгоритма, кроме объяснения его работы, мы также укажем его сложность по памяти и времени в наихудшем, наилучшем и среднем случае.
Метод Swap
Для упрощения кода и улучшения читаемости мы введем метод Swap , который будет менять местами значения в массиве по индексу.
Пузырьковая сортировка
| Сложность | Наилучший случай | В среднем | Наихудший случай |
| Время | O(n) | O(n 2 ) | O(n 2 ) |
| Память | O(1) | O(1) | O(1) |
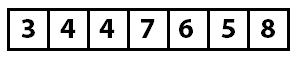
Сортировка пузырьком — это самый простой алгоритм сортировки. Он проходит по массиву несколько раз, на каждом этапе перемещая самое большое значение из неотсортированных в конец массива.
27–28 ноября, Москва, Беcплатно
Например, у нас есть массив целых чисел:

При первом проходе по массиву мы сравниваем значения 3 и 7. Поскольку 7 больше 3, мы оставляем их как есть. После чего сравниваем 7 и 4. 4 меньше 7, поэтому мы меняем их местами, перемещая семерку на одну позицию ближе к концу массива. Теперь он выглядит так:

Этот процесс повторяется до тех пор, пока семерка не дойдет почти до конца массива. В конце она сравнивается с элементом 8, которое больше, а значит, обмена не происходит. После того, как мы обошли массив один раз, он выглядит так:

Поскольку был совершен по крайней мере один обмен значений, нам нужно пройти по массиву еще раз. В результате этого прохода мы перемещаем на место число 6.

И снова был произведен как минимум один обмен, а значит, проходим по массиву еще раз.
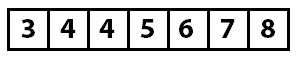
При следующем проходе обмена не производится, что означает, что наш массив отсортирован, и алгоритм закончил свою работу.
Сортировка вставками
| Сложность | Наилучший случай | В среднем | Наихудший случай |
| Время | O(n) | O(n 2 ) | O(n 2 ) |
| Память | O(1) | O(1) | O(1) |
Сортировка вставками работает, проходя по массиву и перемещая нужное значение в начало массива. После того, как обработана очередная позиция, мы знаем, что все позиции до нее отсортированы, а после нее — нет.
Важный момент: сортировка вставками обрабатывает элементы массива по порядку. Поскольку алгоритм проходит по элементам слева направо, мы знаем, что все, что слева от текущего индекса — уже отсортировано. На этом рисунке показано, как увеличивается отсортированная часть массива с каждым проходом:
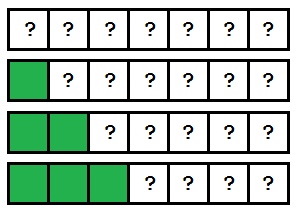
Постепенно отсортированная часть массива растет, и, в конце концов, массив окажется упорядоченным.
Давайте взглянем на конкретный пример. Вот наш неотсортированный массив, который мы будем использовать:

Алгоритм начинает работу с индекса 0 и значения 3. Поскольку это первый индекс, массив до него включительно считается отсортированным.
Далее мы переходим к числу 7. Поскольку 7 больше, чем любое значение в отсортированной части, мы переходим к следующему элементу.
На этом этапе элементы с индексами 0..1 отсортированы, а про элементы с индексами 2..n ничего не известно.
Следующим проверяется значение 4. Так как оно меньше семи, мы должны перенести его на правильную позицию в отсортированную часть массива. Остается вопрос: как ее определить? Это осуществляется методом FindInsertionIndex . Он сравнивает переданное ему значение (4) с каждым значением в отсортированной части, пока не найдет место для вставки.
Итак, мы нашли индекс 1 (между значениями 3 и 7). Метод Insert осуществляет вставку, удаляя вставляемое значение из массива и сдвигая все значения, начиная с индекса для вставки, вправо. Теперь массив выглядит так:
Теперь часть массива, начиная от нулевого элемента и заканчивая элементом с индексом 2, отсортирована. Следующий проход начинается с индекса 3 и значения 4. По мере работы алгоритма мы продолжаем делать такие вставки.
Когда больше нет возможностей для вставок, массив считается полностью отсортированным, и работа алгоритма закончена.
Сортировка выбором
| Сложность | Наилучший случай | В среднем | Наихудший случай |
| Время | O(n) | O(n 2 ) | O(n 2 ) |
| Память | O(1) | O(1) | O(1) |
Сортировка выбором — это некий гибрид между пузырьковой и сортировкой вставками. Как и сортировка пузырьком, этот алгоритм проходит по массиву раз за разом, перемещая одно значение на правильную позицию. Однако, в отличие от пузырьковой сортировки, он выбирает наименьшее неотсортированное значение вместо наибольшего. Как и при сортировке вставками, упорядоченная часть массива расположена в начале, в то время как в пузырьковой сортировке она находится в конце.
Давайте посмотрим на работу сортировки выбором на нашем неотсортированном массиве.

При первом проходе алгоритм с помощью метода FindIndexOfSmallestFromIndex пытается найти наименьшее значение в массиве и переместить его в начало.
Имея такой маленький массив, мы сразу можем сказать, что наименьшее значение — 3, и оно уже находится на правильной позиции. На этом этапе мы знаем, что на первой позиции в массиве (индекс 0) находится самое маленькое значение, следовательно, начало массива уже отсортировано. Поэтому мы начинаем второй проход — на этот раз по индексам от 1 до n — 1.
На втором проходе мы определяем, что наименьшее значение — 4. Мы меняем его местами со вторым элементом, семеркой, после чего 4 встает на свою правильную позицию.

Теперь неотсортированная часть массива начинается с индекса 2. Она растет на один элемент при каждом проходе алгоритма. Если на каком-либо проходе мы не сделали ни одного обмена, это означает, что массив отсортирован.
После еще двух проходов алгоритм завершает свою работу:

Сортировка слиянием
| Сложность | Наилучший случай | В среднем | Наихудший случай |
| Время | O(n·log n) | O(n·log n) | O(n·log n) |
| Память | O(n) | O(n) | O(n) |
Разделяй и властвуй
До сих пор мы рассматривали линейные алгоритмы. Они используют мало дополнительной памяти, но имеют квадратичную сложность. На примере сортировки слиянием мы посмотрим на алгоритм типа «разделяй и властвуй» (divide and conquer).
Алгоритмы этого типа работают, разделяя крупную задачу на более мелкие, решаемые проще. Мы пользуемся ими каждый день. К примеру, поиск в телефонной книге — один из примеров такого алгоритма.
Если вы хотите найти человека по фамилии Петров, вы не станете искать, начиная с буквы А и переворачивая по одной странице. Вы, скорее всего, откроете книгу где-то посередине. Если попадете на букву Т, перелистнете несколько страниц назад, возможно, слишком много — до буквы О. Тогда вы пойдете вперед. Таким образом, перелистывая туда и обратно все меньшее количество страниц, вы, в конце концов, найдете нужную.
Насколько эффективны эти алгоритмы?
Предположим, что в телефонной книге 1000 страниц. Если вы открываете ее на середине, вы отбрасываете 500 страниц, в которых нет искомого человека. Если вы не попали на нужную страницу, вы выбираете правую или левую сторону и снова оставляете половину доступных вариантов. Теперь вам надо просмотреть 250 страниц. Таким образом мы делим нашу задачу пополам снова и снова и можем найти человека в телефонной книге всего за 10 просмотров. Это составляет 1% от всего количества страниц, которые нам пришлось бы просмотреть при линейном поиске.
Сортировка слиянием
При сортировке слиянием мы разделяем массив пополам до тех пор, пока каждый участок не станет длиной в один элемент. Затем эти участки возвращаются на место (сливаются) в правильном порядке.
Давайте посмотрим на такой массив:

Разделим его пополам:

И будем делить каждую часть пополам, пока не останутся части с одним элементом:

Теперь, когда мы разделили массив на максимально короткие участки, мы сливаем их в правильном порядке.

Сначала мы получаем группы по два отсортированных элемента, потом «собираем» их в группы по четыре элемента и в конце собираем все вместе в отсортированный массив.
Для работы алгоритма мы должны реализовать следующие операции:
- Операцию для рекурсивного разделения массива на группы (метод Sort ).
- Слияние в правильном порядке (метод Merge ).
Стоит отметить, что в отличие от линейных алгоритмов сортировки, сортировка слиянием будет делить и склеивать массив вне зависимости от того, был он отсортирован изначально или нет. Поэтому, несмотря на то, что в худшем случае он отработает быстрее, чем линейный, в лучшем случае его производительность будет ниже, чем у линейного. Поэтому сортировка слиянием — не самое лучшее решение, когда надо отсортировать частично упорядоченный массив.
Быстрая сортировка
| Сложность | Наилучший случай | В среднем | Наихудший случай |
| Время | O(n·log n) | O(n·log n) | O(n 2 ) |
| Память | O(1) | O(1) | O(1) |
Быстрая сортировка — это еще один алгоритм типа «разделяй и властвуй». Он работает, рекурсивно повторяя следующие шаги:
- Выбрать ключевой индекс и разделить по нему массив на две части. Это можно делать разными способами, но в данной статье мы используем случайное число.
- Переместить все элементы больше ключевого в правую часть массива, а все элементы меньше ключевого — в левую. Теперь ключевой элемент находится в правильной позиции — он больше любого элемента слева и меньше любого элемента справа.
- Повторяем первые два шага, пока массив не будет полностью отсортирован.
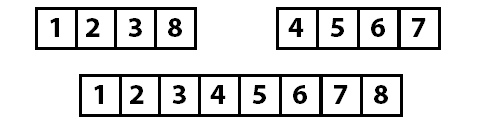
Давайте посмотрим на работу алгоритма на следующем массиве:

Сначала мы случайным образом выбираем ключевой элемент:

Теперь, когда мы знаем ключевой индекс (4), мы берем значение, находящееся по этому индексу (6), и переносим значения в массиве так, чтобы все числа больше или равные ключевому были в правой части, а все числа меньше ключевого — в левой. Обратите внимание, что в процессе переноса значений индекс ключевого элемента может измениться (мы увидим это вскоре).
Перемещение значений осуществляется методом partition .

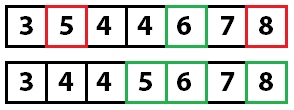
На этом этапе мы знаем, что значение 6 находится на правильной позиции. Теперь мы повторяем этот процесс для правой и левой частей массива.
Мы рекурсивно вызываем метод quicksort на каждой из частей. Ключевым элементом в левой части становится пятерка. При перемещении значений она изменит свой индекс. Главное — помнить, что нам важно именно ключевое значение, а не его индекс.
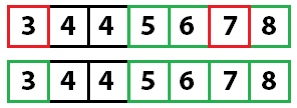
Снова применяем быструю сортировку:
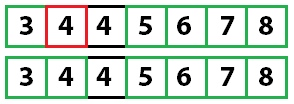
У нас осталось одно неотсортированное значение, а, поскольку мы знаем, что все остальное уже отсортировано, алгоритм завершает работу.
Заключение
На этом мы заканчиваем наш цикл статей по алгоритмам и структурам данных для начинающих. За это время мы рассмотрели связные списки, динамические массивы, двоичное дерево поиска и множества с примерами кода на C#.
Источник
Алгоритмы сортировки
Статья в процессе обновления
Необходимость изучения существующих компьютерных алгоритмов связана с использованием ограниченных вычислительных ресурсов компьютера: память, процессов, скорость чтения данных с диска и запись на диск и др. Эффективность алгоритма напрямую связана с тем, сколько ресурсов компьютеру придётся затратить для решения поставленной задачи. Например, для решения задачи сортировки вставками требуется примерно  операций (здесь
операций (здесь  — количество элементов данных, а
— количество элементов данных, а  — независящая от этих данных константа). Для сортировки слиянием требуется уже порядком
— независящая от этих данных константа). Для сортировки слиянием требуется уже порядком  операций (здесь
операций (здесь  — краткая запись
— краткая запись  , а
, а  — некоторая другая константа). Скорость работы второго алгоритма выше, а наглядный пример приводит Кормэн в книге «Алгоритмы. Построение и анализ» (стр.: 34):
— некоторая другая константа). Скорость работы второго алгоритма выше, а наглядный пример приводит Кормэн в книге «Алгоритмы. Построение и анализ» (стр.: 34):
…рассмотрим два компьютера — А и Б. Компьютер А более быстрый, и на нём работает алгоритм сортировкой вставкой, а компьютер Б более медленный, и на нём работает алгоритм методом слияния. Оба компьютеры должны выполнить сортировку множества, состоящего из десяти миллионов чисел. (…) Предположим, что компьютер А выполняет десять миллиардов команд в секунду, а компьютер Б — только 9 миллионов команд в секунду, так что компьютер А в тысячу раз быстрее компьютера Б. Чтобы различие стало ещё большим, предположим, что код для метода вставок (т.е. для компьютера А) написан лучшим в мире программистом на машинном языке и для сортировке чисел надо выполнить  команд. Сортировка же методом слияния (на компьютере Б) выполнена программистом-середнячком с помощью языка высокого уровня. При этом компилятор оказался не слишком эффективным, и в результате получился код, требующий выполнения
команд. Сортировка же методом слияния (на компьютере Б) выполнена программистом-середнячком с помощью языка высокого уровня. При этом компилятор оказался не слишком эффективным, и в результате получился код, требующий выполнения  команд. Для сортировки десяти миллионов чисел компьютера А понадобиться:
команд. Для сортировки десяти миллионов чисел компьютера А понадобиться:  секунд (более 5,5 часов), в то время как компьютеру Б потребуется
секунд (более 5,5 часов), в то время как компьютеру Б потребуется  секунд (менее 20 минут).
секунд (менее 20 минут).
Как видите, использование кода, время работы которого возрастает медленнее, даже при плохом компиляторе на более медленном компьютере требует более чем 17 раз меньше процессорного времени!
Определение
Алгоритмы сортировки — это алгоритмы, которые берут некоторую последовательность из элементов  и переставляют элементы таким образом, чтобы получившаяся последовательность
и переставляют элементы таким образом, чтобы получившаяся последовательность  удовлетворяла условию:
удовлетворяла условию:  .
.
Визуализация алгоритмов сортировки
Классификация алгоритмов
Алгоритмы сортировки можно классифицировать по:
- принципу сортировки
- сортировки, использующие сравнения: быстрая сортировка, пирамидальная сортировка, сортировка вставками и др.
- сортировки, не использующие сравнения: блочная сортировка, поразрядная сортировка, сортировка подсчётом и др.
- прочие, например, обезьянья сортировка
- устойчивости; сортировка является устойчивой в том случае, если для любой пары элементов с одинаковым ключами, она не меняет их порядок в отсортированном списке
- вычислительной сложности
- использованию дополнительной памяти; сортировки, которые не используют дополнительную память в ходе работы, называют in-place
- рекурсивности
- параллельности
- адаптивности; сортировка является адаптивной в том случае, когда она выигрывает от того, что входные данные могут быть частично или полностью отсортированы (напр., сортировка вставками)
- использованию внутренней или внешней памяти компьютера
Простые сортировки
Сортировка выборкой
Самая простая сортировка, которая для каждой позиции в последовательности ищет минимальный элемент, после чего меняет элементы с индексами текущей позиции и найденного элемента:
Пузырьковая сортировка
Наверное, одна из самых известных сортировок, суть которой сводится к постепенному перемещению минимального элемента от конца последовательности в начало. При этом, сам минимальный элемент может меняться в ходе работы.
Сортировка вставками
Алгоритм такой: изначально отсортированная последовательность пуста; на каждом шаге из набора входных данных выбирается элемент и помещается на нужное место в уже отсортированной последовательности; шаги продолжаются до тех пор, пока набор входных данных не закончится.
Вот алгоритм на псевдокоде:
Утверждение, что в начале каждой итерации цикла оператора for, подмассив A[0..j − 1] , которые раньше находились в этом подмассиве, состоит из тех же элементов, но теперь в отсортированном порядке, называется инвариантом цикла. Инварианты позволяют понять, корректно ли работает алгоритм, и обладают 3-мя свойствами:
- Инициализация. Справедливы перед первой итерации цикла.
- Сохранение. Если они истины перед очередной итерации цикла, то остаются истинными и после неё.
- Завершение. Позволяют убедится в правильности алгоритма по завершению цикла.
Разберём это определение инвариантов на примере приведённого выше алгоритма:
- Инициализация. Перед первой итерации, когда
 , подмассив A[0..j − 1] состоит из единственного элемента A[0], что является тривиальным случаем, и, очевидно, такой подмассив отсортирован.
, подмассив A[0..j − 1] состоит из единственного элемента A[0], что является тривиальным случаем, и, очевидно, такой подмассив отсортирован. - Сохранение. На каждом последующем этапе осуществляется сдвиг элементов A[j], A[j − 1] и т.д. на одну позицию вправо, освобождая место для A[j] элемента до тех пор, пока не найдётся подходящее место для него. После завершения итерации подмассив A[0..j] состоит из тех же элементов в отсортированном порядке.
- Завершение. Цикл завершается в том случае, когда j ≥ n, где n — количество элементов в исходном массиве. Поскольку подмассив A[0..j], который по существу является теперь подмассивом A[0..n] отсортирован, а подмассив A[0..n] и есть исходный массив A, то приведённый алгоритм работает правильно.
 , подмассив A[0..j − 1] состоит из единственного элемента A[0], что является тривиальным случаем, и, очевидно, такой подмассив отсортирован.
, подмассив A[0..j − 1] состоит из единственного элемента A[0], что является тривиальным случаем, и, очевидно, такой подмассив отсортирован.Важная особенность работы этого алгоритма заключается в том, что при уже отсортированных исходных данных цикл while не будет выполняться вовсе, т.к. проверка условия A[i] > value будет срабатывать сразу. Это позволяет алгоритму выполнить не команд, а только  , чем пользуются другие, более сложные алгоритмы.
, чем пользуются другие, более сложные алгоритмы.
Эффективные сортировки
Сортировка методом слияния
Многие алгоритмы имеют рекурсивную структуру: для решения поставленной задачи они вызывают сами себя несколько раз, решая вспомогательные подзадачи. Обычно, разбиение происходит на подзадачи, сходные с исходной, но имеющим меньший объём. Далее они рекурсивно решаются, после чего полученные решения комбинируются для получения решения исходной задачи. Такой подход к решению задачи называется методом «разделяй и властвуй». Этот метод включает в себя 3 пункта:
- Разделение задачи на несколько подзадач, которые представляют собой меньшие экземпляры той же задачи.
- Властвование над подзадачами путём их рекурсивного решения. Если размер задач становится достаточно мал, то они может быть решена непосредственно.
- Комбинирование решений подзадач в решение исходной задачи.
Типичный пример этого метода — сортировка методом слияния, суть которой заключается в следующем:
- Разделение-элементной сортируемой последовательности на две подпоследовательности по элементов.
- Рекурсивная сортировка подпоследовательности с использованием сортировки методом слияния.
- Соединение 2-х отсортированных подпоследовательности для получение окончательного отсортированного ответа.
 элементов.
элементов.Рекурсия останавливается тогда, когда длина сортируемой подпоследовательности становится равной 1, поскольку любая такая последовательность уже является отсортированной (тривиальный случай). Главной операцией является объединение двух осторированных последовательностей в ходе комбинирования. Её суть заключается в том, что из двух отсортированных последовательностей выбираются элементы в порядке их возрастания. Поскольку каждая из последовательностей уже отсортирована, то выбор осуществляется между 2-я значениями из разных подпоследовательностей, после чего наименьшее значение перемещается из своей подпоследовательности в комбинируемую.
Алгоритм на псевдокоде:
Быстрая сортировка
Основной алгоритм работы
- Выбрать опорный элемент (pivot).
- Разделение: изменить порядок элементов последовательностей таким образом, чтобы все элементы большие или равные, чем опорный элемент, находились после опорного элемента. После разделения опорный элемент будет находится на своём месте.
- Рекурсивно повторить предыдущие два шага обеих образовавшихся подпоследовательностей («слева» и «справа» от выбранного опорного элемента).
Недостатки алгоритма
Предложенный ниже алгоритм использует разбиение Ломуто, где опорным элементом для каждой последовательности, будет выступать последний её элемент. На отсортированной последовательности алгоритм деградирует до  .
.
Пирамидальная сортировка
Идея пирамидальной сортировки заключается в использовании такой структуры данных, как бинарная куча, являющаяся бинарным деревом со следующими ограничениями:
- Значение в любом узле не меньше, чем в любом из его потомков
- Бинарное дерево является полным
Для представления дерева через массив можно использовать следующую идею: на первой позиции находится корень бинарного дерева, тогда для каждого потомка будет верно, что его индекс определяется как  для левого потомка и
для левого потомка и  для правого потомка:
для правого потомка:

Алгоритм сводится к следующим шагам:
- Элементы входной последовательности необходимо переставить таким образом, чтобы они удовлетворяли условиям для бинарной кучи
- Обменять первый элемент с последним, убрать из рассмотрения данных элемент и выполнить операцию по восстановлению бинарной кучи, т.к. после обмена полученное дерево может не соответствовать ограничению 1
Функция, которая перемещает элемент вниз по дереву для восстановления свойств дерева будем называть Heapify:
Нашли ошибку в тексте? Выделите ошибку в тексте и нажмите Ctrl + Enter на любой странице сайта.
Источник



