
- Способы организации данных
- Классификация баз данных
- Вступление
- Классификация баз данных пи типу хранимых данных
- Классификация баз данных по обращению к ним
- Классификация БД по способу организации данных
- Модели БД
- Реляционная база данных
- Другие статьи раздела: База данных
- Что такое база данных — понятие база данных в информатике
- Функции СУБД обеспечивающие управление базой данных
- PhpMyAdmin на локальном сервере
- Способы организации данных
- Основные структуры данных. Матчасть. Азы
- Что такое структура данных?
- Какие бывают?
- Основные структуры данных.
- Массивы
- Бывают
- Основные операции
- Вопросы
- Стеки
- Основные операции
- Вопросы
- Очереди
- Основные операции
- Вопросы
- Связанный список
- Бывают
- Основные операции
- Вопросы
- Графы
- Бывают
- Встречаются в таких формах как
- Общие алгоритмы обхода графа
- Вопросы
- Деревья
- Три способа обхода дерева
- Вопросы
- Trie ( префиксное деревое )
- Вопросы
- Хэш таблицы
- Вопросы
- Список ресурсов
- Вместо заключения
Способы организации данных
Возможны следующие способы организации данных:
1. Последовательный, т.е. доступ к данным в порядке их следования.
Различают последовательные данные со следующей длиной записи:
— фиксированной, т.е. все порции данных, считываемых или записываемых в файл, имеют одинаковую протяженность (поле, содержащее длину записи, может располагаться в управляющих структурах файла.);
— переменной, т.е. данные содержат поле с указанием длины текущей записи непосредственно перед самой записью(это несколько увеличивает протяженность файла: если длина дополнительного поля равна четырем байтам, то накладные расходы есть учетверенное число записей; требуется дополнительное время на считывание или генерацию поля длины записи);
— неопределенной, т.е. длина текущей записи задается в программе, в операторе или группе машинных команд, реализующих доступ к данным (данные не требуют пространственных накладных расходов).
2. Прямой способ обеспечивает произвольную последовательность доступа к записям файла. Это становится возможным в результате нумерации записей. Доступ к некоторой записи осуществляется по номеру.
Прямая организация предполагает одинаковую длину всех записей, поскольку иначе невозможно обеспечить пересчет номера записи в абсолютный адрес на внешнем устройстве. Чтобы поддерживать прямую запись в файл, приходится размечать требуемое пространство на диске при создании файла.
Файл, созданный как последовательный, в дальнейшем может рассматриваться как имеющий прямую организацию.
3. Индексно-последовательный способ пытается совместить достоинства последовательного и прямого доступов к данным:
— гибкость структуры записи, присущая последовательной организации;
— быстрый доступ к произвольной записи, как в прямой организации;
— возможна высокая скорость поиска информации, соответствующей заданному критерию (контекстный поиск);
— с каждой записью, помимо поля длины связывается поле индекса – числа или строки, однозначно идентифицирующего данные в записи.
Индекс может быть встроен в запись, т.е. быть ее частью, или располагаться отдельно от нее. Протяженность индекса есть управляемая величина, которая содержится в структурах описания файла. Индексы всех записей сводятся в отдельную таблицу, где упорядочиваются в соответствии с заданным критерием и связываются с абсолютными адресами хранения на диске. Одновременно хранятся адреса всех записей, связанные с их номерами.
Доступ к записи возможен в последовательном режиме, в индексно-последовательном, в прямом.
Для добавления новых записей требуется резервирование пространства под элементы индексной таблицы.
4. Библиотечный позволяет объединять в пределах одного файла несколько самостоятельных разделов, связанных друг с другом только областью применения.
В файле поддерживается каталог – таблица, в которой именам разделов ставятся в соответствие относительные адреса начала разделов и их протяженности. Для ускорения поиска имена разделов в каталоге упорядочиваются. Переменная длина раздела в библиотеке не позволяет реализовать модификацию непосредственно в файле и обычно требует перезаписи всего файла с внесением изменений в каталог.
Контрольные вопросы
1. Сформулируйте определение системы на основе категории «целостность».
2. Чем принципиально отличаются реляционные модели от сетевых и иерархических?
3. В чем различие процедурных и декларативных языков управления (манипулирования) данными?
4. Сформулируйте основные способы организации данных.
5. В чем суть нормализации отношений?
ТЕМА 5. ИНФОРМАЦИОННЫЕ МОДЕЛИ ПРИНЯТИЯ РЕШЕНИЙ
Источник
Классификация баз данных
Вступление
Напомню, что база данных это большой объем данных, которая в ней хранится, может обрабатываться, дополняться, удаляться, причем в удобной для пользователя форме. Также нужно четко понимать, что в БД хранится не всякая информация, а информация, которую можно организовать по тем или иным свойствам. Например, большое количество различных фотографий или документов это не данные, а информация. Но мы можем организовать фотографии, например по сути: фото людей, фото животных, фото городов и т.д. или организовать их по размеру: большие, средние, маленькие. Организованная, таким образом информация превращается в данные и пригодна для автоматической обработки с использованием баз данных. Переходим к классификации баз данных.

Классификация баз данных пи типу хранимых данных
Базы данных, объединяющие документы, сгруппированные (организованные) по разным свойствам, классифицируются, как документальные БД.
Под документом понимается текстовой документ или ссылка на него. Документальные БД разделили по типу документов на полнотекстовые, реферативные (рефераты) и библиографические. Это деление не так важно, как важен способ хранения информации. Здесь следующее разделение: базы данных хранящие исходный документ или хранящие ссылки, по которым можно обратиться к исходному документу.
Фактографические БД объединяют данные по факту совершения события (дата выпуска товара, год рождения сотрудника).
Лексикографические БД объединяют словари, классификаторы, и т.л. документы.
Характерным примером, документальных баз данных могут послужить базы объединяющие документы по нормативным «формам». Вы встречались с такими документами, например в паспортом столе или отделе кадров, заполняя «бумажку» по форме № такой то.
Классификация баз данных по обращению к ним
Базы данных индивидуального пользования классифицируют, как персональные или локальные базы данных.
Интегрированные иначе централизованные базы данный предоставляют коллективный доступ к данным. Такой доступ может быть как многопользовательский (сразу все), так и параллельный (независимый).
Распределительные базы данных аналогичны интегрированным, но могут быть физически разнесены на разные машины, и при этом логически считаться единым целым.
Перечисленные выше классификации не особо интересны пользователям. Для пользователя интересна классификация по способу организации данных и по типу используемой модели.
Классификация БД по способу организации данных
Не буду останавливаться на неструктурированных и частично структурированных базах данных. Они имеют узкое применение. Более важно понятие структурированной базы данных, в которых данные хранятся по предварительно спроектированной модели.
Модели БД
Моделями структурированной БД могут быть:
- БД иерархической модели;
- Сетевой модели;
- И самой используемой моделью БД – реляционной базой данных.
Реляционная база данных
Реляционная база данных самая используемая и самая математическая модель БД. Эта модель используется везде, где есть формализованная информация. Основа этой модели таблица, а взаимоотношения данных происходят по «доменам», «атрибутам», «кортежам» или более понятно и знакомо, по «типам данных», «столбцам» и «строкам».
В завершении замечу, что классификации БД перечисленных в статье, с уверенностью применяются для классификации СУБД.
Другие статьи раздела: База данных

Что такое база данных — понятие база данных в информатике
Содержание статьи: Что такое база данных в информатикеЧто такое СУБД и SQLСУБД MySQLСтатьи по теме “База данных” Информация основа современного общества. Объем ее огромен и растет с каждым годом. Огромный объем информации уже давно поставил задачу ее хранения и обработки. Решает эту задачу понятие база данных. Похожие статьи: Что такое целевой рынок, как его найти […]

Функции СУБД обеспечивающие управление базой данных
В этой статье вы познакомитесь с основными функциями СУБД системами управления базами данных.

PhpMyAdmin на локальном сервере
В этой статье мы рассматриваем работу с phpMyAdmin на локальном сервере, то есть в рамках настольного компьютера.
Источник
Способы организации данных




![]()
![]()
Существует два способа организации данных на листе: таблица и список.
При организации данных в виде таблицы формируются строки и столбцы с записями, для которых в ячейку на пересечении строки и столбца помещаются данные. Например, на рис. 5.1 показана таблица уровня образования студентов Интернет-Университета по годам: года размещены в строках, а количество студентов соответствующего уровня образования – в столбцах.
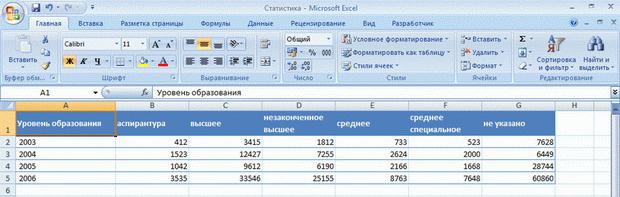
Рис. 5.1. Табличный способ организации данных
Таблицы могут иметь весьма сложную структуру с несколькими уровнями записей в строках и столбцах.
Табличный способ обеспечивает, как правило, более компактное размещение данных на листе. Для данных, организованных табличным способом, удобнее создавать диаграммы; в отдельных случаях удобнее производить вычисления. С другой стороны, данные, организованные в виде таблицы, сложнее обрабатывать: производить выборки, сортировки и т. п.
Другой способ организации данных – список. Список – набор строк листа, содержащий однородные данные; первая строка содержит заголовки столбцов, остальные строки содержат однотипные данные в каждом столбце.
В виде списка можно представлять как данные информационного характера (номера телефонов, адреса и т. п.), так и данные, подлежащие вычислениям.
Представление данных в виде списка обеспечивает большее удобство при сортировках, выборках, подведении итогов и т. п. С другой стороны, в этом случае затруднено построение диаграмм, снижается наглядность представления данных на листе.
Одни и те же данные можно представить как в виде таблицы, так и в виде списка. Например, в списке на рис. 5.2 представлены данные, организованные как таблица на рис. 5.1.
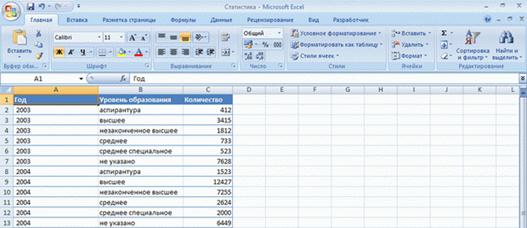
Рис. 5.2. Организация данных в виде списка
Нет каких-либо конкретных рекомендаций по использованию того или иного способа организации данных на листе. В каждом случае оптимальный способ выбирают исходя из решаемых задач.
Поскольку термин «таблица» является более традиционным, здесь и далее массив данных будет называться таблицей, кроме тех случаев, когда способ организации имеет принципиальное значение.
Источник
Основные структуры данных. Матчасть. Азы
Все чаще замечаю, что современным самоучкам очень не хватает матчасти. Все знают языки, но мало основы, такие как типы данных или алгоритмы. Немного про типы данных.
Еще в далеком 1976 швейцарский ученый Никлаус Вирт написал книгу Алгоритмы + структуры данных = программы.
40+ лет спустя это уравнение все еще верно. И если вы самоучка и надолго в программировании пробегитесь по статье, можно по диагонали. Можно код кофе.

В статье так же будут вопросы, которое вы можете услышать на интервью.
Что такое структура данных?
Структура данных — это контейнер, который хранит данные в определенном макете. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Какие бывают?
Линейные, элементы образуют последовательность или линейный список, обход узлов линеен. Примеры: Массивы. Связанный список, стеки и очереди.
Нелинейные, если обход узлов нелинейный, а данные не последовательны. Пример: граф и деревья.
Основные структуры данных.
Массивы
Массив — это самая простая и широко используемая структура данных. Другие структуры данных, такие как стеки и очереди, являются производными от массивов.
Изображение простого массива размера 4, содержащего элементы (1, 2, 3 и 4).
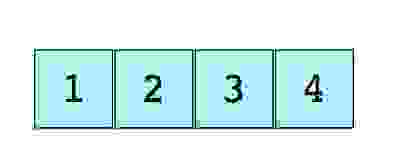
Каждому элементу данных присваивается положительное числовое значение (индекс), который соответствует позиции элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Бывают
Одномерные, как показано выше.
Многомерные, массивы внутри массивов.
Основные операции
Вопросы
Стеки
Стек — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Это не массивы. Это очередь. Придумал Алан Тюринг.
Примером стека может быть куча книг, расположенных в вертикальном порядке. Для того, чтобы получить книгу, которая где-то посередине, вам нужно будет удалить все книги, размещенные на ней. Так работает метод LIFO (Last In First Out). Функция «Отменить» в приложениях работает по LIFO.
Изображение стека, в три элемента (1, 2 и 3), где 3 находится наверху и будет удален первым.
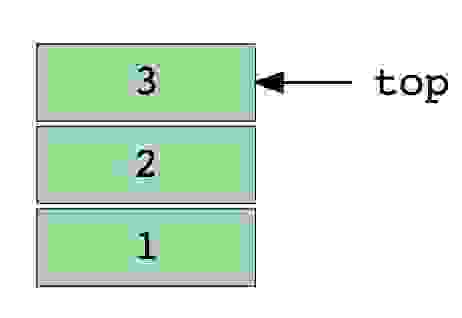
Основные операции
Вопросы
Очереди
Подобно стекам, очередь — хранит элемент последовательным образом. Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.
Пример очереди – очередь людей. Последний занял последним и будешь, а первый первым ее и покинет.
Изображение очереди, в четыре элемента (1, 2, 3 и 4), где 1 находится наверху и будет удален первым

Основные операции
Вопросы
Связанный список
Связанный список – массив где каждый элемент является отдельным объектом и состоит из двух элементов – данных и ссылки на следующий узел.
Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Бывают
Однонаправленный, каждый узел хранит адрес или ссылку на следующий узел в списке и последний узел имеет следующий адрес или ссылку как NULL.
Двунаправленный, две ссылки, связанные с каждым узлом, одним из опорных пунктов на следующий узел и один к предыдущему узлу.
Круговой, все узлы соединяются, образуя круг. В конце нет NULL. Циклический связанный список может быть одно-или двукратным циклическим связанным списком.
Самое частое, линейный однонаправленный список. Пример – файловая система.

Основные операции
Вопросы
Графы
Граф-это набор узлов (вершин), которые соединены друг с другом в виде сети ребрами (дугами).

Бывают
Ориентированный, ребра являются направленными, т.е. существует только одно доступное направление между двумя связными вершинами.
Неориентированные, к каждому из ребер можно осуществлять переход в обоих направлениях.
Смешанные
Встречаются в таких формах как
Общие алгоритмы обхода графа
Вопросы
Деревья
Дерево-это иерархическая структура данных, состоящая из узлов (вершин) и ребер (дуг). Деревья по сути связанные графы без циклов.
Древовидные структуры везде и всюду. Дерево скилов в играх знают все.
Типы деревьев
- N дерево
- Сбалансированное дерево
- Бинарное дерево
- Дерево Бинарного Поиска
- AVL дерево
- 2-3-4 деревья
Бинарное дерево самое распространенное.
«Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. » — Procs
Три способа обхода дерева
Вопросы
Trie ( префиксное деревое )
Разновидность дерева для строк, быстрый поиск. Словари. Т9.
Вот как такое дерево хранит слова «top», «thus» и «their».
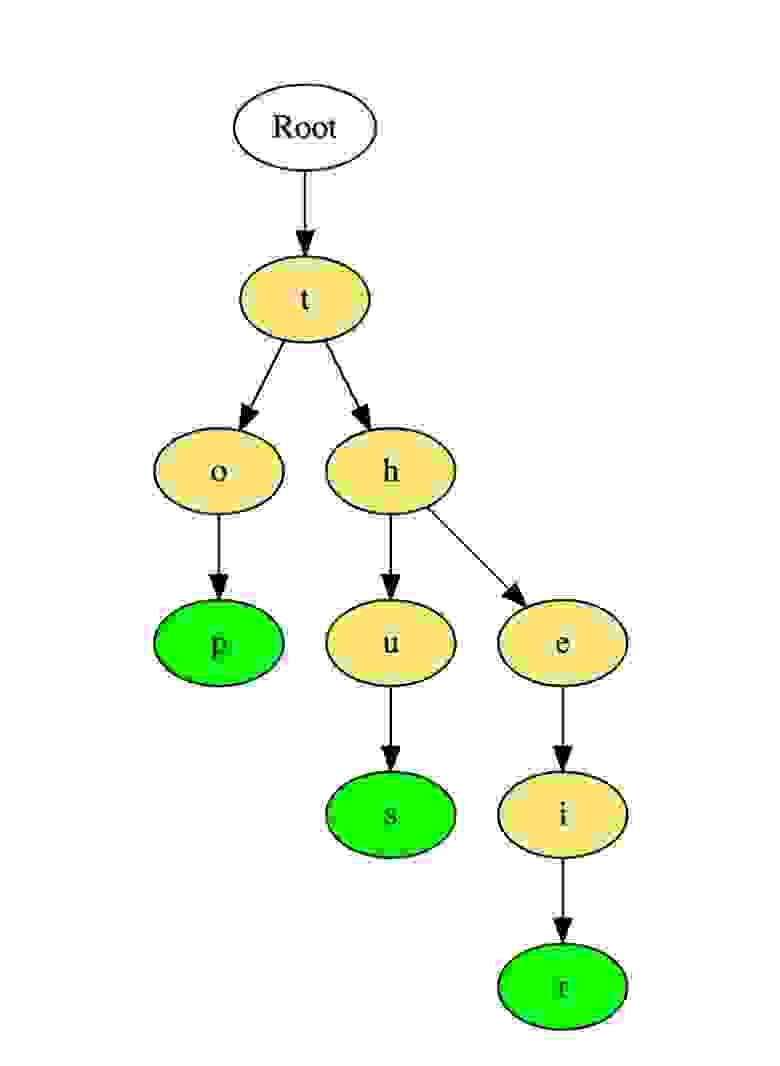
Слова хранятся сверху вниз, зеленые цветные узлы «p», «s» и «r» указывают на конец «top», «thus « и «their» соответственно.
Вопросы
Хэш таблицы
Хэширование — это процесс, используемый для уникальной идентификации объектов и хранения каждого объекта в заранее рассчитанном уникальном индексе (ключе).
Объект хранится в виде пары «ключ-значение», а коллекция таких элементов называется «словарем». Каждый объект можно найти с помощью этого ключа.
По сути это массив, в котором ключ представлен в виде хеш-функции.
Эффективность хеширования зависит от
- Функции хеширования
- Размера хэш-таблицы
- Метода борьбы с коллизиями
Пример сопоставления хеша в массиве. Индекс этого массива вычисляется через хэш-функцию. 
Вопросы
Список ресурсов
Вместо заключения
Матчасть так же интересна, как и сами языки. Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.
Спасибо, что прочли. Надеюсь не зря потратили время =)
PS: Прошу извинить, как оказалось, перевод статьи уже был тут и очень недавно, я проглядел.
Если интересно, вот она, спасибо Hokum, буду внимательнее.
Источник



