
- Шифрование сообщений в Python. От простого к сложному. Шифр Цезаря
- Немного о проекте
- Шифр Цезаря
- Что это такое?
- Какими особенностями он обладает?
- Программная реализация
- Дешифровка сообщения
- Итоговый вид программы
- Шифр Цезаря на Python (руководство по шифрованию текста)
- Что такое шифр Цезаря?
- Шифр Цезаря в Python на примере английского алфавита
- Функция ord()
- Функция chr()
- Шифрование заглавных букв
- Расшифровка прописных букв
- Шифрование цифр и знаков препинания
- Решение
- Использование таблицы поиска
- Что такое таблица поиска?
- Создание таблицы поиска
- Внедрение шифрования
- Отрицательное смещение
- Шифрование файлов
- Множественные смещения (шифрование по Виженеру)
- Почему шифрование слабое?
- Атака методом перебора
- Заключение
Шифрование сообщений в Python. От простого к сложному. Шифр Цезаря
Немного о проекте
Мне, лично, давно была интересна тема шифрования информации, однако, каждый раз погрузившись в эту тему, я осознавал насколько это сложно и понял, что лучше начать с чего-то более простого. Я, лично, планирую написать некоторое количество статей на эту тему, в которых я покажу вам различные алгоритмы шифрования и их реализацию в Python, продемонстрирую и разберу свой проект, созданный в этом направлении. Итак, начнем.
Для начала, я бы хотел рассказать вам какие уже известные алгоритмы мы рассмотрим, в моих статьях. Список вам представлен ниже:
Шифр Цезаря
Итак, после небольшого введения в цикл, я предлагаю все-таки перейти к основной теме сегодняшней статьи, а именно к Шифру Цезаря.
Что это такое?
Шифр Цезаря — это простой тип подстановочного шифра, где каждая буква обычного текста заменяется буквой с фиксированным числом позиций вниз по алфавиту. Принцип его действия можно увидеть в следующей иллюстрации:
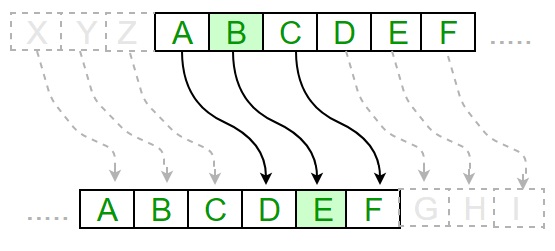
Какими особенностями он обладает?
У Шифра Цезаря, как у алгоритма шифрования, я могу выделить две основные особенности. Первая особенность — это простота и доступность метода шифрования, который, возможно поможет вам погрузится в эту тему, вторая особенность — это, собственно говоря, сам метод шифрования.
Программная реализация
В интернете существует огромное множество уроков, связанных с криптографией в питоне, однако, я написал максимально простой и интуитивно понятный код, структуру которого я вам продемонстрирую.
Начнем, пожалуй, с создания алфавита. Для этого вы можете скопировать приведенную ниже строку или написать все руками.
Далее, нам нужно обозначить программе шаг, то есть смещение при шифровании. Так, например, если мы напишем букву «а» в сообщении, тот при шаге «2», программа выведет нам букву «в».
Итак, создаем переменную smeshenie, которая будет вручную задаваться пользователем, и message, куда будет помещаться наше сообщение, и, с помощью метода upper(), возводим все символы в нашем сообщении в верхний регистр, чтобы у нас не было ошибок. Потом создаем просто пустую переменную itog, куда мы буем выводить зашифрованное сообщение. Для этого пишем следующее:
Итак, теперь переходим к самому алгоритму шифровки. Первым делом создаем цикл for , где мы определим место букв, задействованных в сообщении, в нашем списке alfavit, после чего определяем их новые места (далее я постараюсь насытить код с пояснениями):
Далее, мы создаем внутри нашего цикла условие if , в нем мы записываем в список itog мы записываем наше сообщение уже в зашифрованном виде и выводим его:
Модернизация
Вот мы и написали программу, однако она имеет очень большой недостаток: «При использовании последних букв(русских), программа выведет вам английские буквы. Давайте это исправим.
Для начала создадим переменную lang, в которой будем задавать язык нашего шифра, а так же разделим английский и русский алфавиты.
Теперь нам надо создать условие, которое проверит выбранный язык и применит его, то есть обратится к нужному нам алфавиту. Для этого пишем само условие и добавляем алгоритм шифрования, с помощью которого будет выполнено шифрование:
Дешифровка сообщения
Возможно это прозвучит несколько смешно, но мы смогли только зашифровать сообщение, а насчет его дешифровки мы особо не задумывались, но теперь дело дошло и до неё.
По сути, дешифровка — это алгоритм обратный шифровке. Давайте немного переделаем наш код (итоговый вид вы можете увидеть выше).
Для начала, я предлагаю сделать «косметическую» часть нашей переделки. Для этого перемещаемся в самое начало кода:
Остальное можно оставить так же, но если у вас есть желание, то можете поменять названия переменных.
По большому счету, самые ‘большие’ изменения у нас произойдут в той части кода, где у нас находится алгоритм, где нам нужно просто поменять знак «+» на знак «-«. Итак, переходим к самому циклу:
Итоговый вид программы
Итак, вот мы и написали простейшую программу для шифрования методом Цезаря. Ниже я размещу общий вид программы без моих комментариев, чтобы вы еще раз смогли сравнить свою программу с моей:
Вы успешно написали алгоритм шифровки и дешифровки сообщения на Python с помощью метода Цезаря. В следующей статье мы с вами рассмотрим Шифр Виженера, а также разберем его реализацию на Python, а пока я предлагаю вам написать в комментариях варианты модернизации программы(код или просо предложения и пожелания). Я обязательно учту ваше мнение.
Источник
Шифр Цезаря на Python (руководство по шифрованию текста)
Криптография занимается шифрованием или кодированием части информации в форме, которая выглядит как белиберда и не имеет смысла в обычном языке.
Это закодированное сообщение (также называемое зашифрованным текстом) может быть расшифровано обратно предполагаемым получателем с помощью техники дешифрования (часто в сочетании с закрытым ключом), переданной конечному пользователю.
Шифр Цезаря – один из старейших методов шифрования, на котором мы сосредоточимся в этом руководстве, и реализуем его в Python.
Хотя шифр Цезаря является очень слабой техникой шифрования и редко используется сегодня, мы делаем этот материал, чтобы познакомить наших читателей, особенно новичков, с шифрованием.
Считайте это “Hello World” криптографии.
Что такое шифр Цезаря?
Шифр Цезаря – это тип подстановочного шифра, в котором каждая буква открытого текста заменяется другой буквой в некоторых фиксированных позициях текущей буквы алфавита.
Например, если мы сдвинем каждую букву на три позиции вправо, то каждая из букв нашего открытого текста будет заменена буквой, находящейся на три позиции правее.
Давайте посмотрим это в действии – зашифруем текст “HELLO WORLD”, используя правый сдвиг на 3.
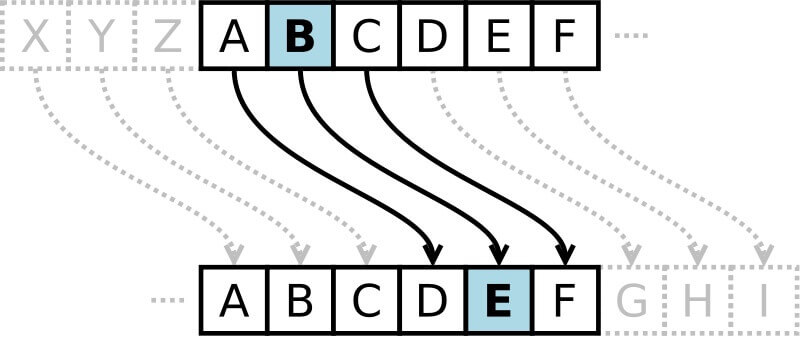
Так, буква H будет заменена на K, E – на H, и так далее.
В итоге зашифрованным сообщением для HELLO WORLD будет KHOOR ZRUOG. Эта тарабарщина не имеет смысла, не так ли?
Обратите внимание, что буквы на краю, т.е. X, Y, Z, сворачиваются и заменяются на A, B, C, соответственно.
Аналогично, буквы в начале – A, B, C и т.д. – будет повернут в случае сдвига влево.
Правило шифрования шифра Цезаря можно выразить математически как:
Где c – кодированный символ, x – реальный символ, а n – количество позиций, на которые мы хотим сдвинуть символ x.
В случае с английским алфавитом мы берем mod с 26, потому что в нем 26 букв (в русском это было бы 33).
Шифр Цезаря в Python на примере английского алфавита
Прежде чем мы погрузимся в определение функций для процесса шифрования и расшифровки шифра Цезаря в Python, мы сначала рассмотрим две важные функции, которые мы будем использовать в процессе – chr() и ord().
Важно понимать, что алфавит в том виде, в котором мы его знаем, хранится в памяти компьютера по-разному.
Сам компьютер не понимает алфавит английского языка или другие символы.
Каждый из этих символов представлен в памяти компьютера с помощью числа, называемого кодом символов ASCII (или его расширением – Unicode), который представляет собой 8-битное число и кодирует почти все символы, цифры и пунктуацию.
Например, заглавная буква “А” представлена числом 65, “В” – 66 и так далее. Аналогично, представление строчных символов начинается с числа 97.
Когда возникла необходимость включить больше символов и знаков из других языков, 8 бит оказалось недостаточно, поэтому был принят новый стандарт – Unicode, который представляет все используемые в мире символы с помощью 16 бит.
ASCII является подмножеством Unicode, поэтому кодировка символов ASCII остается такой же в Unicode. Это означает, что ‘A’ все равно будет представлено с помощью числа 65 в Юникоде.
Обратите внимание, что специальные символы, такие как пробел ” “, табуляция “\t”, новая строка “\N” и т.д., также представлены в памяти своим Юникодом.
Мы рассмотрим две встроенные функции Python, которые используются для поиска представления символа в Unicode и наоборот.
Функция ord()
Вы можете использовать метод ord() для преобразования символа в его числовое представление Unicode.
Он принимает один символ и возвращает число, которое представляет его Unicode.

Функция chr()
Точно так же, как при преобразовании символа в его числовой Юникод с помощью метода ord(), мы делаем обратное, то есть находим символ, представленный числом, с помощью метода chr().
Метод chr() принимает число, представляющее Unicode символа, и возвращает фактический символ, соответствующий числовому коду.
Давайте сначала рассмотрим несколько примеров:
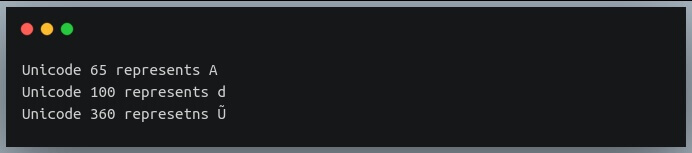
Обратите внимание, что немецкая буква Ü также представлена в Юникоде числом 360.
Мы можем применить процедуру цепочки (ord, затем chr), чтобы восстановить исходный символ.
Шифрование заглавных букв
Теперь, когда мы понимаем два фундаментальных метода, которые мы будем использовать, давайте реализуем технику шифрования для верхнего регистра в Python.
Мы зашифруем только заглавные символы в тексте, а остальные оставим без изменений.
Давайте сначала рассмотрим пошаговый процесс шифрования заглавных букв:
- Определите величину смещения, то есть количество позиций, на которые мы хотим переместить каждый символ.
- Итерация по каждому символу обычного текста:
- Если символ в верхнем регистре:
- Вычислить позицию/индекс символа в диапазоне 0-25.
- Выполните положительное смещение, используя операцию modulo.
- Найдите символ в новой позиции.
- Замените текущую заглавную букву на этот новый символ.
- В противном случае, если символ не является заглавным, сохраните его без изменений.
- Если символ в верхнем регистре:
Теперь посмотрим на код:

Как мы видим, зашифрованный текст “HELLO WORLD” – это “KHOOR ZRUOG”, и он совпадает с тем, к которому мы пришли вручную в разделе “Введение”.
Кроме того, этот метод не шифрует символ пробела, и в зашифрованном варианте он остается пробелом.
Расшифровка прописных букв
Теперь, когда мы разобрались с шифрованием открытого текста с помощью шифра Цезаря в верхнем регистре, давайте посмотрим, как мы будем расшифровывать шифрованный текст в открытый.
Ранее мы рассмотрели математическую формулировку процесса шифрования. Теперь проверим то же самое для процесса расшифровки.
Смысл обозначений остается таким же, как и в предыдущей формуле.
Если после вычитания какое-либо значение становится отрицательным, оператор modulus позаботится об этом и обернет его.
Давайте рассмотрим пошаговую реализацию процесса расшифровки, который будет более или менее противоположен шифрованию:
- Определите количество смен
- Итерация по каждому символу зашифрованного текста:
- Если символ является заглавной буквой:
- Вычислить позицию/индекс символа в диапазоне 0-25.
- Выполните отрицательный сдвиг, используя операцию modulo.
- Найдите символ в новой позиции.
- Замените текущую зашифрованную букву на этот новый символ (который также будет заглавной буквой).
- В противном случае, если символ не является заглавным, оставьте его без изменений.
- Если символ является заглавной буквой:
Давайте напишем код для приведенной выше процедуры:

Обратите внимание, как мы успешно восстановили оригинальный текст “HELLO WORLD” из его зашифрованной формы.
Шифрование цифр и знаков препинания
Теперь, когда мы увидели, как можно кодировать и декодировать заглавные буквы английского алфавита с помощью шифра Цезаря, возникает важный вопрос – а как насчет других символов?
Как насчет цифр, как насчет специальных символов и знаков препинания?
Так, первоначальный алгоритм шифра Цезаря не должен был иметь дело ни с чем, кроме 26 букв алфавита, ни с прописными, ни со строчными.
Поэтому типичный шифр Цезаря не шифрует пунктуацию или цифры, а переводит все буквы в строчные или прописные и шифрует только эти символы.
Итак, мы попытаемся закодировать заглавные и строчные символы так, как мы это делали в предыдущем разделе, игнорируя пока пунктуацию, а затем мы также закодируем цифры в тексте.
Для чисел мы можем выполнить кодирование одним из двух способов:
- Сдвинуть значение цифр на столько же, на сколько сдвинуты буквы алфавита, то есть при сдвиге на 3 – цифра 5 становится 8, 2 – 5, 9 – 2 и так далее.
- Сделать цифры частью алфавита, т.е. за z или Z будут следовать 0,1,2. до 9, и на этот раз наш делитель для выполнения модуля будет 36, а не 26.
Мы реализуем наше решение, используя первую стратегию. Кроме того, на этот раз мы реализуем наше решение в виде функции, принимающей в качестве параметра значение смещения (которое служит ключом в Cesar Encryption).
Мы реализуем 2 функции: cipher_encrypt() и cipher_decrypt().
Решение
Теперь, когда мы определили наши две функции, давайте сначала воспользуемся функцией шифрования, чтобы зашифровать секретное сообщение, которое друг передает через текстовое сообщение своему другу.
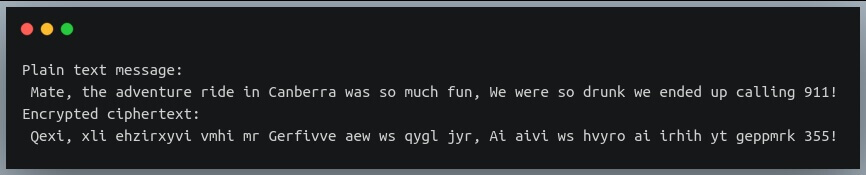
Обратите внимание, что все, кроме знаков препинания и пробелов, зашифровано.
Теперь давайте посмотрим на шифрованный текст, который полковник Ник Фьюри посылал на свой пейджер: “Mr xli gsyrx sj 7, 6, 5 – Ezirkivw Ewwiqfpi!”.
Это оказывается шифротекст Цезаря, и, к счастью, ключ к этому шифру у нас в руках.
Давайте посмотрим, сможем ли мы обнаружить скрытое послание.
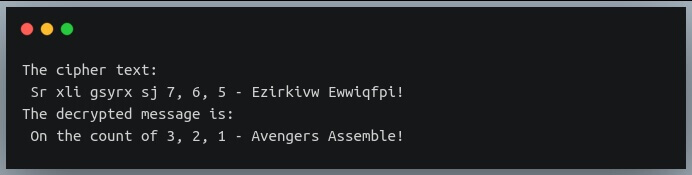
Отличная работа, Мстители!
Использование таблицы поиска
На данном этапе мы разобрались в процессе шифрования и расшифровки шифра Цезаря и реализовали его в Python.
Теперь мы посмотрим, как можно сделать его более эффективным и гибким.
В частности, мы сосредоточимся на том, как можно избежать повторных вычислений измененных позиций для каждой буквы в тексте в процессе шифрования и расшифровки, заранее построив таблицу поиска.
Мы также увидим, как можно использовать в процессе шифрования любой набор символов, заданных пользователем, а не только буквы алфавита.
Мы также объединим процесс шифрования и дешифрования в одну функцию и будем принимать в качестве параметра, какой из двух процессов хочет запустить пользователь.
Что такое таблица поиска?
Таблица поиска – это просто отображение исходных символов и символов, которые должны быть переведены в зашифрованную форму.
До сих пор мы итерировали каждую букву в строке и вычисляли их измененные позиции.
Это неэффективно, поскольку наш набор символов ограничен, и большинство из них встречается в строке более одного раза.
Поэтому вычисление их зашифрованной эквивалентности каждый раз, когда они встречаются, неэффективно и становится дорогостоящим, если мы шифруем очень длинный текст с сотнями тысяч символов в нем.
Мы можем обойти это, вычисляя измененные позиции каждого из символов в нашем наборе символов только один раз перед началом процесса шифрования.
Таким образом, если есть 26 заглавных и 26 строчных букв, нам потребуется всего 52 вычисления один раз и некоторое количество памяти для хранения этого отображения.
Тогда в процессе шифрования и дешифрования нам нужно будет только выполнить “поиск” в этой таблице – операция, которая быстрее, чем каждый раз выполнять операцию модуляции.
Создание таблицы поиска
Строковый модуль Python предоставляет простой способ не только создать таблицу поиска, но и перевести любую новую строку на основе этой таблицы.
Рассмотрим пример, когда мы хотим создать таблицу первых пяти строчных букв и их индексов в алфавите.
Затем мы используем эту таблицу для перевода строки, в которой все символы “a”, “b”, “c”, “d” и “e” заменены на “0”, “1”, “2”, “3” и “4” соответственно, а остальные символы не тронуты.
Для создания таблицы мы будем использовать функцию maketrans() модуля str.
Этот метод принимает в качестве первого параметра строку символов, для которых требуется перевод, и другой параметр такой же длины, содержащий сопоставленные символы для каждого символа первой строки.
Давайте создадим таблицу для простого примера.
Таблица представляет собой словарь Python, в котором в качестве ключей указаны значения символов Unicode, а в качестве значений – их соответствующие отображения.
Теперь, когда у нас есть готовая таблица, мы можем переводить строки любой длины с помощью этой таблицы.
К счастью, за перевод отвечает другая функция модуля str, называемая translate.
Давайте используем этот метод для преобразования нашего текста с помощью нашей таблицы.
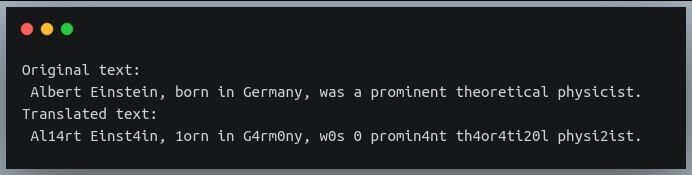
Как вы можете видеть, каждый экземпляр первых пяти строчных букв был заменен их относительными индексами.
Теперь мы используем ту же технику для создания таблицы поиска для шифра Цезаря на основе предоставленного ключа.
Внедрение шифрования
Давайте создадим функцию caesar_cipher(), которая принимает строку для шифрования/дешифрования, “набор символов”, показывающий, какие символы в строке должны быть зашифрованы (по умолчанию это будет строчный регистр),
ключ, а также булево значение, показывающее, была ли произведена расшифровка (шифрование) или нет.
Это очень мощная функция!
Вся операция смены была сведена к операции нарезки.
Кроме того, мы используем атрибут string.ascii_lowercase – это строка символов от “a” до “z”.
Еще одна важная особенность, которой мы здесь достигли, заключается в том, что одна и та же функция обеспечивает как шифрование, так и дешифрование; это можно сделать, изменив значение параметра ‘key’.
Операция вырезания вместе с этим новым ключом гарантирует, что набор символов был сдвинут влево – то, что мы делаем при расшифровке сдвинутого вправо шифротекста Цезаря.
Давайте проверим, работает ли это на предыдущем примере.
Мы зашифруем только заглавные буквы текста и передадим то же самое параметру “characters”.
Зашифруем текст: “HELLO WORLD! Welcome to the world of Cryptography!”.

Посмотрите, как часть “KHOOR ZRUOG” соответствует шифрованию “HELLO WORLD” с ключом 3 в нашем первом примере.
Также обратите внимание, что мы указываем набор символов для заглавных букв с помощью string.ascii_uppercase.
Мы можем проверить, правильно ли работает расшифровка, используя тот же зашифрованный текст, который мы получили в нашем предыдущем результате.
Если мы можем получить наш исходный текст, значит, наша функция работает идеально.

Обратите внимание, как мы установили параметр “decrypt” нашей функции в True.
Поскольку мы восстановили наш оригинальный текст, это признак того, что наш алгоритм шифрования-дешифрования с использованием таблицы поиска работает отлично!
Теперь давайте посмотрим, можно ли расширить набор символов, включив в него не только строчные и прописные символы, но и цифры и знаки препинания.
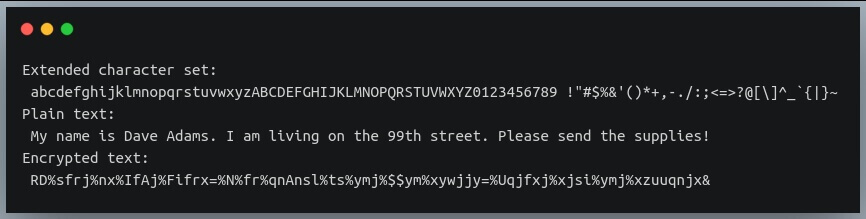
Здесь мы включаем все символы, которые мы обсуждали до сих пор (включая символ пробела), в набор символов для кодирования.
В результате все (даже пробелы) в нашем обычном тексте было заменено другим символом!
Единственное отличие заключается в том, что обертывание происходит не по отдельности для строчных и прописных символов, а в целом для набора символов.
Это означает, что “Y” со смещением 3 не станет “B”, а будет закодирован как “1”.
Отрицательное смещение
До сих пор мы выполняли “положительный” или “правый” сдвиг символов в процессе шифрования. А процесс дешифровки для него же включал “отрицательный” или “левый” сдвиг символов.
Но что если мы хотим выполнить процесс шифрования с отрицательным сдвигом – изменится ли наш алгоритм шифрования-дешифрования?
Да, будет, но только немного. Единственное изменение, которое нам необходимо для сдвига влево, – это сделать знак ключа отрицательным, остальная часть процесса останется неизменной и позволит добиться результата сдвига влево в процессе шифрования и сдвига вправо в процессе расшифровки.
Давайте попробуем это сделать, изменив нашу предыдущую функцию, добавив еще один параметр – ‘shift_type’ в нашу функцию cipher_cipher_using_lookup().
Давайте попробуем этот модифицированный метод на простом тексте:

Обратите внимание, что каждый из символов нашего обычного текста сдвинут на три позиции влево.
Теперь проверим процесс расшифровки с помощью той же строки.

Таким образом, мы можем зашифровать и расшифровать текст, используя таблицу поиска и отрицательный ключ.
Шифрование файлов
В этом разделе мы рассмотрим, как использовать Caesar Encryption для шифрования файла.
Обратите внимание, что мы можем шифровать только обычные текстовые файлы, а не двоичные, потому что мы знаем набор символов обычных текстовых файлов.
Поэтому вы можете зашифровать файл, используя один из следующих двух подходов:
- Считать весь файл в строку, зашифровать строку и сбросить ее в другой файл.
- Прочитайте файл по одной строке за раз, зашифруйте строку и запишите ее в другой текстовый файл.
Мы будем придерживаться второго подхода, поскольку первый возможен только для небольших файлов, содержимое которых легко помещается в памяти.
Итак, давайте определим функцию, которая принимает файл и шифрует его с помощью шифра Цезаря со сдвигом вправо на 3. Мы будем использовать набор символов по умолчанию – строчные буквы.
Функция принимает имя входного файла, имя выходного файла и параметры шифрования/дешифрования, которые мы рассматривали в предыдущем разделе.
Зашифруем файл ‘milky_way.txt’ (он содержит вводный абзац со страницы “Млечный путь” в Википедии).
Мы выведем зашифрованный файл в ‘milky_way_encrypted.txt’.
Мы собираемся зашифровать его с помощью функции, которую мы определили ранее:

Давайте проверим, как теперь выглядит наш зашифрованный файл ‘Milky_way_encrypted.txt’:
Таким образом, наша функция успешно шифрует файл.
В качестве упражнения вы можете проверить функцию decrypt, передав путь к зашифрованному файлу в качестве входных данных и установив параметр ‘decrypt’ в True.
Проверьте, сможете ли вы восстановить исходный текст.
Убедитесь, что вы не передаете один и тот же путь к файлу в качестве входного и выходного данных, что приведет к нежелательным результатам, поскольку программа будет выполнять операции чтения и записи в один и тот же файл одновременно.
Множественные смещения (шифрование по Виженеру)
До сих пор мы использовали одно значение сдвига (ключ) для сдвига всех символов в строках на одинаковое количество позиций.
Мы также можем попробовать вариант, в котором мы будем использовать не одну клавишу, а последовательность клавиш для выполнения различных сдвигов в разных позициях текста.
Например, допустим, мы используем последовательность из 4 клавиш: 1,5,2,3] При таком методе наш первый символ в тексте сдвинется на одну позицию, второй – на пять позиций,
третий символ на две позиции, четвертый на три позиции, а затем снова пятый символ будет сдвинут на одну позицию, и так далее.
Это улучшенная версия шифра Цезаря, которая называется шифром Виженера.
Давайте применим шифр Виженера на практике.
Функция выполняет как шифрование, так и дешифрование, в зависимости от значения булевого параметра “decrypt”.
Мы отслеживаем общее количество зашифрованных/расшифрованных строчных букв с помощью переменной i, используем ее с оператором modulus, чтобы определить, какой ключ из списка использовать следующим.
Обратите внимание, что мы сделали операцию сдвига очень компактной; это эквивалентно многоэтапному процессу преобразования между Unicode и символьными значениями и вычисления сдвига, который мы видели ранее.
Давайте попробуем использовать эту функцию на примере другого простого текста:
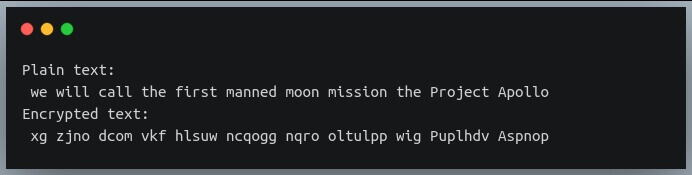
Здесь мы выполняем шифрование, используя ключи [1,2,3], и, как и ожидалось, первый символ “w” был сдвинут на одну позицию к “x”,
второй символ “e” сдвинут на две позиции к “g”; третий символ “w” сдвинут на три позиции к “z”.
Этот процесс повторяется со следующими символами.
Выполните процесс расшифровки с теми же ключами и посмотрите, сможете ли вы снова восстановить исходное заявление.
Почему шифрование слабое?
Как бы ни был прост в понимании и применении шифр Цезаря, он облегчает любому взлом дешифровки без особых усилий.
Шифр Цезаря – это метод подстановочного шифрования, при котором мы заменяем каждый символ в тексте некоторым фиксированным символом.
Если кто-то обнаружит регулярность и закономерность появления определенных символов в шифротексте, он быстро определит, что для шифрования текста был использован шифр Цезаря.
Если убедиться, что для шифрования текста использовалась техника шифра Цезаря, то восстановить оригинальный текст без ключа будет проще простого.
Простой алгоритм Brute Force вычисляет оригинальный текст за ограниченное время.
Атака методом перебора
Взлом шифротекста с помощью шифра Цезаря – это просто перебор всех возможных ключей.
Это осуществимо, потому что может существовать только ограниченное количество ключей, способных генерировать уникальный шифротекст.
Например, если в шифротексте зашифрованы все строчные буквы, то все, что нам нужно сделать, это запустить шаг расшифровки со значениями ключа от 0 до 25.
Даже если бы пользователь предоставил ключ выше 25, он выдал бы шифротекст, равный одному из шифротекстов, сгенерированных с ключами от 0 до 25.
Давайте рассмотрим шифротекст, в котором зашифрованы все строчные символы, и посмотрим, сможем ли мы извлечь из него разумный шифротекст с помощью атаки “методом перебора”.
У нас есть текст:
Сначала определим функцию расшифровки, которая принимает шифротекст и ключ и расшифровывает все его строчные буквы.
Теперь у нас есть наш текст, но мы не знаем ключа, т.е. значения смещения. Давайте напишем атаку методом перебора, которая пробует все ключи от 0 до 25 и выводит каждую из расшифрованных строк:
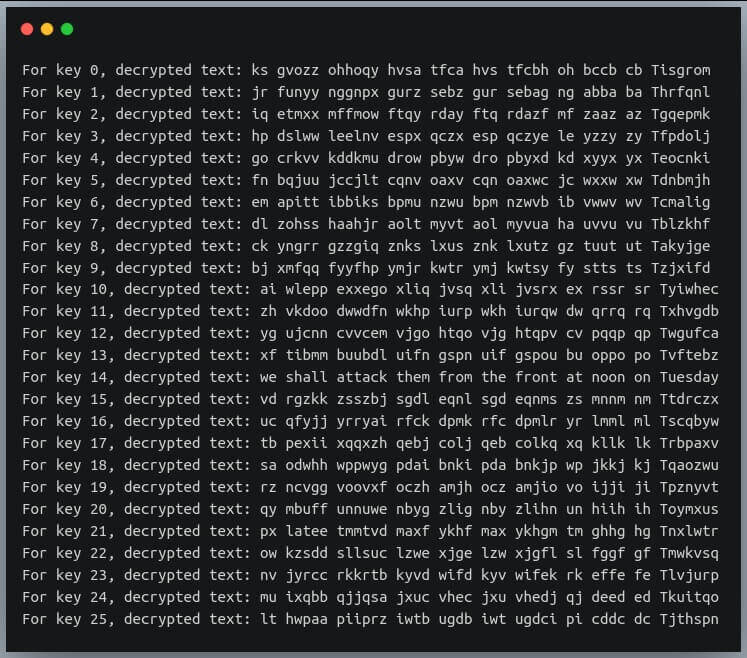
В выводе перечислены все строки, которые могут быть получены в результате расшифровки.
Если вы внимательно посмотрите, строка с ключом 14 является правильным английским высказыванием и поэтому является правильным выбором.

Теперь вы знаете, как взломать шифр с помощью шифра Цезаря.
Мы могли бы использовать другие более сильные варианты шифра Цезаря, например, с использованием нескольких сдвигов (шифр Виженера), но даже в этих случаях определенные злоумышленники могут легко расшифровать правильную расшифровку.
Поэтому алгоритм шифрования Цезаря относительно слабее современных алгоритмов шифрования.
Заключение
В этом учебнике мы узнали, что такое шифр Цезаря, как его легко реализовать в Python и как его реализация может быть дополнительно оптимизирована с помощью так называемых “таблиц поиска”.
Мы написали функцию Python для реализации общего алгоритма шифрования/дешифрования Caesar Cipher, который принимает несколько пользовательских входов в качестве параметра без особых предположений.
Затем мы рассмотрели, как можно зашифровать файл с помощью шифра Цезаря, а затем как шифр Цезаря можно усилить с помощью нескольких сдвигов.
Наконец, мы рассмотрели уязвимость шифра Цезаря к атакам методом брута.
Источник



