
- Как оценивать интеллект? Подход Google
- Конспект “On the Measure of Intelligence“
- Необходимо практически полезное определение интеллекта и его метрик
- Определение интеллекта: два противоречивых подхода
- Оценка ИИ: от оценки умений к оценке широких способностей
- Новая концепция
- Чего ожидать от идеального теста ИИ?
- Предлагаемый тест: массив данных ARC
Как оценивать интеллект? Подход Google
В ноябре 2019 года вышла программная статья от Google «Об оценке интеллекта» Франсуа Шолле (создатель Keras).
64 страницы посвящены тому, как появилось современное понимание ИИ, почему машинное обучение от него так далеко, и почему мы все еще не можем адекватно измерить «интеллект».

Чтобы отбор был честным, задание для всех одно: залезьте на дерево
Наша команда занимается NLP и общей методологией ИИ-тестов, учитывая последние тренды в универсальных трансформерах типа BERT, которые оцениваются тестами на логику и здравый смысл. Так, NLP забирает в себя все новые задачи, связанные с воспроизведением все более сложных действий и по сути отражающих механизмы мышления. Оказалось, что и другие области ML отхватили свой кусок пирога в этом направлении. Например, CV — «Animal AI Challenge».
Понятно, что сейчас “лучше” при возможности делать ML-модели более интерпретируемыми, не использовать 10 маленьких классификаторов, а тренировать одну модель, и так далее, но насколько это все-таки далеко от реального “интеллекта”?
Программная статья дает подробный и разгромный разбор исследований в сфере технической оценки современного ИИ.
В конце статьи автор предлагает свой собственный тест и датасет к нему: Abstraction and Reasoning Corpus (ARC), привязанный к абстрактному мышлению.
Но обо всем подробнее.
Конспект “On the Measure of Intelligence“
Чтобы сознательно создавать более интеллектуальные и более похожие на человека искусственные системы, нам требуется ясное определение интеллекта и умение оценивать его. Это нужно, чтобы корректно сравнивать две системы, или систему с человеком. За последнее столетие предпринималось много попыток определить и измерить интеллект как в области психологии, так и в области ИИ.
Современное ML-сообщество по-прежнему любит сравнивать умения, которые демонстрируют ИИ и люди – при игре в настольные и компьютерные игры, при решении задач. Но для оценки интеллекта мало измерить только умение решать поставленную задачу. Почему? Потому что это умение во многом формируется не интеллектом, а прежними знаниями и опытом. А их можно «купить». Скармливая системе неограниченный объём обучающих данных или предварительной информации, экспериментаторы могут не только вывести машину на произвольный уровень навыков, но и скрыть то, насколько способна к интеллектуальному обобщению сама система.
В статье предлагается 1) новое официальное определение интеллекта на основе эффективности приобретения навыков; 2) новый тест на способность формирования абстракций и логических выводов (Abstraction and Reasoning Corpus, ARC). ARC можно использовать для измерения человеческой формы сильного подвижного интеллекта, это позволяет численно сравнивать относительно сильный интеллект систем ИИ и человека.
Необходимо практически полезное определение интеллекта и его метрик
Цель развития ИИ – в создании машин с интеллектом, который сопоставим с интеллектом людей. (Так цель была сформулирована с момента зарождения искусственного интеллекта в начале 50-х годов ХХ века, и с тех пор эта формулировка сохраняется).
Но пока мы можем создавать системы, которые хорошо справляются с конкретными задачами. Эти системы несовершенны: они хрупки, требуют всё больше и больше данных, неспособны разобраться в примерах, слегка отклоняющихся от обучающей выборки, а также не могут перенастраиваться на решение новых задач без помощи людей.
Причина этого в том, что мы до сих пор не можем однозначно ответить на вопрос о том, что такое интеллект. Существующие тесты, например, тест Тьюринга [11] и премия Лёбнера [10], не могут служить драйверами прогресса, поскольку полностью исключают возможность объективно определить и измерить интеллект, а опираются на субъективную оценку.
Наша цель – указать на неявные предубеждения в отрасли, а также предложить имеющее практическую ценность формальное определение и критерии оценки сильного интеллекта, подобного интеллекту человека.
Определение интеллекта: два противоречивых подхода
Суммарное базовое определение ИИ звучит так: «Интеллект измеряет способность агента достигать целей в широком диапазоне сред». Ничего не объясняет?
Весь конфликт в современной науке сводится к тому, что считать отправной точкой естественного интеллекта:
- разум – статичный набор механизмов спецназначения, которые сформированы эволюцией для заведомо определенных задач. Эта точка зрения дарвинизма, эволюционной психологии и нейрофизиологов, поддерживающих концепцию биологической модулярности сознания.
Понимание разума как широкого набора вертикальных, относительно статичных программ, вместе образующих «интеллект», также развивал Марвин Мински, что в итоге привело к пониманию ИИ как эмуляции человеческих результатов на заданном списке задач-тестов. - tabula rasa: ум – это «чистый лист» неопределённого назначения, способный превращать произвольный опыт в знания и навыки для решения любой задачи. Эта точка зрения Алана Тьюринга и коннекционистов. В таком понимании интеллект представляется через метафору супер-ЭВМ, и его низкоуровневая механика дает возможности приобретать неограниченный набор навыков “с нуля”, “по данным”.
В настоящее время неверными признаны обе концепции. ¯\_(ツ)_/¯
Оценка ИИ: от оценки умений к оценке широких способностей
Тесты на заданных наборах данных стали главным драйвером прогресса в области ИИ, поскольку они воспроизводимы (тестовый набор фиксирован), справедливы (тестовый набор одинаков для всех), масштабируемы (многократное повторение теста не ведет к высоким расходам). Многие популярные тесты — DARPA Grand Challenge [3], Netflix Prize — внесли вклад в развитие новых алгоритмов ML-моделей.
При положительных результатах, даже добытых кратчайшим путем (с оверфиттингом и костылями), ожидаемый уровень качества постоянно поднимается. МакКордак назвала это «эффектом ИИ»: «Каждый раз, когда кто-то придумывал новый способ заставить компьютер делать нечто новое (играть в шашки) – обязательно появлялись критики, которые говорили: “Это не мышление”» [7]. Когда мы знаем, как именно машина делает что-то «умное», мы перестаем считать это умным.
«Эффект ИИ» появляется потому, что путаются процесс использования интеллекта (например, процесс обучения нейросети игре в шахматы) и артефакт, создаваемый таким процессом (получившаяся модель). Причина путаницы проста – в человеке эти две вещи неразделимы.
Для отхода от оценки лишь артефактов, а само способности к обучению и приобретению новых навыков вводят понятие “диапазона обобщения”, при котором система принимает градуальные значения.
- Отсутствие обобщения. Системы ИИ, в которых отсутствует неопределенность и новизна, не демонстрируют способности к обобщению, например: программа для игры в крестики-нолики, которая побеждает перебором вариантов.
- Локальное обобщение, или «надежность» — способность системы обрабатывать новые точки из известного распределения для одной задачи. Например, локальное обобщение выполнил классификатор изображений, который может отличить ранее не виденные им изображения с кошками от аналогичных по формату картинок с собаками после обучения на множестве подобных изображений кошек и собак.
- Широкое обобщение, или «гибкость» — способность системы обрабатывать широкую категорию задач и сред без дальнейшего вмешательства человека: готовность справляться с ситуациями, которые не могли быть предусмотрены создателями системы, с «неизвестными неопределенностями». Так, самоходное транспортное средство пятого уровня или домашний робот, способный пройти «кофейный тест» Возняка (зайти на случайную кухню и приготовить чашку кофе) [16], демонстрирует способность к высокой степени обобщения.
- Предельное обобщение. Открытые системы с возможностью решения совершенно новых задач, которые имеют лишь общие черты с ранее встречавшимися ситуациями, характерными для любой задачи и сферы в широком диапазоне — «адаптация к неизвестным неопределенностям в неизвестном диапазоне задач и областей». В настоящее время единственным примером такой системы являются биологические формы интеллекта (людей и, возможно, других разумных видов).
История ИИ — это история медленного развития, начиная с систем, не демонстрирующих способности к обобщению (символьный ИИ), и заканчивая надежными системами (машинное обучение), способными к локальному обобщению.
В настоящее время мы выходимся на новом этапе, в котором стремимся создавать гибкие системы — возрастает интерес к использованию широкого набора тестовых заданий для оценки систем, развивающих гибкость:
- эталонные критерии GLUE [13] и SuperGLUE [12] для обработки естественного языка
- среда обучения Arcade для агентов обучения с подкреплением [1],
- платформа для экспериментов и исследований ИИ «Проект Мальмё»,
- набор экспериментов Behavior Suite [8]
Помимо таких многозадачных тестов, недавно было предложено два комплекта тестов для оценки способности к обобщению, а не способности решать конкретные задачи:
- олимпиада Animal-AI Olympics [2] (animalaiolympics.com)
- и соревнование GVG-AI [9] (gvgai.net).
Оба теста основаны на предположении, что оценивать у агентов ИИ способности к обучению или планированию (а не специальные навыки) следует по решению неизвестного им ранее набора заданий или игр.

Новая концепция
Как сравнивать искусственный интеллект с человеческим, если уровень различных познавательных способностей у разных людей неодинаков?
Результаты тестов на интеллект у людей с разными способностями могут совпадать – это общеизвестный факт когнитивной психологии. Он показывает, что познание – это многомерный объект, структурированный иерархически по образу пирамиды с широкими и узкими навыками, наверху которой находится фактор общего интеллекта. Но действительно ли «сильный интеллект» – это вершина когнитивной пирамиды?
Теорема «бесплатных обедов не бывает» [14, 15] говорит нам о том, что любые два алгоритма оптимизации (включая человеческий интеллект) эквивалентны, когда их производительность усредняется для каждой возможной задачи. То есть для того, чтобы добиться производительности выше случайной, алгоритмы должны быть заточены под свою целевую задачу. Однако в данном контексте под «любой возможной задачей» подразумевается равномерное распределение по предметной области. Распределение задач, которые были бы актуальны именно для нашей Вселенной, не соответствовало бы такому определению. Таким образом, мы можем задать следующий вопрос: является ли фактор интеллекта человека универсальным?
В действительности люди пока собрали слишком мало информации о когнитивных способностях окружающих их агентов — других людей (в разных культурах “умность” оценивается по-разному) и животных, например, осьминогов или китов.
Судя по всему, человеческий интеллект далеко не универсален: он непригоден для большого ряда задач, под которые не адаптированы наши врожденные априорные знания.
Например, люди могут очень эффективно решать некоторые небольшие задачи полиномиальной сложности, если те мыслительно пересекаются с эволюционно знакомыми задачами вроде навигации. Так, задача коммивояжера с небольшим количеством точек может быть решена человеком почти оптимально за почти линейное оптимальное время [6], с использованием стратегии восприятия. Однако, если вместо «нахождения кратчайшего пути» попросить его найти самый длинный путь [5], то человек справится сильно хуже, чем один из простейших эвристических алгоритмов: алгоритм «дальнего соседа».
Авторы утверждают, что человеческое познание развивается по той же схеме, что и физические способности человека: и то, и другое развивалось в процессе эволюции для решения конкретных задач в конкретных средах (эти задачи известны как «четыре F» — четыре основных инстинкта: fighting, fleeing, feeding and fornicating: бей, беги, кормись и размножайся).
Основной посыл этой работы заключается в том, что «сильный интеллект» – это свойство системы, которое нельзя определить бинарно: «либо оно есть, либо нет». Нет, это диапазон, зависящий от:
- области применения, которая может быть более или менее широкой;
- степени эффективности, с которой система преобразует априорные знания и опыт в новые навыки в заданной области;
- степени сложности обобщения, представленной различными точками в рассматриваемой нами области.
«Ценность» одной сферы применения интеллекта по сравнению с другой является абсолютно субъективной — мы не были бы заинтересованы в системе, сфера применения которой не пересекалась бы с нашей. И даже не посчитали бы такую систему интеллектуальной.
Чего ожидать от идеального теста ИИ?
- Он должен описывать область своего применения и свою собственную способность прогнозировать ее объем, то есть он должен устанавливать достоверность.
- Он должен быть надежным (то есть воспроизводимым).
- Он должен ставить перед собой задачу измерения широких способностей и обобщения на уровне разработчика:
◦ В состав его оценочного набора не должно входить никаких задач, известных заранее – ни самой системе, проходящей тест, ни ее разработчикам
◦ Он должен как минимум четко показывать, что он стремится измерить – локальное обобщение (надежность), широкое обобщение (гибкость) или предельное обобщение (общий интеллект) - Он должен контролировать объем опыта, используемый системами во время обучения. «Купить» эффективность эталонного теста путем отбора неограниченных обучающих данных должно быть невозможно.
- Он должен предоставлять четкое и всестороннее описание набора используемых первоначальных знаний.
- Он должен беспристрастно работать как для людей, так и для машин, используя такие же знания, какие используют люди.
Первая попытка сделать такой тест описана далее.
Предлагаемый тест: массив данных ARC
ARC можно рассматривать как эталонный тест сильного искусственного интеллекта, как эталонный тест программного синтеза или как психометрический тест интеллекта. Он нацелен как на людей, так и на системы искусственного интеллекта, предназначенные для имитации сильного подвижного интеллекта, сходного с интеллектом человека. По формату он чем-то напоминает прогрессивные матрицы Равена [4], классический тест на IQ, восходящий к 1930-м годам.
В состав ARC входят два набора данных: обучающий и оценочный. В обучающем наборе 400, а в оценочном — 600 задач.
При этом оценочный набор также делится на два: открытый (400 задач) и закрытый (200 задач). Все предложенные задачи уникальны, и набор оценочных задач не пересекается с набором обучающих.
Каждая задача состоит из небольшого количества демонстрационных и тестовых примеров. Демонстрационных в среднем 3,3 на задачу, тестовых – от одного до трех, чаще всего один. Каждый пример, в свою очередь, состоит из input grid и output grid.
Такая «сетка» – это матрица из определенных символов (каждый из которых, как правило, выделяется определенным цветом):
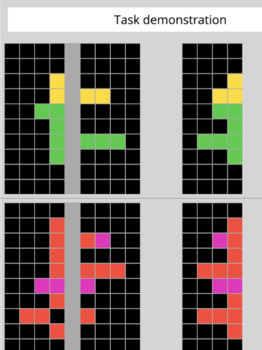
Всего уникальных символов (или цветов) — 10. «Сетка» может быть любой высоты или ширины – от 1×1 до 30×30 включительно (средняя высота — 9, средняя ширина — 10).
При решении оценочной задачи участник тестирования получает доступ к обучающим примерам (как к «входной», так и к «выходной сетке»), а также к начальным условиям для выполнения тестового задания – «входной сетке» соответствующих тестовых (оценочных) примеров. Далее участник тестирования должен построить собственную «выходную сетку» для «входной сетки» каждого тестового примера.
Построение «выходной сетки» осуществляется исключительно с нуля, то есть участник тестирования должен сам решить, какова должна быть высота и ширина этой «сетки», какие символы следует в нее поместить и куда. Считается, что задача решена успешно, если участник тестирования может дать точный и правильный ответ по всем входящим в нее тестовым примерам (двухчастный показатель успеха).
Наличие закрытого оценочного набора позволяет нам строго следить за чистотой оценки в условиях открытого конкурса. Примеры заданий ARC:
Задача, неявная цель которой заключается в том, чтобы закончить симметричную схему. Характер этой задачи определяется тремя входными/выходными примерами. Участник тестирования должен составить выходную сетку, соответствующую входной (см. внизу справа).
Задача по устранению «шумов».
Красный объект «перемещается» по направлению к голубому, пока не входит с ним в «контакт».
Задача, неявная цель которой заключается в том, чтобы продолжить (экстраполировать) диагональную линию, которая «отскакивает» при контакте с красным препятствием.
Задача, где необходимо выполнить разом целый ряд действий: «продолжить линию», «обойти препятствия» и «эффективно достичь конечной цели» (в реальной задаче приводится больше демонстрационных пар).
ARC не предоставляется как идеальный и законченный тест, тем не менее, он обладает важными свойствами:
- каждая тестовая задача новая и опирается на четкий набор первоначальных знаний, общих для всех участников тестирования.
- он может быть полностью решен людьми, но его нельзя выполнить при помощи каких-либо существующих на данный момент приемов машинного обучения (включая глубинное обучение).
- тест может представлять собой весьма занятную «игровую площадку» для исследователей ИИ, интересующихся разработкой алгоритмов, способных к широкому обобщению, которое действует подобно человеческому. Кроме того, ARC дает нам возможность сравнить человеческий и машинный интеллект, так как мы предоставляем им одинаковые первоначальные знания.
Автор планирует и дальше совершенствовать ARC — и как площадку для исследований, и как совместный эталонный тест для машинного и человеческого интеллекта.
Как вы думаете — может, основная идея будет более успешна, если удастся отвлечь внимание сообщества сильнго ИИ от попыток превзойти людей в конкретных задачах?
Источник



