
- Инкрементальные бэкапы postgresql с pgbackrest — курс молодого бойца от разработчика
- Подготовка
- Установка pgbackrest
- Настройка взаимодействия между серверами через passwordless SSH
- Настройка postgres сервера
- Настройка сервера-репозитория
- Создание хранилища
- Проверка
- Делаем бэкап
- Восстанавливаем бэкап
- Дифференциальные и инкрементальные бэкапы MySQL
- Как это работает
- Дифференциальные и инкрементальные бэкапы
- Установка XtraBackup и настройка расписания
- 1. Установка:
- 2. Проверим, что установка прошла успешно:
- 3. Создадим минимальную версию скрипта, который можно будет вызывать по расписанию в cron:
- 4. Добавим расписание в /etc/crontab:
- Восстановление
- 1. Разархивирование
- 2. Подготовка:
- 3. Применение резервной копии:
- Заключение
Инкрементальные бэкапы postgresql с pgbackrest — курс молодого бойца от разработчика
Я — разработчик. Я пишу код, с базой данных взаимодействую лишь как пользователь. Я ни в коем случае не претендую на должность системного администратора и, тем более, dba. Но…
Так вышло, что мне нужно было организовать резервное копирование postgresql базы данных. Никаких облаков — держи SSH и сделай, чтобы все работало и не просило денег. Что мы делаем в таких случаях? Правильно, пихаем pgdump в cron, каждый день бэкапим все в архив и если совсем разошлись — отправляем этот архив куда-нибудь подальше.
В этот раз сложность состояла в том, что по планам база должна была расти примерно на +- 100 МБ в день. Разумеется, уже через пару недель желание бэкапить все pgdump’ом отпадет. Тут на помощь приходят инкрементальные бэкапы.
Интересно? Добро пожаловать под кат.
Инкрементальный бэкап — разновидность резервной копии, когда копируются не все файлы источника, а только новые и измененные с момента создания предыдущей копии.
Как и любой разработчик, СОВЕРШЕННО не желающий (на тот момент) разбираться в тонкостях postgres я хотел найти зеленую кнопку. Ну, знаете, как в AWS, DigitalOcean: нажал одну кнопку — получил репликацию, нажал вторую — настроил бэкапы, третью — все откатил на пару часов назад. Кнопки и красивого GUIшного инструмента я не нашел. Если вы знаете такой (бесплатный или дешевый) — напишите об этом в комментариях.
Погуглив я нашел два инструмента pgbarman и pgbackrest. С первым у меня просто не задалось (очень скудная документация, пытался все поднять по старинным мануалам), а вот у второго документация оказалась на уровне, но и не без изъяна. Чтобы упростить работу тем, кто столкнется с подобной задачей и была написана данная статья.
Дочитав данную статью вы научитесь делать инкрементальные бекапы, сохранять их на удаленный сервер (репозиторий с бэкапами) и восстанавливать их в случае утери данных или иных проблем на основном сервере.
Подготовка
Для воспроизведения мануала вам понадобятся два VPS. Первый будет хранилищем (репозиторием, на котором будут лежат бэкапы), а второй, собственно, сам сервер с postgres (в моем случае 11 версия postgres).
Подразумевается, что на сервере с postgres у вас есть root, sudo пользователь, пользователь postgres и сам postgres установлен (пользователь postgres создается автоматически при установке postgresql), а на сервере-репозитории есть root и sudo пользователь (в мануале будет использоваться имя пользователя pgbackrest).
Чтобы у вас было меньше проблем при воспроизведении инструкции — курсивом я прописываю где, каким пользователем и с какими правами я исполнял команду во время написания и проверки статьи.
Установка pgbackrest
Репозиторий (пользователь pgbackrest):
1. Скачиваем архив с pgbackrest и переносим его содержимое в папку /build:
2. Устанавливаем необходимые для сборки зависимости:
3. Собираем pgbackrest:
4. Копируем исполняемый файл в директорию /usr/bin:
5. Pgbackrest требует наличие perl. Устанавливаем:
6. Создаем директории для логов, даем им определенные права:
Postgres сервер (sudo пользователь или root):
Процесс установки pgbackrest на сервере с postgres аналогичен процессу установки на репозитории (да, pgbackrest должен стоять на обоих серверах), но в 6-ом пункте вторую и последнюю команды:
Настройка взаимодействия между серверами через passwordless SSH
Для того, чтобы pgbackrest корректно работал, необходимо настроить взаимодействие между postgres сервером и репозиторием по файлу-ключу.
Репозиторий (пользователь pgbackrest):
Создаем пару ключей:
Внимание! Указанные выше команды выполняем без sudo.
Postgres сервер (sudo пользователь или root):
Создаем пару ключей:
Репозиторий (sudo пользователь):
Копируем публичный ключ postgres сервера на сервер-репозиторий:
На данном шаге попросит пароль от root пользователя. Вводить нужно именно пароль root пользователя postgres сервера!
Postgres сервер (sudo пользователь):
Копируем публичный ключ репозитория на сервер с postgres:
На данном шаге попросит пароль от root пользователя. Вводить нужно именно пароль root пользователя репозитория!
Репозиторий (root пользователь, для чистоты эксперимента):
Postgres сервер (root пользователь, для чистоты эксперимента):
Убеждаемся, что без проблем получаем доступ.
Настройка postgres сервера
Postgres сервер (sudo пользователь или root):
1. Разрешим «стучаться» на postgres сервер с внешних ip. Для этого отредактируем файл postgresql.conf (находится в папке /etc/postgresql/11/main), добавив в него строчку:
Если такая строка уже есть — либо раскомментируйте ее, либо установите значение параметра как ‘*’.
В файле pg_hba.conf (так же находится в папке /etc/postgresql/11/main) добавляем следующие строчки:
2. Внесем необходимые настройки в postgresql.conf (он находится в папке /etc/postgresql/11/main) для работы pgbackrest:
3. Внесем необходимые настройки в файл конфигурации pgbackrest (/etc/pgbackrest/pgbackrest.conf):
4. Перезагрузим postgresql:
Настройка сервера-репозитория
Репозиторий (pgbackrest пользователь):
Внесем необходимые настройки в файл конфигурации pgbackrest
(/etc/pgbackrest/pgbackrest.conf):
Создание хранилища
Репозиторий (pgbackrest пользователь):
Создаем новое хранилище для кластера main:
Проверка
Postgres сервер (sudo пользователь или root):
Проверяем на postgres сервере:
Репозиторий (pgbackrest пользователь):
Проверяем на сервере-репозитории:
Убеждаемся, что в выводе видим строку «check command end: completed successfully».
Устали? Переходим к самому интересному.
Делаем бэкап
Репозиторий (pgbackrest пользователь):
1. Выполняем резервное копирование:
2. Убеждаемся, что бэкап был создан:
Pgbackrest создаст первый полный бэкап. При желании вы можете запустить команду бэкапа повторно и убедиться, что система создаст инкрементальный бэкап.
Если вы хотите повторно сделать полный бэкап, то укажите дополнительный флаг:
Если вы хотите подробный вывод в консоль, то также укажите:
Восстанавливаем бэкап
Postgres сервер (sudo пользователь или root):
1. Останавливаем работающий кластер:
2. Восстанавливаемся из бэкапа:
Чтобы восстановить базу в состояние последнего ПОЛНОГО бэкапа используйте команду без указания recovery_target:
Важно! После восстановления может оказаться так, что база зависнет в режиме восстановления (будут ошибки в духе ERROR: cannot execute DROP DATABASE in a read-only transaction). Честно говоря, я еще не понял, с чем это связано. Решается следующим образом (нужно будет малость подождать после исполнения команды):
На самом деле, есть возможность восстановить конкретный бэкап по его имени. Здесь я лишь укажу ссылку на описание данной фичи в документации. Разработчики советуют использовать данный параметр с осторожностью и объясняют почему. От себя могу добавить, что я его использовал. Если очень нужно — убедитесь, что после восстановления база вышла из recovery mode (select pg_is_in_recovery() должен показать «f») и на всякий случай сделайте полный бэкап после восстановления.
3. Запускаем кластер:
После восстановления бэкапа нам необходимо выполнить повторный бэкап:
Репозиторий (pgbackrest пользователь):
На этом все. В заключение хочу напомнить, что я ни в коем случае не пытаюсь строить из себя senior dba и при малейшей возможности буду использовать облака. В настоящее время сам начинаю изучать различные темы вроде резервного копирования, репликаций, мониторинга и т.п. и о результатах пишу небольшие отчеты, дабы сделать небольшой вклад в сообщество и оставить для себя небольшие шпаргалки.
В следующих статьях постараюсь рассказать о дополнительных фичах — восстановление данных на чистый кластер, шифрование бэкапов и публикацию на S3, бэкапы через rsync.
Источник
Дифференциальные и инкрементальные бэкапы MySQL

Для MySQL существует широко известный инструмент по созданию резервных копий баз данных — mysqldump, который создаёт дамп посредством записи серии SQL-инструкций для восстановления таблиц и данных целевой базы данных.
Он неплохо подходит для резервного копирования небольших баз данных, но когда база данных набирает приличный «вес» и возникает необходимость резервного копирования чаще, чем раз в сутки, скорость создания и размеры дампов могут стать проблемой. В данном случае на помощь приходят утилиты, создающие копию бинарных файлов баз данных, например, такие как Percona XtraBackup.
Percona XtraBackup поддерживает «горячее» резервное копирование для серверов MySQL, Percona, MariaDB и Drizzle (бета) всех версий.
Среди преимуществ такого подхода можно выделить следующие:
- Высокая скорость создания резервных копий — так как при резервном копировании используется прямое копирование файлов — скорость создания таких копий будет ограничена скоростью дисковой подсистемы.
- Отсутствие блокировок для подсистем хранения InnoDB, XtraDB, и HailDB.
- Автоматическая проверка целостности.
- Инкрементальные бэкапы.
- Компрессия «на лету» — что позволяет делать резервное копирование по сети быстрее.
Как это работает
XtraBackup начинает копировать файлы баз данных, запоминая номер транзакции на момент начала (LSN), так как копирование файлов занимает какое-то время, данные в них могут измениться, поэтому параллельно XtraBackup запускает процесс, который отслеживает файлы с логами транзакций и копирует все изменения прошедшие с начала копирования.
После того как файлы скопированы, для получения работоспособной копии XtraBackup должен выполнить этап восстановления (crash recovery), используя сохранённый лог транзакций, на данном этапе к файлам баз данных будут применены завершённые транзакции из файла лога транзакций. Транзакции, которые изменили данные, но не были завершены, будут отменены.
После этого этапа файлы баз данных можно использовать для восстановления сервера путём его остановки и копирования файлов в их первоначальное расположение — вручную или используя XtraBackup (обычно это /var/lib/mysql, если сервер MySQL настроен по умолчанию).
Дифференциальные и инкрементальные бэкапы
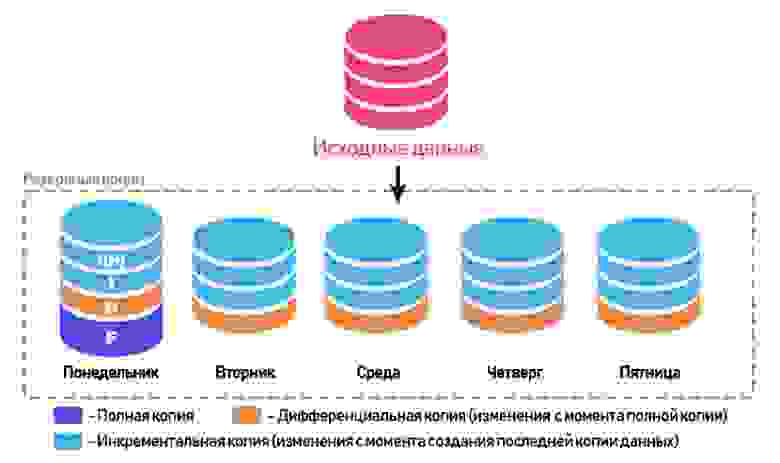
Часто бывает так, что потеря данных даже за короткий промежуток времени весьма чувствительна, и возникает необходимость делать резервное копирование как можно чаще.
Создание полных бэкапов больших баз данных чаще, чем раз в день, может быть затруднительным — как правило, из-за размера дампов, тут как раз возможность копирования только выполненных изменений будет как нельзя кстати.
В зависимости от стратегии копирования могут использоваться дифференциальные и инкрементальные бэкапы, дополнительно к полным. Дифференциальный бэкап содержит изменения в данных относительно полного бэкапа, инкрементальный — содержит изменения со времени последнего частичного бэкапа – последней инкрементальной копии.
В зависимости от размера баз данных и необходимой частоты резервного копирования стратегии могут заметно отличаться, я же рассмотрю вариант с «недельным» планом, когда в конце недели создаётся полный бэкап, в начале каждого рабочего дня создаётся дифференциальный бэкап, и каждый час в течение рабочего времени — создание инкрементального бэкапа.
Такой план в самом плохом сценарии позволит сохранить данные, не потеряв более одного часа, или восстановить состояние баз на начало любого рабочего часа. А наличие дифференциального бэкапа позволит сократить количество необходимых копий, используемых при восстановлении.
Установка XtraBackup и настройка расписания
Дальнейшие действия выполнялись на CentOS 8, скачать подходящую версию XtraBackup можно с официального сайта.
Для создания полной резервной копии нужно запустить xtrabackup с опцией — backup . Дополнительно можно использовать опцию —target-dir, которая указывает на директорию, где будет создан бэкап, если директория для создания бэкапа не существует, Xtrabackup создаст её.
По умолчанию XtraBackup ищет данные конфигурации сервера и данные подключения пользователя из файлов:
/.my.cnf
Если есть необходимость переопределить настройки сервера и клиента, можно создать отдельный .cnf файл и указать его с опцией —defaults-file, я не буду использовать эту опцию, так как логин и пароль пользователя для подключения клиента MySQL у меня заданы в /root/.my.cnf:
1. Установка:
Скачаем и установим XtraBackup из RPM:
Если планируется использовать компрессию, потребуется установить Qpress:
2. Проверим, что установка прошла успешно:
3. Создадим минимальную версию скрипта, который можно будет вызывать по расписанию в cron:
4. Добавим расписание в /etc/crontab:
Теперь резервное копирование будет выполняться по заданному расписанию в каталог /data/backups/db (как было задано в скрипте), но нужно учесть, что копирование не начнется, пока не будет создан полный и дифференциальный бэкап (в понедельник), поэтому, чтобы проверить работу скрипта, мы создадим их вручную:
Восстановление
Для восстановления состояния баз на требуемое время, нам нужно будет выполнить последовательно этапы:
- Разархивировать требуемые бэкапы, если использовалось компрессирование
- Подготовить полный бэкап и применить требуемые бэкапы (полный, дифференциальный и все последующие инкрементальные до нужного момента времени)
- Остановить сервер mysql, при необходимости сделать копию текущих файлов сервера
- Скопировать файлы из подготовленной копии на место оригинальных файлов
1. Разархивирование
В этапе подготовки, в случае когда к полному бэкапу будут применены последующие инкрементальные бэкапы, необходимо указать опцию —apply-log-only , чтобы не отменять незавершённые транзакции.
2. Подготовка:
Теперь, когда в каталоге /data/backups/db/20210913-FULL/ у нас готовые к использованию файлы баз данных, осталось остановить сервер, удалить или перенести старые файлы и скопировать новые файлы в оригинальное расположение и восстановить владельца файлов (mysql).
3. Применение резервной копии:
Заключение
Как известно, администраторы делятся на тех, кто не делает бэкап, и тех, кто уже делает. Последних же можно ещё поделить на тех, кто не проверяет целостность резервных копий, и тех, кто уже проверяет.
Этап с проверкой целостности выходит за пределы данной статьи, что не отменяет его важности, также стоит упомянуть, что статья не описывает всех нюансов использования Xtrabackup, но может послужить отправной точкой для администраторов, решивших делать бэкап чаще, чем раз в сутки.
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS
— 20% на выделенные серверы AMD Ryzen и Intel Core — HABRFIRSTDEDIC .
Доступно до 31 декабря 2021 г.
Источник



