
- Иерархический способ организации данных это
- 3.1.2. Операции над данными, определенные в иерархической модели:
- 3.1.3. Ограничения целостности.
- Иерархическая база данных — это. Модели, примеры
- Виды баз данных
- Принцип построения иерархической модели
- Применение иерархической структуры данных
- Основные операции над БД, построенными на иерархической модели
- Обобщенное описание структуры
- Наполнение БД
- Достоинства
- Недостатки
- Примеры
- Применение в ЭВМ
- Сетевые базы данных
- Иерархия и реляционность
- IT-блог о веб-технологиях, серверах, протоколах, базах данных, СУБД, SQL, компьютерных сетях, языках программирования и создание сайтов.
- Иерархическая база данных. Иерархическая модель данных
- Иерархическая модель данных
- Структура иерархической базы данных
- Преобразование концептуальной модели в иерархическую модель данных
- Управление иерархическими данными
Иерархический способ организации данных это
При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей — вершинами (диаграмма Бахмана).
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство . Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись (подробнее о режимах включения и исключения записей сказано в параграфе о сетевой модели). При удалении родительской записи автоматически удаляются все подчиненные.
Рассмотрим следующую модель данных предприятия (см. рис. 3.1 ): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. (а) (Для простоты полагается, что имеются только две дочерние записи).
Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры : заказчик — контракты с ним — сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК(НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (рис. (b) ) . Рис. 3.1
Из этого примера видны недостатки иерархических БД:
- Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями.
- Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N , то есть одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N ). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ — дочерней (рис. (c) ). Таким образом, мы опять вынуждены дублировать информацию.
3.1.2. Операции над данными, определенные в иерархической модели:
- ДОБАВИТЬ в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
- ИЗМЕНИТЬ значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
- УДАЛИТЬ некоторую запись и все подчиненные ей записи.
- ИЗВЛЕЧЬ :
- извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей
- извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева)
В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 1 тысячи руб.)
Как видим, все операции изменения применяются только к одной «текущей» записи (которая предварительно извлечена из базы данных). Такой подход к манипулированию данных получил название «навигационного».
3.1.3. Ограничения целостности.
Поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Как уже отмечалось, не обеспечивается автоматическое поддержание соответствия парных записей, входящих в разлные иерархии.
Бойко В.В., Савинков В.М. Проектирование баз данных информационных систем. -М.:»Финансы и статистика»,1989.
Источник
Иерархическая база данных — это. Модели, примеры
Иерархическая база данных — это БД, основанная на древовидной структуре. По принципу построения она чем-то схожа с файловой системой компьютера. У использования такой модели есть свои достоинства и недостатки, которые будут рассмотрены в этой статье, вместе с подробными примерами.
Виды баз данных
Как известно, различают четыре вида посторения БД:
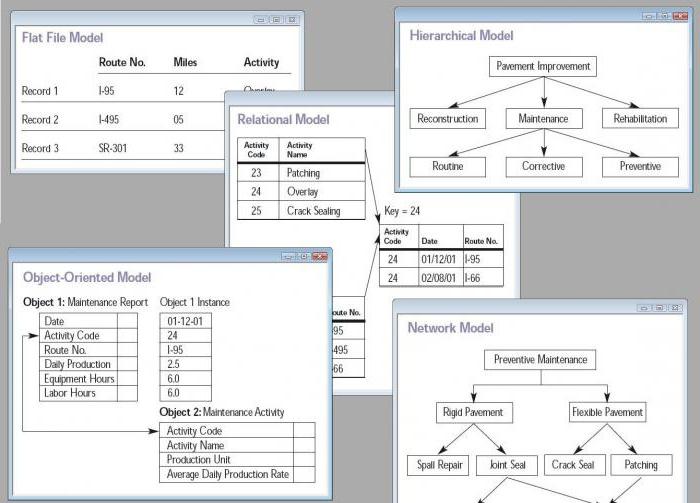
- Реляционные — табличные СУБД, где информация представлена в виде строк-столбцов. По этому принципу строятся базы данных в «Аксесе», к примеру.
- Объектно-ориентированные — тесно связаны с ООП (программированием, в котором идет работа с объектами), и это их главный плюс, но, учитывая их небольшую производительность, они пока значительно уступают в распространенности реляционным.
- Гибридные — СУБД, вмещающие в себе сразу два указанных выше вида.
- Иерархические — объект внимания данной статьи. Это БД, характеризирующиеся древообразной структурой.
Наиболее известным примером иерархической базы данных является продукт, созданный компанией IBM («АйБиЭм»), под названием Information Management System (переводится как «Информационная система управления»), сокращенно IMS. Первая версия IMS вышла еще в прошлом, двадцатом веке, в шестьдесят восьмом году. Она используется для хранения и контроля данных и поныне.
Принцип построения иерархической модели
Иерархическая модель данных строится по следующему принципу:
- для каждого узла древовидной структуры ставится в соответствие некий сегмент;
- под сегментом понимаются поля данных с присвоенным каждому полю именем и выстроенные в один линейный кортеж;
- еще одно соответствие: один входной и несколько выходных сегментов для каждого исходного поля;
- для каждого структурного элемента существует одно и только одно место в системе иерархии;
- древовидная структура начинается с корневого элемента;
- у каждого подчиненного узла только один предок, но у каждого исходного может быть несколько потомков.
Применение иерархической структуры данных
Иерархическая база данных — это хранилище, применимое для тех систем, которым изначально свойственна древовидная структура. Для них выбирать подобное моделирование — логично.
Пример иерархической базы данных с изначально систематизированными степенями — воинское подразделение, в котором, как известно, четко определены ранги. Также это могут быть сложные механизмы, состоящие из все более упрощающихся к низу иерархии частичек. Для моделирования таких систем и приведения их к виду рассматриваемой БД нет необходимости в декомпозиции. Тем не менее такая ситуация складывается не всегда.
Кроме того, существует тенденция, при которой направленный вниз по структуре запрос проще, чем аналогичный вверх.
Основные операции над БД, построенными на иерархической модели
Структура иерархической базы данных позволяет успешно и практически беспроблемно (в зависимости от навыков и умений) совершать следующие операции (представлены самые основные, список всегда можно расширить мелкими дополнениями):
- поиск по базе данных того или иного элемента;
- переход по базе данных — от дерева к дереву;
- переход по дереву — от ветви к ветви;
- соответственно, переход по ветвям — поэлементно;
- работа с записями: вставка новой и/или удаление текущей, копирование, вырезание и т. д.
Обобщенное описание структуры
Термин «древовидная» для описания структуры упоминается в этой статье уже далеко не единожды. Пора рассказать, откуда он произошел. Все потому что иерархическая база данных — это такая БД, которая использует тип данных «дерево». Рассмотрим подробнее, что он из себя представляет.
Это составной тип: в каждый из элементов (узлов) вкладывается несколько последующих (один или более). А начинается все с одного корневого элемента. Суть в том, что каждый из кусочков типа «дерево», является подтипом, тоже «деревом». Много-много разветвленных, и все также упорядоченных структур.
Элементарные типы могут быть простыми и составными, но по существу это всегда записи. Но в простом записи присутствует один тип данных, а в составном — целая их совокупность.
Иерархической модели свойственен принцип потомков, когда каждый предыдущий сегмент является предком для последующего. Кроме того, потомок по отношению к вышестоящему типу является типом подчиненным, в то время как равнозначные один другому записи считаются близнецами.
Наполнение БД
Основными данными иерархической БД являются значения (числа или символы), которые хранятся в записях. Обходят такую базу данных обычно снизу вверх и слева направо.
Достоинства
Иерархическая база данных — это имеющая корневую папку БД, постепенно разветвляющаяся книзу. Учитывая, что подобная структура весьма схожа с файловой системой, такие базы успешно применяются для выполнения различных операций над данными ЭВМ. Итог: рациональное распределение ее памяти, а также весьма достойные показатели времени, затраченного на работу.
Иерархическая модель идеальна для применения ее для упорядоченной информации.
Недостатки
Однако те же особенности рассматриваемых СУБД, которые стали их основными достоинствами, определяют также и их недостатки. К примеру, громоздкость и сложность логических связей — опытному специалисту при работе с ранее неизвестной базой будет трудно разобраться, а простой пользователь и вовсе в ней «заблудится». Эта сложность понимания приводит к тому, что на самом деле не так много СУБД построены на иерархической модели. Примером иерархической базы данных является, кроме уже описанного продукта компании «АйБиЭм», «Ока» и МИРИС (производство России), а также Data Edge и Team-UP (от зарубежных корпораций).
Примеры
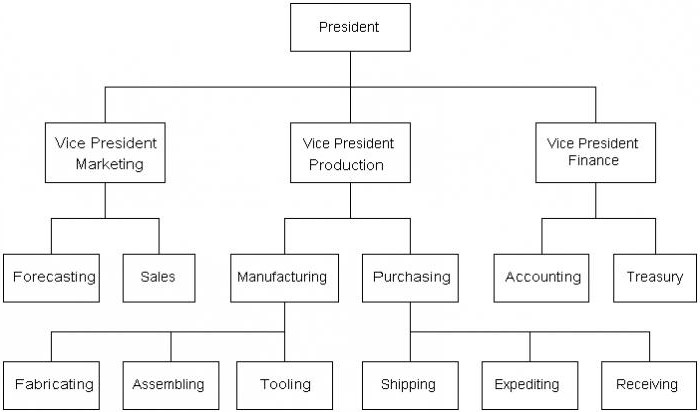
Иерархическая база данных — это многообразие различных уровней, на которых строятся взаимосвязи. Схематично она выглядит как перевернутый граф. Пример иерархической базы данных — любое государственное административное учреждение. Взять, допустим, школу.

На самом верхней уровне будет располагаться «лидер» администрации — директор. В его подчинении завучи, у завучей — преподаватели, который руководят параллелями классов. В каждой параллели энное их количество, а в каждом классе есть некоторое число учеников.
По такому же принципу можно расписать и управление какой-нибудь корпорацией. Глава компании или даже совет директоров на самом верху. Далее — все большее количество подразделений, в каждом из которых действует своя структура. Есть и общие черты: начальник в каждом отделе, его помощник, его секретарь, собственно, офисные сотрудники и так далее.
Применение в ЭВМ
Могут быть и более серьезные области применения. Яркий пример иерархической базы данных- это файловая система. Всем привычный «Проводник» строится в самом ядре операционной системы «Виндоус» именно по такой схеме, так же, как и многие другие файловые менеджеры.
Сетевые базы данных
- реляционные;
- иерархические;
- сетевые базы данных.
Почему мы вновь вспомнили о классификации? Поскольку, в отличие от реляционной, сетевая БД имеет с иерархической схожие черты.
Время вспомнить виды связей в базах данных. Есть связи «один-к-одному», «один-ко-многим» и «многие-ко-многим». Нас интересует последняя. В сетевой БД она проявляется следующим образом: у одного узла-наследника может быть сразу несколько предков. Свойство иметь несколько потомков также сохраняется. Можно сказать, что иерархические базы данных, сетевые базы данных сами по себе уже пример такого наследования. Предком в данном случае является именно иерархическая БД, так как принцип построения структуры в сетевых БД остается прежним.
Иерархия и реляционность
Название «реляционная» произошло от английского слова «отношение». Как уже упоминалось в начале статьи, они часто выражаются таблично. Но в предыдущем пункте мы указали, что иерархическая БД также может организовывать связи, значит ли это, что и между этими двумя типами есть некая объединяющая их тонкая ниточка?

Да. Помимо того, что и первый, и второй вид все еще относятся к базам данных, кроме этого признака есть еще одно общее свойство. Например, иерархическую БД (и сетевую заодно с ней) можно выразить в таблице. Суть здесь не в том, в каком виде представить информацию конечному пользователю (это уже вопрос юзабилити интерфейса), но по какому принципу была структурирована информация. Так, четкое деление на отделы со своими начальниками, подразделениями и прочим по-прежнему будет выражено в иерархии, но для удобства занесено в таблицу.
Источник
IT-блог о веб-технологиях, серверах, протоколах, базах данных, СУБД, SQL, компьютерных сетях, языках программирования и создание сайтов.
Иерархическая база данных. Иерархическая модель данных
Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Продолжаем рубрику Заметки о MySQL, в которой уже были публикации: Нормальные формы и транзитивная зависимость, избыточность данных в базе данных, типы и виды баз данных, настройка MySQL сервера и файл my.ini, MySQL сервер, установка и настройка, Архитектура СУБД и архитектура баз данных, Сетевая база данных, сетевая модель данных. Я продолжаю рассматривать различные модели данных, и сегодня мы поговорим про иерархическую модель данных или иначе – иерархическую базу данных.
Стоит сказать, что иерархическая база данных является частным случаем сетевой модели данных, о которой мы говорили в предыдущей публикации. Но дело все в том, что и иерархическая модель данных, и сетевые базы данных являются мало эффективными, и постепенно от их использования отказываются. Иерархические и сетевые СУБД остались только в некоторых крупных фирмах, которые наполняли такие базы годами. И сейчас основной проблемой для таких фирм является проблема совместимости иерархических и сетевых баз данных с реляционными базами данных. Ну а сегодня мы просто поговорим про иерархическую базу данных.
Иерархическая модель данных
Иерархическая модель данных является частным случаем сетевой модели данных, структура иерархической базы данных немного проще сетевой и, соответственно, иерархические базы данных даже менее эффективны, чем сетевые. Иерархическая модель данных, как и сетевые БД опирается на теорию графов.
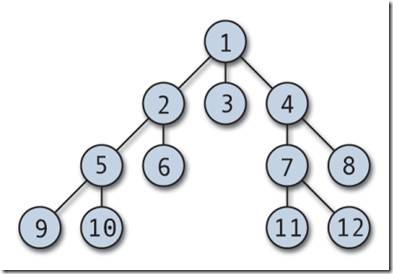
Иерархическая база данных. Иерархическая модель данных.
В основе иерархической модели данных лежит один главный элемент (главный узел), с которого все и начинается, такой элемент называет корневым элементом, в теории графов это называется корнем дерева. Вообще, по сути, что сетевая база данных, что иерархическая база данных имеет древовидную структуру. Все элементы или узлы, которые находятся ниже корневого узла иерархической модели, являются потомками корня. Стоит сказать, что и иерархическая база данных, и сетевая база данных оптимизированы на чтение информации из БД, но не на запись информации в базу данных, эта особенность обусловлена самой моделью данных.
Узлы дерева, которые находятся на одном уровне, обычно называются братьями. Узлы, которые находятся ниже какого-то определенного уровня, являются дочерними узлами по отношению к нему. Иерархическую модель данных можно сравнить с файловой системой компьютера. Компьютер умеет очень быстро работать с отдельными файлами: удалять конкретный файл, редактировать файл, копировать или перемещать файл. Но операция проверки компьютера антивирусом может происходить достаточно длительное время.
Точно такие же особенности присуще иерархической СУБД, то есть базы данных, имеющие иерархическую структуру, умеют очень быстро находить и выбирать информацию и отдавать ее пользователю. Но структура иерархической модели данных не позволяет столь же быстро перебирать информацию. Ну, это видно из рисунка, представленного выше. Допустим, что нам необходимо найти все записи, содержащие слово «сотрудник». Как будет поступать иерархическая СУБД в этом случае? А поступать она будет следующим образом: свой поиск она начнет с корневого элемента иерархической модели данных, проверив его, она начнет проверять его связи, если связей будет несколько, то она пойдет проверять в крайний левый дочерний элемент, расположенный на уровень ниже.
Затем иерархическая СУБД проверит содержимое этого элемента и его связи, если связей опять будет несколько, то она отправится опять-таки в крайний левый дочерний элемент, чтобы проверить его содержимое, проверив его содержимое она увидит, что у этого узла нет дочерних элементов и вернется в родительский узел этого узла, чтобы проверить, есть ли у него еще дочерние элементы. И так постепенно, узел за узлом, спуская и поднимаясь по иерархии узлов СУБД переберет все узлы и выдаст нам все записи, в которых есть слово «сотрудник». Ну, думаю, что с иерархической моделью данных мы более-менее разобрались (если не разобрались, то пишите в комментарии), можно приступить к рассмотрению структуры иерархической базы данных.
Структура иерархической базы данных
Самые первые в мире СУБД использовали иерархическую модель данных, иерархические базы данных появились даже раньше, чем сетевая модель хранения данных. Поэтому структура иерархической базы данных немного проще, чем структура сетевой БД. И так, основными информационными единицами иерархической модели данных являются сегмент и поле. Поле данных является наименьшей неделимой информационной единицей иерархической базы данных, доступной пользователю. У сегмента данных можно определить его тип и экземпляр сегмента.
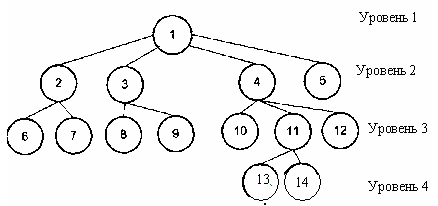
Иерархическая база данных. Иерархическая модель данных.
Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента – это именованная совокупность всех типов полей данных, входящих в данный сегмент. Если ориентироваться по рисунку выше, то тип сегмента – это родительский элемент и все его дочерние элементы. Как я уже говорил: иерархическая модель данных базируется на теории графов, но если структура сетевой БД описывается ориентированным графом (графом со стрелочками), то структура иерархической базы данных описывается неориентированным графом. Характерной особенностью структуры иерархической модели данных является то, что у любого потомка или дочернего элемента может быть только один предок или родительский элемент.
Каждый узел иерархического дерева или каждый элемент иерархической базы данных является сегментом данных. Линии, соединяющие сегменты – это связи между информационными объектами иерархической базы данных. Рисунок должен внести дополнительную ясность:
На концептуальном уровне иерархическая база данных является частным случаем сетевой модели данных.
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую модель данных происходит аналогично преобразованию в сетевую модель данных, но существую некоторые тонкости, о которых мы и поговорим. Эти тонкости связаны с тем, что структура иерархической базы данных должна быть представлена в виде дерева, то есть данные иерархической модели должны быть организованы в виде дерева.
Как вы помните: дуги, соединяющие узлы между собой, – это связи. Связи бывают один к одному и один ко многим. Преобразование связей один ко многим происходит автоматически в том случае, если потомок иерархического дерева имеет только одного предка. Происходит это следующим образом: Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа «один ко многим». Сегмент со стороны «много» становится потомком, а сегмент со стороны «один» становится предком. Согласитесь, что преобразование в иерархическую модель данных похоже на преобразование в сетевую модель.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Управление иерархическими данными
У иерархической модели данных существует два средства управления данными: языковые средства описания данных (ЯОД) и языковые средства манипулирования данными (ЯМД). Физическая структура иерархической базы данных описывает: логическую структуру иерархической модели данных и саму структуру хранения базы данных.
При этом способ доступа устанавливает способ организации взаимосвязи физических записей. Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо того, что обязательно должно быть задано имя иерархической базы данных и способа доступа к каждому элементу иерархической модели данных, описание иерархической БД должно содержать определение типов каждого сегмента данных, входящих в базу данных, в соответствие с выстроенной иерархией. Описание типов сегмента следует начинать с корня иерархической модели. Особенностью иерархических баз данных является то, что каждая физическая база данных может содержать только один корень, но в одной иерархической системе может находиться несколько физических баз данных.
Среди операторов манипулирования данными для иерархической базы данных можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической модели данных не так уж обширен, но этого набора вполне достаточно для управления и поддержания иерархических баз данных. Примеры типичных операторов поиска данных:
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
Источник



