
Группировка как способ анализа. Виды группировок
Группировкапредставляет собой процесс образования однородных групп па основе расчленения статистической совокупности на части или объединения изучаемых единиц в частные совокупности по существенным для них признакам, каждая из которых характеризуется системой статистических показателей. Особый вид группировок — классификация, представляющая собой устойчивую номенклатуру классов и групп, образованных на основе сходства и различия единиц изучаемого объекта. Метод группировок позволяет разрабатывать первичный аналитический материал. На базе группировки рассчитываются сводные показатели по группам, появляется возможность их сравнения, анализа причин различий между группами, изучения взаимосвязей между признаками. Расчет сводных показателей в целом позволяет изучить ее структуру. Группировка создает основу для последующей сводки и анализа данных. Этим определяется роль группировок как научной основы сводки. Ведение группировочных таблиц превращает группировки) в эффективный метод анализа и вскрытия резервов в экономике.
Задачи группировок:
· выделение социально-экономических типов явлений;
· изучения структуры явления и структуры сдвигов, происходящих в нем;
· выявление связей и зависимостей между отдельными признаками явления.
Виды группировок:
типологические, структурные и аналитические (факторные).
Типологическая группировка решает задачу выявления и характеристики социально-экономических типов путем разделения качественно разнородной совокупности на классы, социально-экономические типы, однородные группы единиц в соответствии с правилами научной группировки. Например, группировки секторов экономики, хозяйствующих субъектов по формам собственности. В структурной группировке происходит разделение выделенных с помощью типологической группировки типов явлений, однородных совокупностей группы, характеризующие их структуру по какому-либо варьирующему признаку. Например, группировка: хозяйств по объему Анализ структурных группировок, взятых за ряд периодов или моментов времени, показывает изменение структуры изучаемых явлений, т.е. структурные сдвиги. В изменении структуры общественных явлений отражаются важнейшие закономерности их развития. Одна из задач группировок — исследование связей и зависимостей между изучаемыми явлениями и их признаками. Это достигается с помощью аналитических (факторных) группировок. В основе аналитической группировки лежит факторный признак, и каждая выделенная группа характеризуется средними значениями результативного признака.
В зависимости от степени сложности массового явления и задач анализа группировки могут производится по одному признаку (в этом случае группировка называется простой) или нескольким (сложная группировка). Если группы, образованные по одному признаку, делятся затем на подгруппы по второму и т.д.) признакам, то такая группировка называется комбинационной. Использование в аналитических исследованиях теории распознавания образов позволило разработать метод группировки совокупности единиц одновременно по множеству характеризующих признаков. Такие группировки называют многомерными. Многомерная группировка (многомерная классификация) основана на измерении сходства или различия между объектами: единицы, отнесенные к одной группе (классу) отличаются между собой меньше, чем единицы, отнесенные к разным группам (классам). Мерой близости (сходства) между объектами могут служить различные критерии.
При составлении структурных группировок определяют интервалы группировки и количество групп. Интервал — количественное значение, отделяющее одну группу от другой. Количество групп зависит от числа единиц исследуемого объекта и степени изменения группировочного признака, а также особенностей изучаемого процесса или явления. Интервалы могут быть неравными (прогрессивно возрастающими или прогрессивно убывающими). Использование неравных интервалов объясняется тем, что количественные изменения размера признака имеют не одинаковые значения в низших и высших по размеру признака группы. Интервалы могут быть закрытыми (указываются верхняя и нижняя границы) и открытыми (указывается лишь одна из границ).
В случае использования готовых группировок, не удовлетворяющих требованиям анализа (например, по причине несопоставимости группировок из-за различного числа выделенных групп или неодинаковых границ интервалов), применяется метод вторичной группировки. Этот метод позволяет привести такие группировки к сопоставимому виду для проведения их дальнейшего сопоставительного анализа. Известно два способа перегруппировки: 1) объединение (укрупнение) первоначальных интервалов; 2) долевая перегруппировка (закрепление за каждой группой определенной доли единиц).
Источник
14. Группировка данных. Виды группировок.
Перегруппировка
Эта статья условно открывает вторую часть курса Математической статистики, и начнём мы с простенького материала, который вполне бы мог войти в 1-й урок, но оказался там немного не в тему, поскольку сам открывает большую тему 🙂
Рассмотрим некоторую статистическую совокупность, например, множество студентов ВУЗа. Очевидно, это множество можно исследовать как единое целое – подсчитать общее количество студентов, вычислить их средний возраст, среднюю успеваемость и др. характеристики. Благо, статистических данных – море. Но всё это общие характеристики. Во многих случаях совокупность целесообразно разделить на группы, то есть выполнить группировку.
Группировка – это разделение статистической совокупности (не важно, генеральной или выборочной) на группы по одному или бОльшему количеству признаков.
И разделить её можно по-разному. Во-первых, выделить качественно однородные группы. Например, разделить студентов ВУЗа на лиц М и Ж пола. Такая группировка называется типологической. Или, как вы любите говорить, «типа логической» 🙂 Кстати, студенты уже по факту разделены на факультеты – и это тоже пример типологической группировки, но уже по другому признаку.
Итак, типологическая группировка – это разделение неоднородной статистической совокупности на качественно однородные группы.
Само собой полученные группы исследуются по отдельности и сравниваются – как между собой, так и с общими показателями. При этом проводится структурная группировка – это разделение качественно однородной совокупности по какому-либо вариационному признаку. По росту, весу, уровню IQ, скорости движения, периоду полураспада и так далее. Признаков – тьма.
Да будет свет! – в качестве простейшего условного примера рассмотрим среднюю успеваемость студентов ВУЗа: 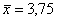 (общая средняя). Но это не слишком информативный показатель.
(общая средняя). Но это не слишком информативный показатель.
Гораздо интереснее провести типологическую группировку, например, разделить всех студентов на «физиков» и «лириков», и подсчитать групповые средние: 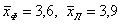 . Ну вот, теперь прекрасно видно, кому в универе жить хорошо 🙂 Или рассчитать групповые средние по факультетам:
. Ну вот, теперь прекрасно видно, кому в универе жить хорошо 🙂 Или рассчитать групповые средние по факультетам: 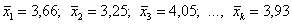 . И выяснить, почему это на 2-м факультете такая низкая успеваемость по сравнению со средней успеваемостью
. И выяснить, почему это на 2-м факультете такая низкая успеваемость по сравнению со средней успеваемостью 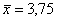 по ВУЗу.
по ВУЗу.
Довольно часто грань между типологической и структурной группировкой стирается. Приведу избитый, но показательный пример с банками. Все банки можно разделить на мелкие, средние и крупные (типологическая группировка). Но с другой стороны, эти категории основаны на количественном показателе, мелкие – меньше одного литра, средние – от одного до трёх, и крупные – больше трёх литров. То есть, это одновременно и структурная группировка.
Следует отметить, что при кажущейся простоте провести подобную группировку бывает не так-то просто. Трудность состоит в том, чтобы грамотно выделить различные категории (типы), и для этого, порой, исследуют целый комплекс показателей. Эксперты Центробанки гарантируют 🙂
Кроме того, существуют и другие виды группировок, в частности, аналитическая группировка и комбинационная группировка. Но о них позже, после практической разминки.
Ранее мы уже неоднократно проводили группировку данных, давайте вспомним пару примеров:
По результатам выборочного исследования рабочих цеха были установлены их квалификационные разряды: 4, 5, 6, 4, 4, 2, 3, 5, 4, 4, 5, 2, 3, 3, 4, 5, 5, 2, 3, 6, 5, 4, 6, 4, 3.
…
В этой задаче была проведена структурная группировка рабочих цеха по их разряду и получен дискретный вариационный ряд: 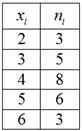
где 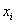 – разряды, а
– разряды, а 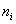 – количество рабочих того или иного разряда
– количество рабочих того или иного разряда
По результатам исследования цены некоторого товара в различных торговых точках города, получены следующие данные (в некоторых денежных единицах): 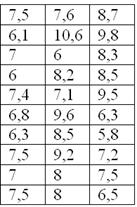
…
В этом примере мы тоже провели структурную группировку (товаров по их цене) и получили интервальный вариационный ряд: 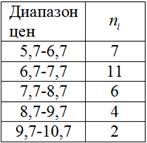
где 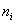 – количество товаров из того или иного ценового интервала.
– количество товаров из того или иного ценового интервала.
И сейчас мы продолжим группировать данные. Студентам чаще всего предлагают провести структурную и аналитическую группировку; разберём их по порядку. Затем потренируемся в комбинационной группировке, ну а группировку типологическую я оставлю за кадром, полагаю, разделить совокупность на кошек и собак ни у кого не вызовет трудностей.
Суровая задача местного Политеха для студентов около- и машиностроительных специальностей:
В результате выборочного исследования 30 станков рассчитаны их относительные показатели металлоёмкости (т/кВт): 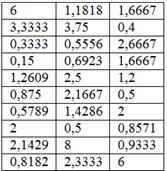
а) вычислить общую среднюю;
б) выполнить структурную равноинтервальную группировку;
в) выполнить структурную равнонаполненную группировку;
г) выбрать наиболее удачную группировку и вычислить выборочные средние; результаты оформить в виде групповой таблицы;
д) по выбранной группировке построить интервальный вариационный ряд;
е) сделать выводы.
Но прежде немного о содержании. Согласно автору методички, относительная металлоемкость – это частное от деления веса станка на мощность его двигателя (тонн на киловатт). Разделили, например, 5 тонн на 2 кВт и получили 2,5 тонны на один кВт. Эти значения и представлены в таблице. Правильность и достоверность перечисленных фактов в который раз оставлю на совести автора, да и, в конце концов, нам требуется обработать числа, а уж что это такое – не особо важно, хоть объём талии пчёлок. …И всё-таки математика немного шизофреническая наука 🙂
Решение:
Ну, с пунктом а) справится даже неподготовленный человек. Очевидно, что для нахождения общей средней нужно просуммировать все значения и разделить полученный результат на объём выборки:
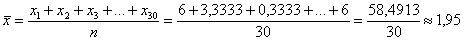 т/кВт (не забываем указать размерность)
т/кВт (не забываем указать размерность)
Эти и другие вычисления легко выполняются в Экселе, и чуть ниже будет ролик о том, как быстро выполнить все пункты задания. Ибо на калькуляторе щёлкать 30 слагаемых муторно (хотя, вариант вполне рабочий).
б) Выполним структурную равноинтервальную группировку. Пугаться не нужно, это задание уже было – нам нужно построить обычный интервальный вариационный ряд с равными интервалами, и я кратко повторю алгоритм.
В условии ничего не сказано о количестве интервалов, и поэтому для определения их оптимального количества используем формулу Стерджеса:
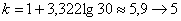 интервалов (результат округляем влево).
интервалов (результат округляем влево).
Найдём минимальное 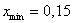 и максимальное
и максимальное 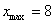 значения и вычислим размах вариации:
значения и вычислим размах вариации: 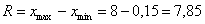 т/кВт. Таким образом, длина каждого интервала составит:
т/кВт. Таким образом, длина каждого интервала составит: 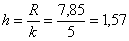 т/кВт. Теперь «нарезаем» интервалы и подсчитываем количество станков
т/кВт. Теперь «нарезаем» интервалы и подсчитываем количество станков  в каждом из них:
в каждом из них: 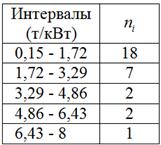
Контроль: 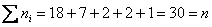 , что и требовалось проверить.
, что и требовалось проверить.
И уже сейчас мы видим, что построенный вариационный ряд не слишком хорош – по той причине, что в трёх последних интервалах слишком мало станков, и считать по ним средние значения и другие показатели не вполне корректно.
Во избежание этого недостатка используют разные методы, и один из них состоит в том, что использовать:
в) равнонаполненную группировку. Это разбиение совокупности на группы с одинаковым (или примерно одинаковым) количеством объектов, станков в данном случае. Но интервалы здесь получатся разной длины.
Отсортируем числа по возрастанию и выделим 5 групп по 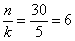 станков в каждой:
станков в каждой: 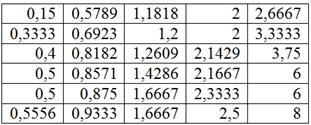
Формально всё выглядит тип-топ (и можно оставить так), но некоторые значения логичнее перенести в соседние группы. Так, значение 0,5789 (верхняя строка) явно ближе к 1-й группе, а значение 2,6667 – к предпоследней группе; туда их и перенесём: 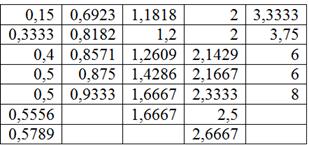
г) Очевидно, что равнонаполненная группировка более удачна, с ней и работаем. По каждой группе подсчитаем суммы, количество станков и выборочные средние. Результаты представим в виде групповой таблицы: 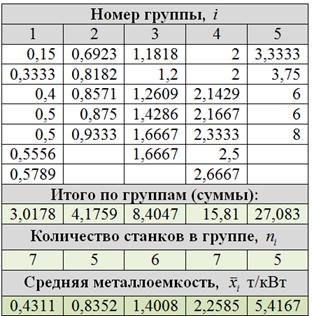
И на всякий пожарный примеры расчёта групповых средних:
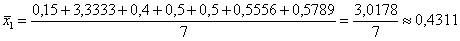 т/кВт;
т/кВт;
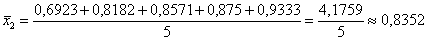 т/кВт;
т/кВт;
и так далее. Вычисления удобно проводить опять же в Экселе (см. ролик ниже).
Да, кстати, не забываем предварительно проконтролировать объём выборки: 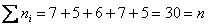 , что и требовалось проверить.
, что и требовалось проверить.
д) Построим интервальный вариационный ряд по равнонаполненной группировке. Границы интервалов можно брать как средние арифметические «стыковых» значений, например: 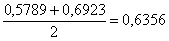 (граница между 1-м и 2-м интервалом). Но вполне допустимо (и даже лучше) разметить интервалы «на глазок», выбирая удобные «круглые» значения:
(граница между 1-м и 2-м интервалом). Но вполне допустимо (и даже лучше) разметить интервалы «на глазок», выбирая удобные «круглые» значения: 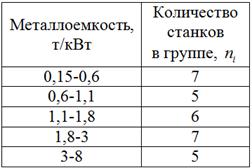
Полученный интервальный ряд имеет разную длину интервалов, но для него точно так же можно построить гистограмму, полигон и эмпирическую функцию распределения, а также рассчитать различные характеристики. Правда, с модой проблема будет и для её нахождения таки лучше использовать равноинтервальную группировку (пункт б).
Теперь смотрим ролик по быстрому и эффективному выполнению задания:
 Как выполнить структурную группировку и вычислить средние? (Ютуб)
Как выполнить структурную группировку и вычислить средние? (Ютуб)
Выражаясь научно, мы выполнили статистическую сводку. Статистическая сводка – это комплекс действий по обработке статистических данных с целью анализа спастической совокупности. Причём, в пункте а) была простая статическая сводка (подсчёт общих показателей), которая переросла в сводку сложную, включающую в себя группировку данных, расчёт групповых характеристик и сведение результатов в групповую таблицу.
е) Я не случайно выделил этот пункт. Довольно часто в заданиях подобного типа требуется сделать краткие выводы – в них нужно отразить основные результаты выполненных действий и особенности исследуемой совокупности.
И мы сделаем простенькие выводы. Сказать здесь можно следующее. В результате исследования рассчитана средняя металлоёмкость 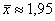 т/кВт по выборке и средние значения по группам равнонаполненной (наиболее удачной) группировки. Большинство станков (18 шт. в первых трёх группах) имеют показатель металлоёмкости меньший, чем средняя металлоёмкость по выборке. Пять станков (группа 5) обладают значительно бОльшей металлоёмкостью, чем остальные, и причины этого требуют отдельного анализа (возможно, станки морально устарели).
т/кВт по выборке и средние значения по группам равнонаполненной (наиболее удачной) группировки. Большинство станков (18 шт. в первых трёх группах) имеют показатель металлоёмкости меньший, чем средняя металлоёмкость по выборке. Пять станков (группа 5) обладают значительно бОльшей металлоёмкостью, чем остальные, и причины этого требуют отдельного анализа (возможно, станки морально устарели).
Несколько строчек вполне достаточно, даже многовато получилось.
Следующее задание для самостоятельного решения:
По результатам выборочного исследования 50 предприятий получены данные об их квартальной прибыли (числа в экселевском файле), млн. руб. Требуется: 1) вычислить среднюю прибыль, 2) провести равнонаполненную группировку и вычислить групповые средние, 3) построить соответствующий вариационный ряд, 4) сделать выводы.
Вообще, здесь удобно разбить выборку на 5 интервалов (и такой вариант вполне себе неплох), но от греха подальше лучше использовать формулу Стерджеса, что я и сделал в образце решения, который, как обычно, находится внизу страницы. Ваш вариант решения может немного отличаться от моей версии.
Теперь вернёмся к пункту «бэ» Примера 55, где была выполнена не слишком удачная равноинтервальная группировка, скопирую табличку сверху: 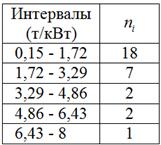
Как вы помните, от «куцых» интервалов мы избавились, выполнив равнонаполненную группировку. Но есть и другой метод «лечения», который называется перегруппировкой.
Перегруппировка – это вторичная группировка, которая состоит в преобразовании уже построенного вариационного ряда. И одним из инструментов перегруппировки является укрупнение интервалов. В данном случае можно просто объединить три последних интервала, и, коль скоро, нам известны первичные (исходные) данные, то заодно подкорректируем границы всех интервалов до удобных значений: 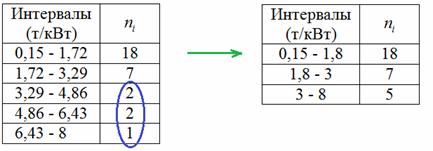
Не так, конечно, получилось подробно, как в равнонаполненной группировке, но тоже вполне наглядно. При желании, к слову, первый интервал легко измельчить, получив нечто близкое или даже совпадающее с этой группировкой. Благо, исходные числа в нашем распоряжении.
Но что делать, если первичные данные не известны?
Перегруппируйте следующие данные о численности работающих на 55 предприятиях, образовав следующие группы: до 400, 400-1000, 1000-3000, 3000-6000, свыше 6000: 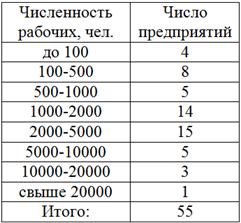
В этой задаче мы не знаем исходные варианты (конкретную численность рабочих по предприятиям), но решение есть! Для удобства оформлю его по пунктам, ВНИМАТЕЛЬНО вникайте в суть:
1) Выделим новый промежуток «до 400» (красный цвет на рисунке ниже). В него, понятно, войдёт интервал «до 100» (4 предприятия) и часть интервала «100-500», а именно часть 100-400, выделенная коричневым цветом: 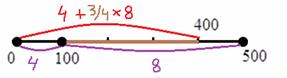
Теперь длину коричневой части 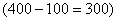 нужно сопоставить с длиной интервала «100-500» (с
нужно сопоставить с длиной интервала «100-500» (с 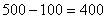 ):
):
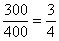 – таким образом, три четверти предприятий интервала «100-500» следует отнести в пользу промежутка «до 400»:
– таким образом, три четверти предприятий интервала «100-500» следует отнести в пользу промежутка «до 400»: 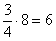 .
.
Итого в промежутке «до 400» оказывается 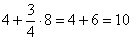 предприятий.
предприятий.
…вроде всё просто, а объяснить было довольно сложно 🙂 Соответственно, на кусок «400-500» останется 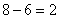 предприятия. Выражаясь кратко, этот принцип можно называть выделением пропорциональных долей. Доли выделяются пропорционально длинам частей интервала.
предприятия. Выражаясь кратко, этот принцип можно называть выделением пропорциональных долей. Доли выделяются пропорционально длинам частей интервала.
2) Выделим новый промежуток «400-1000». В него войдёт оставшийся старый «кусок» «400-500» с двумя предприятиями и старый интервал «500-1000» с 5 предприятиями: 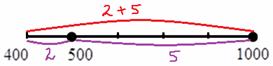
Итого на промежутке «400-1000» оказалось 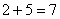 предприятий.
предприятий.
3) Выделим новый промежуток «1000-3000». В него полностью войдёт старый интервал «1000-2000» с 14 предприятиями и одна треть интервала с «2000-5000» с 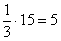 предприятиями:
предприятиями:
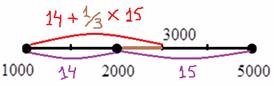
Нужную долю (одну треть) мы нашли как отношение длины коричневого интервала 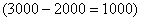 к длине интервала «2000-5000»
к длине интервала «2000-5000» 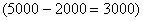 :
: 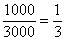
Таким образом, в промежуток «1000-3000» вошло 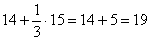 предприятий.
предприятий.
4) В новый промежуток «3000-6000» входят две трети старого интервала «2000-5000» (см. рис. выше), что составляет 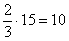 предприятий (или
предприятий (или 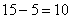 ), и, кроме того, одна пятая старого интервала «5000-10000», к которой относится
), и, кроме того, одна пятая старого интервала «5000-10000», к которой относится 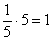 предприятие:
предприятие: 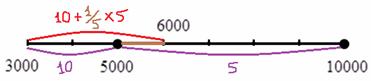
Одна пятая найдена как отношение длины коричневого интервала «5000-6000» к длине интервала «5000-10000»: 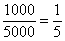
Таким образом, в промежуток «3000-6000» вошло 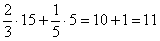 предприятий.
предприятий.
5) И, наконец, в последний новый промежуток «свыше 6000» входят четыре пятых старого интервала «5000-10000» (см. рис. выше) или 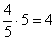 предприятия, а также 3 предприятия старого интервала «10000-20000» и 1 предприятие интервала «свыше 20000».
предприятия, а также 3 предприятия старого интервала «10000-20000» и 1 предприятие интервала «свыше 20000».
Итого: 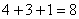 предприятий.
предприятий.
Перегруппировка завершена, новый вариационный ряд построен: 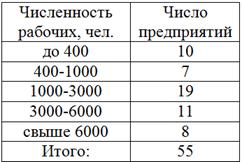
И обязательно проконтролируем объем выборки, мало ли что-то потерялось или мы где-то обсчитались: 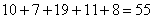 , в чём и требовалось убедиться.
, в чём и требовалось убедиться.
Следует отметить, что метод выделения долей, строго говоря, не точен, и если в нашем распоряжении есть первичные данные, то, конечно же, ориентируемся на них – в результате с высокой вероятностью получатся немного другие частоты по группам. Но для выборочной совокупности годится и долевая перегруппировка, поскольку от выборки к выборке мы всё равно будем получать разные значения и строить похожие, но всё же разные вариационные ряды.
Перегруппировка часто применятся для того чтобы сопоставить «родственные» совокупности с разными интервалами:
По результатам выборочного исследования двух банок банков получены данные о заработной плате их служащих: 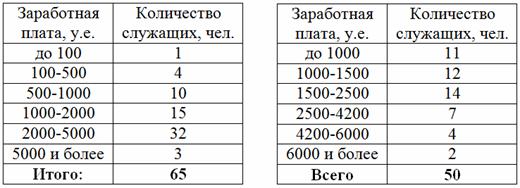
Сравнить уровень заработной платы банков, выделив интервалы: до 500, 500-1000,
1000-2000, 2000-3000, 3000-4000, 4000-5000, свыше 5000, и рассчитав относительные частоты по каждому банку. Результаты представить в виде общей таблицы, сделать выводы.
Для удобства я заготовил для вас Эксель-шаблон, не ленимся! Если трудно, то можно использовать рисунки с разметкой интервалов (по образцу предыдущего примера), в образце я ограничился аналитическим решением.
И я жду вас на следующем уроке, который посвящён дисперсиям, коль скоро, были средние, то где-то рядом нас поджидают и дисперсии.
Решения и ответы:
Пример 56. Решение:
1) вычислим среднюю квартальную прибыль предприятий:
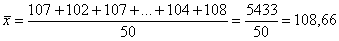 млн. руб.
млн. руб.
2) Проведём равнонаполненную группировку с равным или примерно равным количеством предприятий в каждой группе.
Оптимальное количество интервалов определим по формуле Стерджеса:
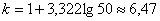 и, округляя влево, получаем 6 интервалов. Таким образом, в каждом интервале будет содержаться
и, округляя влево, получаем 6 интервалов. Таким образом, в каждом интервале будет содержаться 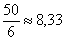 – от 7 до 9 предприятий.
– от 7 до 9 предприятий.
Упорядочим совокупность по возрастанию и выделим в ней следующие группы; в групповой таблице вычислим суммы и групповые средние: 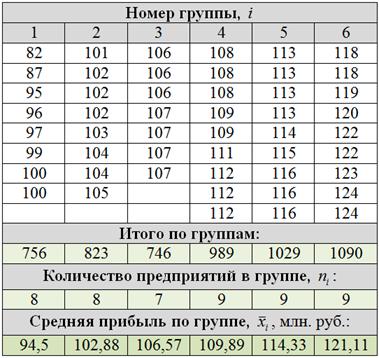
Промежуточный контроль: 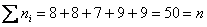 , ч.т.п.
, ч.т.п.
3) Построим интервальный вариационный ряд: 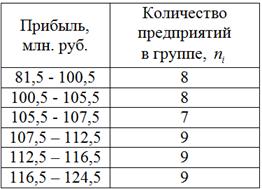
4) Средняя прибыль предприятий за квартал составила 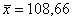 млн. руб. Прибыль варьируется в пределах от 82 до 124 млн. руб. и равнонаполненная группировка показала, что распределение предприятий по данному показателю близкО к равномерному. То есть, практически нет предприятий со слишком большой или слишком малой прибылью.
млн. руб. Прибыль варьируется в пределах от 82 до 124 млн. руб. и равнонаполненная группировка показала, что распределение предприятий по данному показателю близкО к равномерному. То есть, практически нет предприятий со слишком большой или слишком малой прибылью.
З.Ы. Возможно, вы заметили что-то ещё! 😉
Пример 58. Решение: 1) выполним перегруппировку по 1-му банку:
– В новый промежуток «до 500» войдут интервалы «до 100» и «100-500»:
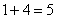 чел.
чел.
– Новые промежутки «500-1000, 1000-2000» совпадают со старыми интервалами.
– Новые промежутки «2000-3000, 3000-4000, 4000-5000» полностью входят в старый интервал «2000-5000». Делим частоту этого интервала на 3:
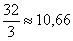 – в каждый новый промежуток.
– в каждый новый промежуток.
В промежутки «2000-3000, 3000-4000» относим по 11 человек, а в промежуток «4000-5000» – 10 человек (предполагая то, что людей с бОльшей заработной платой – меньше)
– Новый промежуток «5000 и более» совпадает со старым интервалом.
2) Выполним перегруппировку второго вариационного ряда:
– Старый интервал «до 1000» разобьём на два новых равных промежутка, при этом в промежуток «до 500» отнесём 5 человек, а в промежуток «500-1000» – 6 человек (предполагая, что людей с более низкой з/п – чуть меньше)
– В новый промежуток «1000-2000» входит интервал «1000-1500» и половина интервала «1500-2500», в людях это составит:
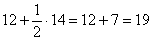 чел.
чел.
– В новый промежуток «2000-3000» входит половина интервала «1500-2500» и 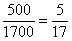 интервала «2500-4200», в людях это составляет:
интервала «2500-4200», в людях это составляет:
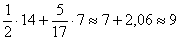 чел.
чел.
– В новый промежуток «3000-4000» входит 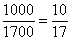 интервала «2500-4200», в людях это составляет:
интервала «2500-4200», в людях это составляет:
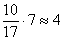 чел.
чел.
– В новый промежуток «4000-5000» входит 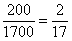 интервала «2500-4200» и
интервала «2500-4200» и 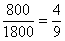 интервала «4200-6000», в людях это составит:
интервала «4200-6000», в людях это составит:
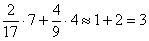 чел.
чел.
– И в новый промежуток «свыше 5000» входит 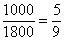 интервала «4200-6000» и интервал «свыше 6000», в людях это составит:
интервала «4200-6000» и интервал «свыше 6000», в людях это составит:
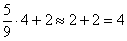 чел.
чел.
Результаты сведём в единую таблицу, при этом рассчитаем относительные частоты по каждому банку: 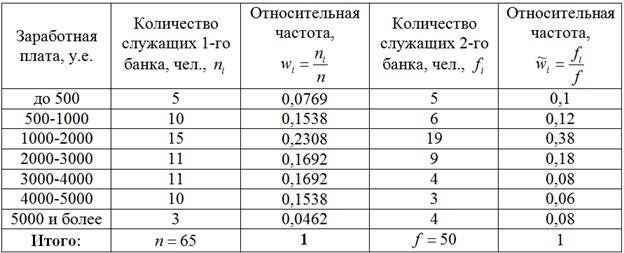
Краткие выводы: Для обоих банков характерна зарплата от 1000 до 2000 у.е., однако в 1-м банке чуть более высокий уровень заработной платы – значительное количество сотрудников получает более 2000 у.е. Но, скорее всего, основная их масса имеет з/п в диапазоне 2000-3000, здесь требуется дополнительное исследование первичных данных, поскольку формальное разбиение интервала «2000-5000» на три равных интервала не очень удачно.
З.Ы. Возможно, вы заметили что-то ещё! 😉
Автор: Емелин Александр
(Переход на главную страницу)
 «Всё сдал!» — онлайн-сервис помощи студентам
«Всё сдал!» — онлайн-сервис помощи студентам
Источник



