
- Способы хранения графов в памяти компьютера
- Введение
- Матрица смежности
- Описание Бержа
- Список дуг
- Список смежности
- Оптимизация к списку смежности
- Заключение
- Структуры данных для хранения графов: обзор существующих и две «почти новых»
- 1. Матричные структуры данных
- 2. Перечислительные структуры данных
- 3. Вектор смежности и Ассоциативный массив смежности
- 4. Структур данных хоть «залейся», а чего-то не хватает
Способы хранения графов в памяти компьютера
Если Вы хоть немного знакомы с теорией графов, Вам наверняка интересно, как же правильно хранить граф в памяти компьютера. В этой статье рассмотрено 4 способа, как это сделать. Также проведён полный их анализ и размышления на эту тему.
Введение
Для начала разберёмся, что же такое граф и какие они бывают.
Граф — множество V вершин и набор E неупорядоченных и упорядоченных пар вершин. Говоря проще, граф — это множество точек (вершин) и соединяющих их путей (дуг или рёбер). Граф может быть ориентированным и неориентированным. В ориентированном графе пути (дуги) имеют направление, а в неориентированном — не имеют. Пути в неориентированном графе называются рёбрами.
Взвешенным называется такой граф, для каждого ребра(дуги) которого определена некоторая функция. А эта функция называется весовой.
Рассмотрим пример ориентированного взвешенного графа:
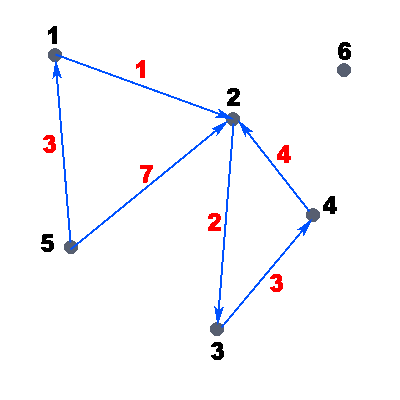
На рисунке точками обозначены вершины графа, стрелками — дуги, чёрные числа — номера вершин графа, а красные — веса дуг. Вес дуги можно представить также как стоимость. Т.е. например: дан граф, нужно дойти от вершины i до вершины j, заплатив минимальное количество денег/потратив наименьшее количество времени. Пусть в нашем графе, который представлен на рисунке, нам нужно пройти из вершины 5 в вершину 2, а вес дуг — стоимость прохода по данному ребру. В данном примере очевидно, что выгоднее пройти через вершину 1 и только потом прийти в вершину 2, так мы заплатим всего 4 единицы денег, иначе, если пойти напрямую, мы заплатим целых 7 единиц.
Ну вот мы и разобрались, что такое граф. На рисунке всё смотрится красиво, все задачи вроде бы решаются легко… Но! А если граф будет действительно большим, например на 1000 вершин? Да, такой граф на бумажке рисовать очень долго и неприятно… Пускай лучше всё это делает за нас компьютер!
Теперь осталось только научить компьютер работать с графами. Сам я довольно часто участвую в олимпиадах по информатике, а там очень любят давать задачи на графы. От того, как хранить граф в той или иной задаче очень много зависит… После того, как я придумал полное решение, но, написав его, получил только половину баллов, я задумался, а правильно ли я хранил граф?
Проблема правильного хранения графа в памяти компьютера действительно актуальна в сегодняшние дни. Я решил выяснить, так какой же из способов всё-таки лучше.
Матрица смежности
Один из самых распространённых способов хранения графа — матрица смежности. Она представляет из себя двумерный массив. Если в клетке i,j установлено значение ПУСТО, то дуги, начинающейся в вершине i и кончающейся в вершине j, нет. Иначе дуга есть. Чаще всего за значение ПУСТО берут 0, а в клетки, которые обозначают наличие дуги, вписывают вес этой дуги. Если граф не взвешенный, то вес дуги считается равным единице. Нарисуем матрицу смежности для нашего графа:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 2 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 3 | 0 | 0 |
| 4 | 0 | 4 | 0 | 0 | 0 | 0 |
| 5 | 3 | 7 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 |
Я намеренно употреблял слово “дуга”, т.к. матрица смежности приспособлена ТОЛЬКО для ориентированных графов. Очень много способов хранения приспособлены только для ориентированных графов. Однако почти во всех задачах ребро можно заменить двумя дугами, т.е. если у нас есть ребро (1,3), то мы можем заменить его на дуги (1,3) и (3,1) — так мы сможем пройти в любом направлении в любое время.
Как вы уже заметили, в матрице смежности нам часто нужно хранить большое количество нулей. Например, в нашей матрице “нужных” значений только 6, а остальные 30 — нули, не представляющие для нас почти никакой нужной информации.
Для представления графа матрицей смежности нужно V в квадрате (где V — количество вершин). Если граф почти полный, т.е. Е почти развно V в квадрате (где Е — количество дуг), этот способ хранения графа наиболее выгоден, т.к. его очень просто реализовывать и память будет заполнена “нужными” значениями.
Кроме большого количества требуемой памяти и медленной работы на разреженных графах у матрицы смежности есть ещё один важный недостаток. Иногда в задачах нужно выводить не номера вершин, а номера дуг(рёбер) на вводе. Хранить эти номера матрица смежности не умеет. Нужно реализовывать восстановление номера дуги(ребра) как-то иначе, а это совсем неудобно.
Временные сложности сведены в таблицу:
| Операция | Временная сложность |
|---|---|
| Проверка смежности вершин x и y | О(1) |
| Перечисление всех вершин смежных с x | О(V) |
| Определение веса ребра (x, y) | О(1) |
| Перечисление всех ребер (x, y) | О(V2) |
Описание Бержа
Для того чтобы ускорить работу матрицы смежности на разреженных графах, можно использовать другой тип хранения графа — описание Бержа. Для каждой вершины хранится список смежных вершин. Чаще всего для этого используется двумерный массив размером V в квадрате, в строке u которого хранятся номера вершин, смежных с u. В нулевой элемент строки u вписывается количество вершин, хранящихся в данной строке. Теперь попробуем представить наш граф при помощи описания Бержа на примере:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 2 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 3 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 4 | 0 | 0 | 0 | 0 | 0 |
| 4 | 1 | 2 | 0 | 0 | 0 | 0 | 0 |
| 5 | 2 | 1 | 2 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
В нулевом столбце хранятся “длины” строк. Однако, вес дуг никак не хранится, а если его хранить отдельно, то нужно заводить ещё один массив размером V в квадрате…
Временные сложности сведены в таблицу:
| Операция | Временная сложность |
|---|---|
| Проверка смежности вершин x и y | О(V) |
| Перечисление всех вершин смежных с x | О(V) |
| Определение веса ребра (x, y) | Вес не хранится |
| Перечисление всех ребер (x, y) | О(Е) |
Список дуг
Следующий тип хранения графа в памяти компьютера — список дуг. Чаще всего это двумерный массив размером 3*E, в первой строке которого хранится информация, из какой вершины начинается дуга, во второй — в какой кончается, а в третьей строке — вес дуги. Опять же разберёмся на примере:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 2 | 3 | 4 | 5 | 5 | 0 | 0 |
| 2 | 2 | 3 | 4 | 2 | 1 | 2 | 0 | 0 |
| 3 | 1 | 2 | 3 | 4 | 3 | 7 | 0 | 0 |
Мы чётко видим, что почти вся таблица заполнена “нужными” значениями, а не нулями. Это уже хорошо, значит, память экономится.
Временные сложности сведены в таблицу:
| Операция | Временная сложность |
|---|---|
| Проверка смежности вершин x и y | О(E) |
| Перечисление всех вершин смежных с x | О(E) |
| Определение веса ребра (x, y) | О(E) |
| Перечисление всех ребер (x, y) | О(E) |
| Поиск i-ой дуги | О(1) |
Как видно, этот способ, в отличие от матрицы смежности и описания Бержа, хранит информацию о номере дуги. Также ясно, что этот способ нам выгоден, если чаще всего нам нужно будет узнать что-то (вес, вершины начала или конца) о i-ой дуге. Однако, такие задачи в практическом программировании встречаются довольно редко.
Если в предыдущих представлениях одно ребро мы заменяли двумя дугами, то список дуг может хранить или дуги или рёбра (в зависимости от реализации). Это довольно удобно и может требовать в 2 раза меньше памяти.
Список смежности
И последний способ, про который я вам расскажу — список смежности. Он представляет из себя два массива: vert и adj.
Из каждой вершины может выходить 0, 1 и более дуг, причём вершин будет V или менее. Если из вершины i не выходит дуг (т.е. количество дуг равно нулю), то в массиве vert в i-ой клетке будет храниться значение ПУСТО. Если из вершины i выходит хотя бы одна дуга, то в массиве vert в i-ой клетке будет храниться номер элемента массива adj, в котором хранится конечная вершина дуги. Также в массиве adj хранится вес дуги, и указатель на следующую “конечную” вершину дуги, которая начинается в вершине i. Поначалу может показаться, что этот способ очень запутан, т.к. один массив указывает на другой, другой сам на себя, при чём много раз. Однако это не совсем так, т.к. следует лишь несколько раз самому попробовать реализовать хранение графа таким способом, и он кажется очень мощным, полезным и несложным. Давайте сами попробуем разобраться на примере.
На вход нам подаются следующие данные:
Так выглядит массив vert:
| 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| 2 | 4 | 5 | 3 | 1 | 0 |
А вот так массив adj:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 2 | 2 | 3 | 4 | 2 | 0 | 0 |
| 2 | 3 | 1 | 4 | 2 | 3 | 7 | 0 | 0 |
| 3 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
В массиве adj первая строка — конечная вершина дуги, вторая — её вес, а третья — ссылка на следующую.
В этом примере я специально вводил дуги не по порядку, чтобы можно было лучше разобраться, и было видно, что позиции могут быть совершенно различными. Например, первая конечная вершина дуги, начинающейся в вершине 5, лежит в массиве adj на первой позиции, а не на пятой.
Рассмотрим временные сложности:
| Операция | Временная сложность |
|---|---|
| Проверка смежности вершин x и y | О(E) |
| Перечисление всех вершин смежных с x | О(E) |
| Определение веса ребра (x, y) | О(E) |
| Перечисление всех ребер (x, y) | О(E) |
| Поиск i-ой дуги | О(1) |
Времена у всех операций, вроде бы, такие же, как и у списка рёбер. Однако, большинство из них реально намного меньше. Например, проверка смежности вершин x и y и перечисление всех вершин смежных с x в списке рёбер гарантированно будет выполнятся О(Е) операций, т.к. нам обязательно нужно пробежать весь список, а в списке смежности мы бежим только по вершинам, смежным с х.
Оптимизация к списку смежности
UPD: Данная оптимизация не актуальна. Лучше вместо хранения ссылки на следующий элемент хранить ссылку на предыдущий.
Когда я первый раз пытался разобраться, что такое список смежности, меня очень смутила процедура добавления дуги. Для того, чтобы добавить дугу (i,j) мы должны начать из вершины i и пройти по всем вершинам, смежными с нею. И так каждый раз! А что если вершине х инцидентны E рёбер? Тогда сложность добавления O(E в квадрате) ! Это совсем не годится.
А почему бы нам не добавлять ребро сразу туда, куда надо? Конечно, при считывании, мы сразу записываем данные в нужную нам ячейку (в конец получившегося списка). Но ведь на эти данные нужно сделать указатель. Самое тяжёлое — найти место, где делать указатель. Поиск этого места и занимает основу драгоценного времени. А что, если хранить указатель не только на первую конечную вершину дуги, но и на последнюю? Тогда наша проблема решена! Добавление занимает О(1) времени, но требует дополнительно О(V) памяти…
Рассмотрим данную оптимизацию на примере. Изменится только вид массива vert, поэтому рассмотрим только его:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 5 | 3 | 1 | 0 |
| 2 | 2 | 4 | 5 | 3 | 6 | 0 |
Здесь в первой строке массива vert хранится указатель на первую конечную вершину, во второй — на последнюю. В данном примере польза от этой оптимизации почти не заметна, т.к. максимальное вершин, исходящих из одной дуги, равно 2, что очень мало. Если дуг, инцидентных одной вершине, будет много, то и ускорение будет довольно большое и “лишняя” выделенная память окупится.
Возможно, о данной оптимизации к списку смежности где-то уже было написано до меня, но ни в интернете, ни в печатных источниках я этого не встречал.
Заключение
Я пытался найти универсальный способ хранения графа в памяти компьютера, который бы хранил максимально много информации о графе, работал с любыми графами и работал бы быстро. Однако, универсального способа нет. Для различных задач и графов оптимальны различные представления. Конечно, наиболее мощным и универсальным способом хранения является список смежности. С моей оптимизацией он работает быстрее и всё ещё требует не так уж и много памяти. Однако, если количество дуг приближается к квадрату количества вершин, то лучше матрицы смежности способа не найти, т.к. тогда скорость работы и количество памяти даже списка смежности приближается к матрице смежности, если не требует больше… Конечно, можно написать и список смежности, однако пишется он дольше матрицы смежности, да и работать с матрицей смежности намного проще.
Конечно, мною были рассмотрены не все способы представления графов в памяти компьютера. Я старался рассмотреть лишь те, которые смогут реально помочь в олимпиадном программировании, т.е. пишутся наиболее быстро, быстро работают, и требуют немного памяти. Я рассмотрел только статические способы представления графа в памяти компьютера. Есть ещё различные динамические способы хранения графов, они занимают меньше памяти, иногда быстрее работают. Однако и пишутся они намного сложнее. Например, элементарная работа с графом, хранящимся в структуре Вирта, еле-еле влазит в 250 строк кода на паскале…
Конечно, в профессиональном программировании лучше использовать динамические методы, однако и старые добрые статические способы от них не так уж и далеко отстают! 😉
2006-01-15 RUSSIAN
russian delphi pascal graph theory algorithm алгоритм
Источник
Структуры данных для хранения графов: обзор существующих и две «почти новых»
В этой заметке я решил перечислить основные структуры данных, применяемые для хранения графов в информатике, а также расскажу о еще паре таких структур, которые у меня как-то само собой «выкристаллизовались».
Итак, начнем. Но не с самого начала – думаю, что такое граф и какие они бывают (ориентированные, неориентированные, взвешенные, невзвешенные, с множественными ребрами и петлями или без них), мы все уже знаем.
Итак, поехали. Какие же варианты структур данных для «графохранения» мы имеем.
1. Матричные структуры данных
1.1 Матрица смежности. Матрица смежности представляет из себя матрицу, где заголовки строк и столбцов соответствуют номерам вершин графа, а само значение каждого ее элемента a(i,j) определяется наличием или отсутствием ребер между вершинами i и j (ясно-понятно, что для неориентированного графа такая матрица будет симметрична, ну или же можно договориться, что все значения мы храним лишь выше главной диагонали). Для невзвешенных графов a(i,j) можно задать количеством ребер из i в j (если нет такого ребра, то a(i,j)= 0), а для взвешенных также – весом (суммарным весом) упомянутых ребер.
1.2 Матрица инцидентности. В этом случае наш граф также хранится в таблице, в которой, как правило, номерам строк соответствуют номера его вершин, а номерам столбцов – предварительно занумерованные ребра. Если вершина и ребро инцидентны друг другу, то в соответствующей ячейке записывается ненулевое значение (для неориентированных графов записывается 1 в случае инцидентности вершины и ребра, для ориентированных – «1», если ребро «выходит» из вершины и «-1», если оно в нее «входит» (запоминается достаточно легко, ведь знак «минус» тоже как бы «входит» в число «-1»)). Для взвешенных же графов опять же вместо 1 и -1 можно указывать суммарный вес ребра.
2. Перечислительные структуры данных
2.1 Список смежности. Ну тут, вроде бы, все просто. Каждой вершине графа можно, в общем случае, поставить в соответствие любую перечислительную структуру (список, вектор, массив, …), в которой будут храниться номера всех вершин, смежной данной. Для ориентированных графов будем заносить в такой список лишь те вершины, в которые есть «направленное» ребро из вершины-признака. Для взвешенных графов реализация будет более сложной.
2.2 Список ребер. Довольно популярная структура данных. Список ребер, как подсказывает нам Капитан Очевидность, и представляет собой собственно список ребер графа, каждое из которых задается начальной вершиной, конечной вершиной (для неориентированных графов здесь порядок следования не важен, хотя для унификации можно использовать различные правила, например, указывать вершины в порядке возрастания) и весом (только для взвешенных графов).
Про перечисленные выше списки-матрицы можно подробнее (и с иллюстрациями) посмотреть, например, тут.
2.3 Массив смежности. Не самая часто встречающаяся структура. По своей сути, он представляет собой форму «упаковки» списков смежности в одну перечислительную структуру (массив, вектор). Первые n (по числу вершин графа) элементов такого массива содержат стартовые индексы данного же массива, начиная с которых в нем подряд записаны все вершины, смежные данной.
Вот здесь я нашел самое понятное (для себя) объяснение: ejuo.livejournal.com/4518.html
3. Вектор смежности и Ассоциативный массив смежности
Оно так вышло, что автор этих строк, не являясь профессиональным программистом, однако периодически имевший дело с графами, чаще всего имел дело со списками ребер. Действительно, удобно, если в графе есть множественные петли и ребра. И вот, в развитие классических списков ребер, предлагаю уделить внимание и их «развитию/ ответвлению/ модификации/ мутации», а именно: вектору смежности и ассоциативному массиву смежности.
3.1 Вектор смежности
Случай (а1): невзвешенный граф
Будем называть вектором смежности для невзвешенного графа упорядоченный набор четного количества целых чисел (а[2i], a[2i+1]. где i нумеруется c 0), в котором каждая пара чисел а[2i], a[2i+1] задает ребро графа между вершинами а[2i] и a[2i+1] соответственно.
Данный формат записи не содержит сведений, является ли граф ориентированным (возможны оба варианта). При использовании формата для орграфа считается, что ребро направлено из а[2i] в a[2i+1]. Здесь и далее: для неориентированных графов, при необходимости, могут применяться требования к порядку записи вершин (например, чтобы первой шла вершина с меньшим значением присвоенного ей номера).
В C++ вектор смежности целесообразно задавать с помощью std::vector, отсюда и было выбрано название данной структуры данных.
Случай (а2): невзвешенный граф, веса ребер целочисленные
По аналогии со случаем (а1) назовем вектором смежности для взвешенного графа с целочисленными весами ребер упорядоченный набор (динамический массив) чисел (а[3i], a[3i+1], a[3i+2]. где i нумеруется c 0), где каждый «триплет» чисел а[3i], a[3i+1], a[3i+2] задает ребро графа между вершинами под номерами а[3i] и a[3i+1] соответственно, а значение a[3i+2] есть вес этого ребра. Такой граф также может быть как ориентированным, так и нет.
Случай (б): невзвешенный граф, веса ребер нецелочисленные
Виду того, что в одном массиве (векторе) нельзя хранить разнородные элементы, то возможна, например, следующая реализация. Граф хранится в паре векторов, в которой первый вектор является вектором смежности графа без указания весов, а второй вектор содержит соответствующие веса (возможная реализация для C++: std::pair ). Таким образом, для ребра, задаваемого парой вершин под индексами 2i, 2i+1 первого вектора, вес будет равен элементу под индексом i второго вектора.
Ну а зачем это надо?
Ну, автору этих строк для решения ряда задач это показалось достаточно полезным. Ну а с формальной точки зрения, тут будут такие преимущества:
- Вектор смежности, как и любая другая «перечислительная» структура, достаточно компактна, занимает меньше памяти, чем матрица смежности (для разреженных графов), относительно просто реализуется.
- Вершины графа, в принципе, могут быть промаркированы и отрицательными числами. Вдруг да понадобится и такой «изврат».
- Графы могут содержать множественные ребра и множественные петли, причем с разными весами (положительные, отрицательные, даже нулевые). Никаких ограничений тут нет.
- А еще ребрам можно присваивать разные свойства – но об этом см. п. 4.
Однако, надо признать, быстрого доступа к ребру данная «спискота» не подразумевает. И здесь на помощь спешит Ассоциативный массив смежности, о чем – ниже.
3.2 Ассоциативный массив смежности
Итак, если для нас доступ к конкретному ребру, его весу и иным свойствам является критичным, а требования к памяти не позволяют использовать матрицу смежности, то давайте подумаем, как можно изменить вектор смежности, чтобы решить данную задачу. Итак, ключом является ребро графа, которое можно задать в виде упорядоченной пары целых чисел. На что же это похоже? Уж не на ключ ли в ассоциативном массиве? А, если так, почему бы нам это и не реализовать? Пусть у нас появится такой ассоциативный массив, где каждому ключу – упорядоченной паре целых чисел – будет поставлено в соответствие значение – целое или вещественное число, задающее вес ребра. В C++ реализовывать данную структуру целесообразно на базе контейнера std::map (std::map , int> или std::map , double>), либо std::multimap, если предполагаются множественные ребра. Ну и вот, и у нас получилась структура для хранения графов, которая занимает меньше памяти, нежели «матричные» структуры, может задавать графы со множественными петлями и ребрами и даже не имеющая жестких требований к неотрицательности номеров вершин (не знаю, кому это надо, но все же).
4. Структур данных хоть «залейся», а чего-то не хватает
И правда же: при решении ряда задач у нас может возникнуть необходимость в присвоении ребрам графа каких-либо признаков и, соответственно, в их хранении. Если возможно однозначно свести эти признаки к целым числам, то возможно хранить такие «графы с дополнительными признаками» используя расширенные версии вектора смежности и ассоциативного массива смежности.
Итак, пусть у нас имеется невзвешенный граф, для каждого ребра которого необходимо хранить, например, 2 дополнительных признака, задаваемых целыми числами. В этом случае возможно задать его вектор смежности как упорядоченный набор не «пар», а «квартетов» целых чисел (а[2i], a[2i+1], a[2i+2], a[2i+3]. ), где a[2i+2] и a[2i+3] и будут определять признаки соответствующего ребра. Для графа же с целыми весами ребер порядок, в целом, аналогичен (отличием будет являться лишь то обстоятельство, что признаки будут следовать после веса ребра и задаваться элементами a[2i+3] и a[2i+4], а само ребро будет задаваться не 4-мя, а 5-ю упорядоченными числами). А для графа с нецелочисленными весами ребер признаки можно будет записать в его невзвешенный компонент.
При использовании ассоциативного массива смежности для графов с целочисленными весами ребер возможно в качестве значения задавать не отдельное число, а массив (вектор) чисел, задающих, помимо веса ребра, все его прочие необходимые признаки. При этом неудобством для случая нецелочисленных весов будет являться необходимость задания признака числом с плавающей запятой (да, это неудобство, но если таких признаков не так и много, и если не задавать их слишком «хитрыми» double, то оно, может, и ничего). И значит, в C++ расширенные ассоциативные массивы смежности могут задаваться следующим образом: std::map , std::vector > или std::map , std::vector >, при этом первым значением в «векторе-значении-по-ключу» будет вес ребра, а далее располагаются численные обозначения его признаков.
Источник



