
Информатика. Шпаргалка

Понятие «информатика» (от лат. – «осведомленность в чем-либо» появилось в середине XX в. во Франции. Термин образовался посредством объединения слов «информация» (information) и «автоматика» (automatique) и в переводе на русский язык означает «автоматизированная обработка информация»; возник, чтобы определить область знании, которая занимается обработкой информации с использованием ЭВМ. Другими словами, информатика является наукой о компьютерной технике.
Оглавление
- Предмет информатики
- Данные и информация. Свойства информации
- Информатизация общества и поколения ЭВМ
- Функциональная структура и принцип работы ЦВМ
- База знаний, экспертные системы
- Данные и их кодирование. Кодирование числовых данных
- Кодирование текстовых данных
- Кодирование графических данных
Приведённый ознакомительный фрагмент книги Информатика. Шпаргалка предоставлен нашим книжным партнёром — компанией ЛитРес.
Данные и их кодирование. Кодирование числовых данных
Кодирование данных используется для изменения названия конкретного объекта на условное обозначение для удобства обработки данных.
Под системой кодирования понимается обобщение правил кодирования объектов. Код образуется на основе алфавита, который включает в себя буквы, цифры и прочие элементы. Алфавит — это конечный набор символов любой природы.
Код определяется структурой (способом расположения в коде символов для обозначения признака) и длиной (количество пунктов или позиций в коде).
Кодирование — это процесс присвоения предмету или объекту кода.
В системе кодирования используются следующие методы:
1) методы классификационной системы кодирования;
2) методы регистрационной системы кодирования.
Первая группа методов проводит предварительную классификацию объектов.
Вторая группа методов не проводит и не требует проведения предварительной классификации.
После осуществления классификации объектов используется классификационное кодирование, разновидностями которого являются параллельное и последовательное кодирование.
При параллельном кодировании для значений фасет, кодируемых независимо друг от друга, выделяют четко определенное количество разрядов кода. Параллельное кодирование трудно произвести, так как нужно учесть много различных признаков объекта.
Последовательное кодирование применяется для ступенчатой структуры классификации. Этот метод используется так: коды группировок записываются «по старшинству», или по иерархии, сначала 1-й, потом 2-й и т. д. В итоге получаем кодовую комбинацию. Отдельный разряд кодовой комбинации информирует пользователя об отличительных чертах определенной группы на каждом отдельном уровне ступенчатой (или иерархической) структуры. Отрицательными моментами при применении этого метода являются следующие: во-первых, если заранее не предусмотреть сочетания признаков, то нельзя группировать объекты, а во-вторых, очень проблематично внести изменения, так как имеется четкая иерархическая структура. Но главным плюсом можно считать простоту и удобство построения и применения.
Чтобы осуществить регистрационное кодирование, предварительная классификация объектов не нужна. Регистрационное кодирование делится на два вида: серийно-порядковое и порядковое.
Для проведения серийно-порядкового кодирования необходимо для начала выделить группы объектов, составляющих серию, затем пронумеровать по порядку объекты каждой серии. Эту систему применяют, когда имеется небольшое количество групп.
При порядковом кодировании объекты последовательно нумеруют. Порядок нумерации можно определять как после упорядочения объектов, так и случайно. Этот метод также применяется при умеренном количестве объектов.
Источник
Методы кодирования данных
Кодирование — это процесс преобразования данных или заданной последовательности символов, символов, алфавитов и т. Д. В определенный формат для защищенной передачи данных. Декодирование — это обратный процесс кодирования, который заключается в извлечении информации из преобразованного формата.
Кодировка данных
Кодирование — это процесс использования различных комбинаций уровней напряжения или тока для представления единиц и нулей цифровых сигналов в линии передачи.
Распространенными типами кодирования линий являются униполярный, полярный, биполярный и манчестерский.
Методы кодирования
Метод кодирования данных подразделяется на следующие типы в зависимости от типа преобразования данных.
Аналоговые данные для аналоговых сигналов. К этой категории относятся методы модуляции, такие как амплитудная модуляция, частотная модуляция и фазовая модуляция аналоговых сигналов.
Аналоговые данные для цифровых сигналов. Этот процесс можно назвать оцифровкой, которая осуществляется с помощью импульсной кодовой модуляции (PCM). Следовательно, это не что иное, как цифровая модуляция. Как мы уже обсуждали, выборка и квантование являются важными факторами в этом. Дельта-модуляция дает лучшую производительность, чем PCM.
Цифровые данные в аналоговые сигналы . Методы модуляции, такие как амплитудная манипуляция (ASK), частотная манипуляция (FSK), фазовая манипуляция (PSK) и т. Д., Подпадают под эту категорию. Они будут обсуждаться в последующих главах.
Цифровые данные в цифровые сигналы — это в этом разделе. Есть несколько способов отобразить цифровые данные на цифровые сигналы. Некоторые из них —
Аналоговые данные для аналоговых сигналов. К этой категории относятся методы модуляции, такие как амплитудная модуляция, частотная модуляция и фазовая модуляция аналоговых сигналов.
Аналоговые данные для цифровых сигналов. Этот процесс можно назвать оцифровкой, которая осуществляется с помощью импульсной кодовой модуляции (PCM). Следовательно, это не что иное, как цифровая модуляция. Как мы уже обсуждали, выборка и квантование являются важными факторами в этом. Дельта-модуляция дает лучшую производительность, чем PCM.
Цифровые данные в аналоговые сигналы . Методы модуляции, такие как амплитудная манипуляция (ASK), частотная манипуляция (FSK), фазовая манипуляция (PSK) и т. Д., Подпадают под эту категорию. Они будут обсуждаться в последующих главах.
Цифровые данные в цифровые сигналы — это в этом разделе. Есть несколько способов отобразить цифровые данные на цифровые сигналы. Некоторые из них —
Невозврат в ноль (NRZ)
Коды NRZ имеют 1 для высокого уровня напряжения и 0 для низкого уровня напряжения. Основное поведение кодов NRZ состоит в том, что уровень напряжения остается постоянным в течение битового интервала. Конец или начало бита не будут указываться, и он будет поддерживать одно и то же состояние напряжения, если значение предыдущего бита и значение текущего бита совпадают.
На следующем рисунке поясняется концепция кодирования NRZ.
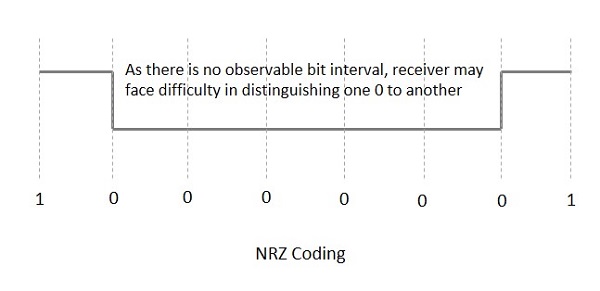
Если рассмотрен вышеприведенный пример, поскольку имеется длинная последовательность постоянного уровня напряжения, и тактовая синхронизация может быть потеряна из-за отсутствия битового интервала, приемнику становится трудно различать 0 и 1.
Источник
Курсовая работа: Форматы данных, представление и кодирование информации в компьютере

Тема: Форматы данных, представление и кодирование информации в компьютере
Тип: Курсовая работа | Размер: 441.81K | Скачано: 182 | Добавлен 15.10.13 в 23:02 | Рейтинг: 0 | Еще Курсовые работы
Вуз: Финансовый университет
Содержание
1. Теоретическая часть
1.1. Форматы данных 4
1.2. Представление информации в компьютере 4
1.2.1. Компьютерное кодирование текста 5
1.2.2. Компьютерное кодирование графики 7
1.2.3. Компьютерное кодирование звука 9
2. Практическая часть
2.1. Постановка задачи
2.1.1. Цель решения задачи 12
2.1.2. Условие задачи 12
2.2. Компьютерная модель решения задачи
2.2.1. Информационная модель решения задачи 13
2.2.2. Аналитическая модель решения задачи 14
2.2.3. Технология решения задачи 14
2.3. Результаты компьютерного эксперимента и их анализ
2.3.1. Результаты компьютерного эксперимента 22
2.3.2. Анализ полученных результатов 23
Список использованной литературы 25
Введение
Актуальность темы в том, что вычислительная техника первоначально возникла как средство автоматизации вычислений. Следующим видом обрабатываемой информации стала текстовая. Сначала тексты просто поясняли труднообозримые столбики цифр, но затем машины все более существенным образом стали преобразовывать текстовую информацию. Оформление текстов достаточно быстро вызвали у людей стремление дополнить их графиками и рисунками. Делались попытки частично решить эти проблемы в рамках символьного подхода: вводились специальные символы для рисования таблиц и диаграммам. Но практические потребности людей в графике делали ее появление среди видов компьютерной информации неизбежной. Числа, тексты и графика образовали некоторый относительно замкнутый набор, которого было достаточно для многих решаемых на компьютере задачи. Постоянный рост быстродействия вычислительной техники создал широкие технические возможности для обработки звуковой информации, а также для быстро сменяющихся изображений. Все это обусловило и развитие способов представления и кодирования различных видов информации в компьютере.
Объектом изучения, представленным в теоретической части являются данные в компьютере.
Цель работы – рассмотреть форматы данных их представление и кодирование в компьютере.
Для достижения цели необходимо решить следующие задачи:
- Рассмотреть существующие форматы данных;
- Рассмотреть представление различных типов данных в компьютере и описать способы кодирования информации.
Задача, поставленная в практической части — это расчет платежей клиента по кредиту, будет решаться в программной среде MS Excel. Цель решения данной задачи состоит в определении сумм погашения кредита по месяцам для отслеживания своевременности и точности выплат клиента банку.
1. Теоретическая часть
1.1 Форматы данных
Информация – это сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состояниях, которые уменьшают имеющуюся о них степень неопределенности, неполноты знаний.
В процессе обработки информация может менять структуру и форму. Признаком структуры являются элементы информации и их взаимосвязь. Формы представления информации могут быть различны. Основными из них являются: символьная; текстовая; графическая; световых или звуковых сигналов; радиоволн; электрических и нервных импульсов; магнитных записей; жестов и мимики; запахов и вкусовых ощущений и так далее.
В повседневной практике такие понятия, как информация и данные, часто рассматриваются как синонимы. На самом деле между ними имеются существенные различия.
Данными называется информация, представленная в удобном для обработки виде. Данные могут быть представлены в виде текста, графики, аудиовизуального ряда. Представление данных называется языком информатики, представляющим собой совокупность символов, соглашений и правил, используемых для общения, отображения, передачи информации в электронном виде.
1.2. Представление информации в компьютере
Люди имеют дело со многими видами информации. Услышав прогноз погоды, можно записать его в компьютер, чтобы затем воспользоваться им. В компьютер можно поместить фотографию своего друга или видеосъемку о том как вы провели каникулы. Но ввести в компьютер вкус мороженого или мягкость покрывала никак нельзя.
Компьютер — это электронная машина, которая работает с сигналами. Компьютер может работать только с такой информацией, которую можно превратить в сигналы. Если бы люди умели превращать в сигналы вкус или запах, то компьютер мог бы работать и с такой информацией. У компьютера очень хорошо получается работать с числами. Он может делать с ними все, что угодно. Все числа в компьютере закодированы «двоичным кодом», то есть представлены с помощью всего двух символов 1 и 0, которые легко представляются сигналами.
Вся информация с которой работает компьютер кодируется числами. Независимо от того, графическая, текстовая или звуковая эта информация, что бы ее мог обрабатывать центральный процессор она должна тем или иным образом быть представлена числами. Поэтому для преобразования числовой, текстовой, графической, звуковой информации в цифровую необходимо применить кодирование. Кодирование – это преобразование данных одного типа через данные другого типа. А в ЭВМ применяется система двоичного кодирования, основанная на представлении данных последовательностью двух знаков: 1 и 0, которые называются двоичными цифрами (binary digit – сокращенно bit).
1.2.1. Компьютерное кодирование текста
Множество символов, используемых при записи текста, называется алфавитом. Количество символов в алфавите называется его мощностью.
Для представления текстовой информации в компьютере чаще всего используется алфавит мощностью 256 символов. Один символ из такого алфавита несет 8 бит информации, т. к. 28 = 256. Но 8 бит составляют один байт, следовательно, двоичный код каждого символа занимает 1 байт памяти ЭВМ. Все символы такого алфавита пронумерованы от 0 до 255, а каждому номеру соответствует 8-разрядный двоичный код от 00000000 до 11111111. Этот код является порядковым номером символа в двоичной системе счисления.
Для разных типов ЭВМ и операционных систем используются различные таблицы кодировки, отличающиеся порядком размещения символов алфавита в кодовой таблице. Международным стандартом на персональных компьютерах является таблица кодировки ASCII.
Принцип последовательного кодирования алфавита заключается в том, что в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений.
Стандартными в этой таблице являются только первые 128 символов, т. е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная со 128 (двоичный код 10000000) и кончая 255 (11111111), используются для кодировки букв национальных алфавитов, символов псевдографики и научных символов.
Сейчас существует несколько различных кодовых таблиц для русских букв (КОИ-8, СР-1251, СР-866, Mac, ISO), причем тексты, созданные в одной кодировке, могут неправильно отображаться в другой. Решается такая проблема с помощью специальных программ перевода текста из одной кодировки в другую. В операционной системе Windows пришлось передвинуть русские буквы в таблице на место псевдографики, и получили кодировку Windows 1251 (Win-1251).
В течение долгого времени понятия «байт» и «символ» были почти синонимами. Однако, в конце концов, стало ясно, что 256 различных символов — это не так много. Математикам требуется использовать в формулах специальные математические знаки, переводчикам необходимо создавать тексты, где могут встретиться символы из различных алфавитов, экономистам необходимы символы валют ($, £, ¥). Для решения этой проблемы была разработана универсальная система кодирования текстовой информации — Unicode. В этой кодировке для каждого символа отводится не один, а два байта, т.е. шестнадцать бит. Таким образом, доступно 65536 (216) различных кодов. Этого хватит на латинский алфавит, кириллицу, иврит, африканские и азиатские языки, различные специализированные символы: математические, экономические, технические и многое другое. Главный недостаток Unicode состоит в том, что все тексты в этой кодировке становятся в два раза длиннее. В настоящее время стандарты ASCII и Unicode мирно сосуществуют.
1.2.2. Компьютерное кодирование графики
Графический формат — это способ записи графической информации. Графические форматы файлов предназначены для хранения изображений, таких как фотографии и рисунки.
Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части — растровую и векторную графику.
Для представления графической информации растровым способом используется так называемый точечный подход. На первом этапе вертикальными и горизонтальными линиями делят изображение. Чем больше при этом получилось элементов (пикселей), тем точнее будет передана информация об изображении.
Как известно из физики, любой цвет может быть представлен в виде суммы различной яркости красного, зеленого и синего цветов. Поэтому надо закодировать информацию о яркости каждого из трех цветов для отображения каждого пикселя. В видеопамяти находится двоичная информация об изображении, выводимом на экран.
Таким образом, растровые изображения представляют собой однослойную сетку точек, называемых пикселями (pixel, от англ. picture element), а код пикселя содержит информацию о его цвете.
Для черно-белого изображения (без полутонов) пиксель может принимать только два значения: белый и черный (светится — не светится), а для его кодирования достаточно одного бита памяти: 1 — белый, 0 — черный.
Пиксель на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксель недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксель, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 — черный, 10 — зеленый, 01 — красный, 11 — коричневый.
На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов: красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций (Таблица 1):
Источник



