III. Закрепление полученных знаний. Формирование умений строить предложения с разными видами связи, совершенствование пунктуационных навыков.
III. Пути и способы самосовершенствования компетентной и конкурентоспособной личности
IV. Контроль знаний.
IV. Проверка знаний студентов
Представление знаний— это соглашение о том, как описывать реальный мир. В естественных и технических науках принят следующий традиционный способ представления знаний. На естественном языке вводятся основные понятия и отношения между ними. При этом используются ранее определенные понятия и отношения, смысл которых уже известен. Далее устанавливается соответствие между характеристиками (чаще всего количественными) понятий знания и подходящей математической модели.
Основная цель представления знаний — строить математические моделиреального мира и его частей, для которых соответствие между системой понятий проблемного знания может быть установлено на основе совпадения имен переменных модели и имен понятий без предварительных пояснений и установления дополнительных неформальных соответствий.
Представление знаний обычно выполняется в рамках той или иной системы представления знаний.
Системой представления знаний (СПЗ) называют средства, позволяющие описывать знания о предметной области с помощью языка представления знаний, организовывать хранение знаний в системе (накопление, анализ, обобщение и организация структурированности знаний), вводить новые знания и объединять их с имеющимися, выводить новые знания из имеющихся, находить требуемые знания, устранять устаревшие знания, проверять непротиворечивость накопленных знаний, осуществлять интерфейс между пользователем и знаниями.
Центральное место в СПЗ занимает язык представления знаний (ЯПЗ). В свою очередь, выразительные возможности ЯПЗ определяются лежащей в основе ЯПЗ моделью представления знаний (иногда эти понятия отождествляют).
Модель представления знаний является формализмом, призванным отобразить статические и динамические свойства предметной области, т. е. отобразить объекты и отношения предметной области, связи между ними, иерархию понятий предметной области и изменение отношений между объектами. Модель представления знаний может быть универсальной (применимой для большинства предметных областей) или специализированной (разработанной для конкретной предметной области).
Используются следующие основные универсальные модели представления знаний:
· семантические сети;
· фреймы;
· продукционные системы;
· логические модели и другие.
Во всех разработанных системах с базами знаний кроме этих моделей, взятых за основу, использовались специальные дополнительные средства. Тем не менее, классификация моделей представления знаний остается неизменной.
Семантические сети(СС) являются исторически первым классом моделей представления знаний. Здесь структура знаний предметной области формализуется в виде ориентированного графа с размеченными вершинами и дугами.
Вершины обозначают сущности и понятия ПО, а дуги — отношения между ними.
Под сущностью понимают объект произвольной природы. Вершины и дуги могут снабжаться метками, представляющим собой мнемонические имена. Основными связями для СС, с помощью которых формируются понятия, являются:
· класс, к которому принадлежит данное понятие;
· свойства, выделяющие понятие из всех прочих понятий этого класса;
Рис.1. Пример фрагмента семантической сети
С помощью СС можно описывать события и действия.
Для этих целей используются специальные типы отношений, называемые падежами:
· агент — действующее лицо, вызывающее действие;
· объект — предмет, подвергающийся действию;
· адресат— лицо, пользующееся результатом действия или испытывающее этот результат.
Возможны и другие падежи типа:
· количество и т.д.
Введение падежей позволяет от поверхностной структуры предложения перейти к его смысловому содержанию. В СС понятийная структура и система зависимостей представлены однородно. Поэтому представление в них, например, математических соотношений графическими средствами неэффективно.
СС не дают ясного представления о структуре ПО, они представляют собой пассивные структуры, для обработки которых необходима разработка аппарата формального вывода и планирования.
В чистом виде СС на практике почти не используются.
При построении СИИ с использованием СС обычно либо накладывают ограничения на типы объектов и отношений (примером таких сетей являются функциональные СС), либо расширяют СС специальными средствами для более эффективной организации вычислений в СС (К-сети, пирамидальные сети и др.).
Фреймы
Метод представления знаний с помощью фреймов предложен М. Минским.
Фрейм— это структура, предназначенная для представления стереотипной ситуации. Каждый фрейм описывает один концептуальный объект, а конкретные свойства этого объекта и факты, относящиеся к нему, описываются в словах — структурных элементах данного фрейма. Все фреймы взаимосвязаны и образуют единую фреймовую систему, в которой объединены и процедурные знания. Концептуальному представлению свойственна иерархичность, целостный образ знаний строится в виде единой фреймовой системы, имеющей иерархическую структуру. В слот можно подставить разные данные: числа или математические соотношения, тексты, программы, правила вывода или ссылки на другие слоты данного или других фреймов. Фреймопределяется как структура следующего вида: (ИМЯ ФРЕЙМА; ИМЯ СЛОТА1 (ЗНАЧЕНИЕ СЛОТА1) ИМЯ СЛОТА2 (ЗНАЧЕНИЕ СЛОТА2) ИМЯ CЛOTAN (ЗНАЧЕНИЕ CЛOTAN)) Определим, например, фрейм для объекта «Служащий»: (Служащий ФИО (Петров И. П.) Должность(инженер) Категория(2) ……………………… )). .
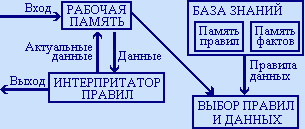
Продукционные системы — это системы представления знаний, основанные на правилах типа «УСЛОВИЕ-ДЕЙСТВИЕ». Записываются эти правила обычно в виде ЕСЛИ А1,А2.. Аn ТО В. Такая запись означает, что «если выполняются все условия от А1, до Аn (являются истинными), тогда следует выполнить действие В». Часть правила после ЕСЛИ называется посылкой, а часть правила после ТО — выводом, или действием, или заключением. Условия А],А2. Аn обычно называют фактами. С помощью фактов описывается текущее состояние предметной области. Факты могут быть истинными, ложными либо, в общем случае, правдоподобными, когда истинность факта допускается с некоторой степенью уверенности. Действие В трактуется как добавление нового факта в описание текущего состояния предметной области. Факты — это истинные высказывания (в естественном языке — это повествовательные предложения) об объектах или явлениях предметной области. Правила описывают причинно-следственные связи между фактами (в общем случае и между правилами тоже) — как истинность одних фактов влияет на истинность других.
Рис.2. Структура продукционной системы
В продукционных системах используются два основных способа реализации механизма вывода:
· прямой вывод, или вывод от данных;
· обратный вывод, или вывод от цели.
В первом случае идут от известных данных (фактов) и на каждом шаге вывода к этим фактам применяют все возможные правила, которые порождают новые факты, и так до тех пор, пока не будет порожден факт-цель. Рабочая память представляет собой информационную структуру для хранения текущего состояния предметной области.
Обмен информацией в продукционной системе осуществляется через рабочую память. К примеру, из одного правила нельзя переслать какие-либо данные непосредственно в другое правило, минуя рабочую память. Состояние рабочей памяти целиком определяет подмножество применимых на каждом шаге вывода правил.
Например, возможная формулировка правил продукций в экспертной системе диагностики автомобиля имеет следующий вид:
Если (горит_лампа_датчика_давления_масла И уровень_масла_норма и обороты_двигателя_норма и масляный фильтр_не_засорен) То (проверить масляный насос)
Приведенное правило позволяет принять решение по ремонту системы смазки автомобиля. Достоинством применения правил продукций является их модульность. Это позволяет легко добавлять и удалять знания в базе знаний. Можно изменять любую из продукций, не затрагивая содержимого других продукций. Недостатки продукционных систем проявляются при большом числе правил и связаны с возникновением непредсказуемых побочных эффектов при изменении старых и добавлении новых правил. Кроме того, отмечают также низкую эффективность обработки систем продукций и отсутствие гибкости в логическом выводе.
Дата добавления: 2015-07-25 ; просмотров: 453 | Нарушение авторских прав
Источник
Глава 1. Способы формального представления знаний
Содержание
Глава 1. Способы формального представления знаний. 4
1.1 История в информатике. 4
1.2 Связи и структуры. 5
1.3 Язык и нотация. 7
Глава 2. Модели представления знаний. Неформальные (семантические) модели. 9
2.1 Методы представления знаний. 9
2.2 Формальные модели представления знаний. 12
2.3 Представление знаний в виде правил. 14
2.4 Представление знаний с использованием фреймов. 15
2.5 Представление знаний с использованием семантических сетей 17
2.6 Представление знаний в виде нечетких высказываний. 18
Введение
Представление знаний — вопрос, возникающий в когнитологии (науке о мышлении), в информатике и в искусственном интеллекте. В когнитологии он связан с тем, как люди хранят и обрабатывают информацию. В информатике — основная цель — подбор представления конкретных и обобщенных знаний, сведений и фактов для накопления и осмысленной обработки информации в ЭВМ.
В Искусственном интеллекте (ИИ) основная цель — научиться хранить знания таким образом, чтобы программы могли обрабатывать их и достигнуть подобия человеческого интеллекта. Исследователи ИИ используют теории представления знаний из когнитологии. Такие методы как фреймы, правила, и семантические сети пришли в ИИ из теорий обработки информации человеком. Так как знание используется для достижения разумного поведения, фундаментальной целью дисциплины представления знаний является поиск таких способов представления, которые делают возможным процесс логического вывода, то есть создание выводов из знаний.
Некоторые вопросы, которые возникают в представлении знаний с точки зрения ИИ:
Как люди представляют знания?
Какова природа знаний и как мы их представляем?
Должна ли схема представления связываться с частной областью знаний, или она должна быть общецелевой?
Должна ли быть схема декларативной или процедурной?
Попытаемся дать ответы на эти вопросы в данной контрольной работе.
Глава 1. Способы формального представления знаний
История в информатике
В информатике (главным образом в области искусственного интеллекта) для структурирования информации, а также организации баз знаний и экспертных систем были предложены несколько способов представления знаний. Одно из них представление данных и сведений в рамках логической модели баз знаний, на основе языка логического программирования Пролог.
Под термином «Представление Знаний» чаще всего подразумеваются способы представления знаний, ориентированные на автоматическую обработку современными компьютерами, и в частности, представления, состоящие из явных объектов (‘класс всех слонов’, или ‘Клайд — экземпляр’), и из суждений или утверждений о них (‘Клайд слон’, или ‘все слоны серые’). Представление знаний в подобной явной форме позволяет компьютерам делать дедуктивные выводы из ранее сохраненного знания (‘Клайд серый’).
В 1970-х и начале 1980-х были предложены, и с переменным успехом опробованы многочисленные методы представления знаний, например эвристические вопросно-ответные системы, нейросети, доказательство теорем, и экспертные системы. Главными областями их применения в то время были медицинская диагностика (к примеру Мицин) и игры (например шахматы).
В 1980-х годах появились формальные компьютерные языки представления знаний. Основные проекты того времени пытались закодировать (занести в свои базы знаний) огромные массивы общечеловеческого знания. Например в проекте «Cyc» была обработана большая энциклопедия, и кодировалась не сама хранящаяся в ней информация, а знания, которые потребуются читателю чтобы понять эту энциклопедию: наивная физика, понятия времени, причинности и мотивации, типичные объекты и их классы. Проект Cyc развивается компанией Cycorp, Inc.; большая часть (но не вся) их базы свободно доступна.
Эта работа привела к более точной оценке сложности задачи представления знаний. Одновременно в математической лингвистике, были созданы гораздо более объёмные базы языковой информации, и они, вместе с огромным приростом скорости и объёмов памяти компьютеров сделали более глубокое представление знаний более реальным.
Было разработано несколько языков программирования ориентированных на представление знаний. Пролог, разработанный в 1972 (см. http://www.aaai.org/AITopics/bbhist.html#mod), но получивший популярность значительно позже, описывает высказывания и основную логику, и может производить выводы из известных посылок. Ещё больше нацелен на представление знаний язык KL-ONE (1980-е).
В области электронных документов были разработаны языки явно выражающие структуру хранимых документов, такие как SGML а впоследствии XML. Они облегчили задачи поиска и извлечения информации, которые в последнее время всё больше связаны с задачей представления знаний. Веб-сообщество крайне заинтересованно в семантической паутине, в которой основанные на XML языки представления знаний, такие как RDF, Карта тем и другие используются для увеличения доступности компьютерным системам информации, хранящейся в сети.
Связи и структуры
Одной из проблем в представлении знаний является как хранить и обрабатывать знания в информационных системах формальным способом так, чтобы механизмы могли использовать их для достижения поставленных задач. Примеры применения здесь экспертные системы, Машинный перевод, компьютеризированное техническое обслуживание и системы извлечения и поиска информации (включая пользовательские интерфейсы баз данных).
Для представления знаний можно использовать семантические сети. Каждый узел такой сети представляет концепцию, а дуги используются для определения отношений между концепциями. Одна из самых выразительных и детально описанных парадигм представления знаний основанных на семантических сетях это MultiNet (акроним для Многослойные Расширенные Семантические Сети англ. Multilayered Extended Semantic Networks).
Начиная с 1960-х годов, использовалось понятие фрейма знаний или просто фрейма. Каждый фрейм имеет своё собственное имя и набор атрибутов, или слотов которые содержат значения; например фрейм дом мог бы содержать слоты цвет, количество этажей и так далее.
Использование фреймов в экспертных системах является примером объектно-ориентированного программирования, с наследованием свойств, которое описывается связью «is-a». Однако, в использовании связи «is-a» существовало немало противоречий: Рональд Брахман написал работу озаглавленную «Чем является и не является IS-A», в которой были найдены 29 различных семантик связи «is-a» в проектах, чьи схемы представления знаний включали связь «is-a». Другие связи включают, например, «has-part».
Фреймовые структуры хорошо подходят для представления знаний, представленных в виде схем и стереотипных когнитивных паттернов. Элементы подобных паттернов обладают разными весами, причем большие весы назначаются тем элементам, которые соответствую текущей когнитивной схеме (schema). Паттерн активизируется при определённых условиях: Если человек видит большую птицу, при условии что сейчас активна его «морская схема», а «земная схема» — нет, он классифицирует её скорее как морского орлана, а не сухопутного беркута.
Фреймовые представления объектно-центрированы в том же смысле что и Семантическая сеть: Все факты и свойства, связанные с одной концепцией, размещаются в одном месте, поэтому не требуется тратить ресурсы на поиск по базе данных.
Скрипт это тип фреймов, который описывает последовательность событий во времени; типичный пример описание похода в ресторан. События здесь включают ожидание места, прочитать меню, сделать заказ, и так далее.
Различные решения в зависимости от их семантической выразительности могут быть организованы в так называемый семантический спектр (англ. Semantic spectrum).
Язык и нотация
Некоторые люди считают, что лучше всего будет представлять знания также как они представлены в человеческом разуме, который является единственным известным на сегодняшний день работающим разумом, или же представлять знания в форме естественного языка. Доктор Ричард Баллард, например, разработал «семантическую систему, базирующуюся на теории», которая не зависит от языка, которая выводит цель и рассуждает теми же концепциями и теориями что и люди. Формула, лежащая в основе этой семантики: Знание=Теория+Информация. Большинство распространенных приложений и систем баз данных основаны на языках. К несчастью, мы не знаем как знания представляются в человеческом разуме, или как манипулировать естественными языками также как это делает человек. Одной из подсказок является то, что приматы знают как использовать интерфейсы пользователя point and click; таким образом интерфейс жестов похоже является частью нашего когнитивного аппарата, модальность которая не привязана к устному языку, и которая существует в других животных кроме человека.
Поэтому для представления знаний были предложены различные искусственные языки и нотации. Обычно они основаны на логике и математике, и имеют легко читаемую грамматику для облегчения машинной обработки. Обычно они попадают в широкую область онтологий.
Последней модой в языках представления знаний является использование XML в качестве низкоуровневого синтаксиса. Это приводит к тому, что вывод этих языков представления знаний машины могут легко Синтаксический анализ, за счёт Удобочитаемости для человека. Логика первого порядка и язык Пролог широко используется в качестве математической основы для этих систем, чтобы избежать избыточной сложности. Однако даже простые системы основанные на этой простой логике можно использовать для представления данных которое значительно лучше возможностей обработки для нынешних компьютерных систем: причины раскрываются в теории вычислимости.
DATR является примером представления лексических знаний
RDF является простой Нотация для представления отношений между и среди объектов
Примеры искусственных языков которые используются преимущественно для представления знаний:
KM: Машина Знаний (англ. Knowledge Machine) (фреймовый язык, использовавшийся для задач представления знаний)
Методы представления знаний
Существуют два типа методов представления знаний (ПЗ):
Формальные модели ПЗ;
Неформальные (семантические, реляционные) модели ПЗ.
Очевидно, все методы представления знаний, которые рассмотрены выше, включая продукции (это система правил, на которых основана продукционная модель представления знаний), относятся к неформальным моделям. В отличие от формальных моделей, в основе которых лежит строгая математическая теория, неформальные модели такой теории не придерживаются. Каждая неформальная модель годится только для конкретной предметной области и поэтому не обладает универсальностью, которая присуща моделям формальным. Логический вывод — основная операция в СИИ — в формальных системах строг и корректен, поскольку подчинен жестким аксиоматическим правилам. Вывод в неформальных системах во многом определяется самим исследователем, который и отвечает за его корректность.
Каждому из методов ПЗ соответствует свой способ описания знаний.
1. Логические модели. В основе моделей такого типа лежит формальная система, задаваемая четверкой вида: M = . Множество T есть множество базовых элементов различной природы, например слов из некоторого ограниченного словаря, деталей детского конструктора, входящих в состав некоторого набора и т.п. Важно, что для множества T существует некоторый способ определения принадлежности или непринадлежности произвольного элемента к этому множеству. Процедура такой проверки может быть любой, но за конечное число шагов она должна давать положительный или отрицательный ответ на вопрос, является ли x элементом множества T. Обозначим эту процедуру П(T).
Множество P есть множество синтаксических правил. С их помощью из элементов T образуют синтаксически правильные совокупности. Например, из слов ограниченного словаря строятся синтаксически правильные фразы, из деталей детского конструктора с помощью гаек и болтов собираются новые конструкции. Декларируется существование процедуры П(P), с помощью которой за конечное число шагов можно получить ответ на вопрос, является ли совокупность X синтаксически правильной.
В множестве синтаксически правильных совокупностей выделяется некоторое подмножество A. Элементы A называются аксиомами. Как и для других составляющих формальной системы, должна существовать процедура П(A), с помощью которой для любой синтаксически правильной совокупности можно получить ответ на вопрос о принадлежности ее к множеству A.
Множество B есть множество правил вывода. Применяя их к элементам A, можно получать новые синтаксически правильные совокупности, к которым снова можно применять правила из B. Так формируется множество выводимых в данной формальной системе совокупностей. Если имеется процедура П(B), с помощью которой можно определить для любой синтаксически правильной совокупности, является ли она выводимой, то соответствующая формальная система называется разрешимой. Это показывает, что именно правило вывода является наиболее сложной составляющей формальной системы.
Для знаний, входящих в базу знаний, можно считать, что множество A образуют все информационные единицы, которые введены в базу знаний извне, а с помощью правил вывода из них выводятся новые производные знания. Другими словами формальная система представляет собой генератор порождения новых знаний, образующих множество выводимых в данной системе знаний. Это свойство логических моделей делает их притягательными для использования в базах знаний. Оно позволяет хранить в базе лишь те знания, которые образуют множество A, а все остальные знания получать из них по правилам вывода.
2. Сетевые модели. В основе моделей этого типа лежит конструкция, названная ранее семантической сетью. Сетевые модели формально можно задать в виде H = . Здесь I есть множество информационных единиц; C1, C2. Cn — множество типов связей между информационными единицами. Отображение Г задает между информационными единицами, входящими в I, связи из заданного набора типов связей.
В зависимости от типов связей, используемых в модели, различают классифицирующие сети, функциональные сети и сценарии. В классифицирующих сетях используются отношения структуризации. Такие сети позволяют в базах знаний вводить разные иерархические отношения между информационными единицами. Функциональные сети характеризуются наличием функциональных отношений. Их часто называют вычислительными моделями, т.к они позволяют описывать процедуры «вычислений» одних информационных единиц через другие. В сценариях используются каузальные отношения, а также отношения типов «средство — результат», «орудие — действие» и т.п. Если в сетевой модели допускаются связи различного типа, то ее обычно называют семантической сетью.
3. Продукционные модели. В моделях этого типа используются некоторые элементы логических и сетевых моделей. Из логических моделей заимствована идея правил вывода, которые здесь называются продукциями, а из сетевых моделей — описание знаний в виде семантической сети. В результате применения правил вывода к фрагментам сетевого описания происходит трансформация семантической сети за счет смены ее фрагментов, наращивания сети и исключения из нее ненужных фрагментов. Таким образом, в продукционных моделях процедурная информация явно выделена и описывается иными средствами, чем декларативная информация. Вместо логического вывода, характерного для логических моделей, в продукционных моделях появляется вывод на знаниях.
4. Фреймовые модели. В отличие от моделей других типов во фреймовых моделях фиксируется жесткая структура информационных единиц, которая называется протофреймом. В общем виде она выглядит следующим образом:
Имя слота 1(значение слота 1)
Имя слота 2(значение слота 2)
Имя слота К (значение слота К)).
Значением слота может быть практически что угодно (числа или математические соотношения, тексты на естественном языке или программы, правила вывода или ссылки на другие слоты данного фрейма или других фреймов). В качестве значения слота может выступать набор слотов более низкого уровня, что позволяет во фреймовых представлениях реализовать «принцип матрешки».
При конкретизации фрейма ему и слотам присваиваются конкретные имена и происходит заполнение слотов. Таким образом, из протофреймов получаются фреймы — экземпляры. Переход от исходного протофрейма к фрейму — экземпляру может быть многошаговым, за счет постепенного уточнения значений слотов.
Заключение
В заключении хочется сказать, что было очень немного top-down обсуждения вопросов представления знаний и исследования в данной области is a well aged quiltwork. Есть хорошо известные проблемы, такие как «spreading activation, « (задача навигации в сети узлов)»категоризация» (это связано с выборочным наследованием; например вездеход можно считать специализацией (особым случаем) автомобиля, но он наследует только некоторые характеристики) и «классификация». Например помидор можно считать как фруктом, так и овощем.
В области искусственного интеллекта, решение задач может быть упрощено правильным выбором метода представления знаний. Определенный метод может сделать какую-либо область знаний легко представимой. Например диагностическая экспертная система Мицин использовала схему представления знаний основанную на правилах. Неправильный выбор метода представления затрудняет обработку. В качестве аналогии можно взять вычисления в индо-арабской или римской записи. Деление в столбик проще в первом случае и сложнее во втором. Аналогично, не существует такого способа представления, который можно было бы использовать во всех задачах, или сделать все задачи одинаково простыми.
Содержание
Глава 1. Способы формального представления знаний. 4
1.1 История в информатике. 4
1.2 Связи и структуры. 5
1.3 Язык и нотация. 7
Глава 2. Модели представления знаний. Неформальные (семантические) модели. 9
2.1 Методы представления знаний. 9
2.2 Формальные модели представления знаний. 12
2.3 Представление знаний в виде правил. 14
2.4 Представление знаний с использованием фреймов. 15
2.5 Представление знаний с использованием семантических сетей 17
2.6 Представление знаний в виде нечетких высказываний. 18
Введение
Представление знаний — вопрос, возникающий в когнитологии (науке о мышлении), в информатике и в искусственном интеллекте. В когнитологии он связан с тем, как люди хранят и обрабатывают информацию. В информатике — основная цель — подбор представления конкретных и обобщенных знаний, сведений и фактов для накопления и осмысленной обработки информации в ЭВМ.
В Искусственном интеллекте (ИИ) основная цель — научиться хранить знания таким образом, чтобы программы могли обрабатывать их и достигнуть подобия человеческого интеллекта. Исследователи ИИ используют теории представления знаний из когнитологии. Такие методы как фреймы, правила, и семантические сети пришли в ИИ из теорий обработки информации человеком. Так как знание используется для достижения разумного поведения, фундаментальной целью дисциплины представления знаний является поиск таких способов представления, которые делают возможным процесс логического вывода, то есть создание выводов из знаний.
Некоторые вопросы, которые возникают в представлении знаний с точки зрения ИИ:
Как люди представляют знания?
Какова природа знаний и как мы их представляем?
Должна ли схема представления связываться с частной областью знаний, или она должна быть общецелевой?
Должна ли быть схема декларативной или процедурной?
Попытаемся дать ответы на эти вопросы в данной контрольной работе.
Глава 1. Способы формального представления знаний
История в информатике
В информатике (главным образом в области искусственного интеллекта) для структурирования информации, а также организации баз знаний и экспертных систем были предложены несколько способов представления знаний. Одно из них представление данных и сведений в рамках логической модели баз знаний, на основе языка логического программирования Пролог.
Под термином «Представление Знаний» чаще всего подразумеваются способы представления знаний, ориентированные на автоматическую обработку современными компьютерами, и в частности, представления, состоящие из явных объектов (‘класс всех слонов’, или ‘Клайд — экземпляр’), и из суждений или утверждений о них (‘Клайд слон’, или ‘все слоны серые’). Представление знаний в подобной явной форме позволяет компьютерам делать дедуктивные выводы из ранее сохраненного знания (‘Клайд серый’).
В 1970-х и начале 1980-х были предложены, и с переменным успехом опробованы многочисленные методы представления знаний, например эвристические вопросно-ответные системы, нейросети, доказательство теорем, и экспертные системы. Главными областями их применения в то время были медицинская диагностика (к примеру Мицин) и игры (например шахматы).
В 1980-х годах появились формальные компьютерные языки представления знаний. Основные проекты того времени пытались закодировать (занести в свои базы знаний) огромные массивы общечеловеческого знания. Например в проекте «Cyc» была обработана большая энциклопедия, и кодировалась не сама хранящаяся в ней информация, а знания, которые потребуются читателю чтобы понять эту энциклопедию: наивная физика, понятия времени, причинности и мотивации, типичные объекты и их классы. Проект Cyc развивается компанией Cycorp, Inc.; большая часть (но не вся) их базы свободно доступна.
Эта работа привела к более точной оценке сложности задачи представления знаний. Одновременно в математической лингвистике, были созданы гораздо более объёмные базы языковой информации, и они, вместе с огромным приростом скорости и объёмов памяти компьютеров сделали более глубокое представление знаний более реальным.
Было разработано несколько языков программирования ориентированных на представление знаний. Пролог, разработанный в 1972 (см. http://www.aaai.org/AITopics/bbhist.html#mod), но получивший популярность значительно позже, описывает высказывания и основную логику, и может производить выводы из известных посылок. Ещё больше нацелен на представление знаний язык KL-ONE (1980-е).
В области электронных документов были разработаны языки явно выражающие структуру хранимых документов, такие как SGML а впоследствии XML. Они облегчили задачи поиска и извлечения информации, которые в последнее время всё больше связаны с задачей представления знаний. Веб-сообщество крайне заинтересованно в семантической паутине, в которой основанные на XML языки представления знаний, такие как RDF, Карта тем и другие используются для увеличения доступности компьютерным системам информации, хранящейся в сети.
Связи и структуры
Одной из проблем в представлении знаний является как хранить и обрабатывать знания в информационных системах формальным способом так, чтобы механизмы могли использовать их для достижения поставленных задач. Примеры применения здесь экспертные системы, Машинный перевод, компьютеризированное техническое обслуживание и системы извлечения и поиска информации (включая пользовательские интерфейсы баз данных).
Для представления знаний можно использовать семантические сети. Каждый узел такой сети представляет концепцию, а дуги используются для определения отношений между концепциями. Одна из самых выразительных и детально описанных парадигм представления знаний основанных на семантических сетях это MultiNet (акроним для Многослойные Расширенные Семантические Сети англ. Multilayered Extended Semantic Networks).
Начиная с 1960-х годов, использовалось понятие фрейма знаний или просто фрейма. Каждый фрейм имеет своё собственное имя и набор атрибутов, или слотов которые содержат значения; например фрейм дом мог бы содержать слоты цвет, количество этажей и так далее.
Использование фреймов в экспертных системах является примером объектно-ориентированного программирования, с наследованием свойств, которое описывается связью «is-a». Однако, в использовании связи «is-a» существовало немало противоречий: Рональд Брахман написал работу озаглавленную «Чем является и не является IS-A», в которой были найдены 29 различных семантик связи «is-a» в проектах, чьи схемы представления знаний включали связь «is-a». Другие связи включают, например, «has-part».
Фреймовые структуры хорошо подходят для представления знаний, представленных в виде схем и стереотипных когнитивных паттернов. Элементы подобных паттернов обладают разными весами, причем большие весы назначаются тем элементам, которые соответствую текущей когнитивной схеме (schema). Паттерн активизируется при определённых условиях: Если человек видит большую птицу, при условии что сейчас активна его «морская схема», а «земная схема» — нет, он классифицирует её скорее как морского орлана, а не сухопутного беркута.
Фреймовые представления объектно-центрированы в том же смысле что и Семантическая сеть: Все факты и свойства, связанные с одной концепцией, размещаются в одном месте, поэтому не требуется тратить ресурсы на поиск по базе данных.
Скрипт это тип фреймов, который описывает последовательность событий во времени; типичный пример описание похода в ресторан. События здесь включают ожидание места, прочитать меню, сделать заказ, и так далее.
Различные решения в зависимости от их семантической выразительности могут быть организованы в так называемый семантический спектр (англ. Semantic spectrum).
Язык и нотация
Некоторые люди считают, что лучше всего будет представлять знания также как они представлены в человеческом разуме, который является единственным известным на сегодняшний день работающим разумом, или же представлять знания в форме естественного языка. Доктор Ричард Баллард, например, разработал «семантическую систему, базирующуюся на теории», которая не зависит от языка, которая выводит цель и рассуждает теми же концепциями и теориями что и люди. Формула, лежащая в основе этой семантики: Знание=Теория+Информация. Большинство распространенных приложений и систем баз данных основаны на языках. К несчастью, мы не знаем как знания представляются в человеческом разуме, или как манипулировать естественными языками также как это делает человек. Одной из подсказок является то, что приматы знают как использовать интерфейсы пользователя point and click; таким образом интерфейс жестов похоже является частью нашего когнитивного аппарата, модальность которая не привязана к устному языку, и которая существует в других животных кроме человека.
Поэтому для представления знаний были предложены различные искусственные языки и нотации. Обычно они основаны на логике и математике, и имеют легко читаемую грамматику для облегчения машинной обработки. Обычно они попадают в широкую область онтологий.
Последней модой в языках представления знаний является использование XML в качестве низкоуровневого синтаксиса. Это приводит к тому, что вывод этих языков представления знаний машины могут легко Синтаксический анализ, за счёт Удобочитаемости для человека. Логика первого порядка и язык Пролог широко используется в качестве математической основы для этих систем, чтобы избежать избыточной сложности. Однако даже простые системы основанные на этой простой логике можно использовать для представления данных которое значительно лучше возможностей обработки для нынешних компьютерных систем: причины раскрываются в теории вычислимости.
DATR является примером представления лексических знаний
RDF является простой Нотация для представления отношений между и среди объектов
Примеры искусственных языков которые используются преимущественно для представления знаний:
KM: Машина Знаний (англ. Knowledge Machine) (фреймовый язык, использовавшийся для задач представления знаний)