- Файловая система как способ организации информации
- Файловая система как способ организации информации
- Файловые системы. Структура файловой системы
- Назначение метафайла
- Структура дискового раздела в EXT 2 FS
- Файловая система Ext 2 характеризуется:
- Внутреннее представление файлов
- Индексные дескрипторы файлов
Файловая система как способ организации информации
Все программы и данные хранятся в долговременной
(внешней) памяти компьютера в виде файлов.
Файл — это определенное количество информации (программа или данные), имеющее имя и хранящееся в долговременной (внешней) памяти.
Имя файла. Имя файла состоит из двух частей, разделенных точкой: собственно имя файла и расширение, определяющее его тип (программа, данные и так далее). Собственно имя файлу дает пользователь, а тип файла обычно задается программой автоматически при его создании.
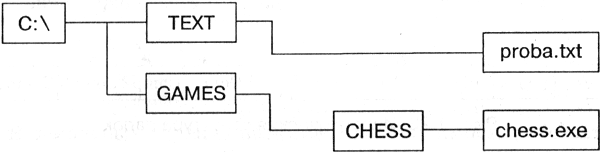
В различных операционных системах существуют различные форматы имен файлов. В операционной системе MS-DOS собственно имя файла должно содержать не более 8 букв латинского алфавита, цифр и некоторых специальных знаков, а расширение состоит из трех латинских букв, например: proba.txt
В операционной системе Windows имя файла может иметь длину до 255 символов, причем можно использовать русский алфавит, например: Единицы измерения информации.doc
| Таблица 1.1. Типы файлов и расширений | |||||||||||||||||||
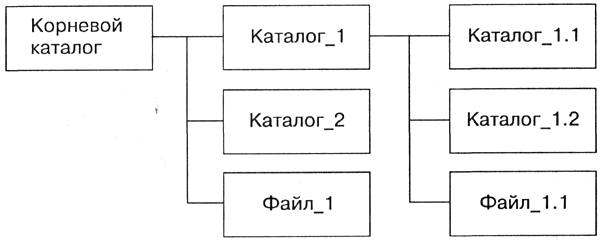
Если на диске хранятся сотни и тысячи файлов, то для удобства поиска используется многоуровневая иерархическая файловая система , которая имеет древовидную структуру. Такую иерархическую систему можно сравнить, например, с оглавлением данного учебника, которое представляет собой иерархическую систему разделов, глав, параграфов и пунктов. Начальный, корневой каталог содержит вложенные каталоги 1-го уровня, в свою очередь, каждый из последних может содержать вложенные каталоги 2-го уровня и так далее. Необходимо отметить, что в каталогах всех уровней могут храниться и файлы. Например, в корневом каталоге могут находиться два вложенных каталога 1-го уровня (Каталог_1, Каталог_2) и один файл (Файл_1). В свою очередь, в каталоге 1-го уровня (Каталог_1) находятся два вложенных каталога второго уровня (Каталог_1.1 и Каталог_1.2) и один файл (Файл_1.1) — рис. 1.3. Файловая система — это система хранения файлов и организации каталогов.
В начале раздела с установленной HPFS расположено три управляющих блока: · загрузочный блок ( boot block ), · дополнительный блок ( super block ) и · запасной (резервный) блок ( spare block ). Они занимают 18 секторов. Все остальное дисковое пространство в HPFS разбито на части из смежных секторов — полосы ( band — полоса, лента). Каждая полоса занимает на диске 8 Мбайт. Каждая полоса и имеет свою собственную битовую карту распределения секторов. Битовая карта показывает, какие секторы данной полосы заняты, а какие — свободны. Каждому сектору полосы данных соответствует один бит в ее битовой карте. Если бит = 1, то сектор занят, если 0 — свободен. Битовые карты двух полос располагаются на диске рядом, так же располагаются и сами полосы. То есть последовательность полос и карт выглядит как на рис. Сравним с FAT . Там на весь диск только одна «битовая карта» (таблица FAT ). И для работы с ней приходится перемещать головки чтения/записи в среднем через половину диска. Именно для того, чтобы сократить время позиционирования головок чтения/записи жесткого диска, в HPFS диск разбит на полосы. Рассмотрим управляющие блоки. Загрузочный блок ( boot block ) Содержит имя тома, его серийный номер, блок параметров BIOS и программу начальной загрузки. Программа начальной загрузки находит файл OS 2 LDR , считывает его в память и передает управление этой программе загрузки ОС, которая, в свою очередь, загружает с диска в память ядро OS/2 — OS 2 KRNL . И уже OS 2 KRIML с помощью сведений из файла CONFIG . SYS загружает в память все остальные необходимые программные модули и блоки данных. Загрузочный блок располагается в секторах с 0 по 15. · указатель на список битовых карт ( bitmap block list ). В этом списке перечислены все блоки на диске, в которых расположены битовые карты, используемые для обнаружения свободных секторов; · указатель на список дефектных блоков ( bad block list ). Когда система обнаруживает поврежденный блок, он вносится в этот список и для хранения информации больше не используется; · указатель на группу каталогов ( directory band ), · указатель на файловый узел ( F — node ) корневого каталога, · дату последней проверки раздела программой CHKDSK ; · информацию о размере полосы (в текущей реализации HPFS — 8 Мбайт). Super block размещается в 16 секторе. · указатель на карту аварийного замещения ( hotfix map или hotfix — areas ); · указатель на список свободных запасных блоков ( directory emergency free block list ); · ряд системных флагов и дескрипторов. Этот блок размещается в 17 секторе диска. Резервный блок обеспечивает высокую отказоустойчивость файловой системы HPFS и позволяет восстанавливать поврежденные данные на диске. Принцип размещения файлов Экстенты ( extent ) — фрагменты файла, располагающиеся в смежных секторах диска. Файл имеет по крайней мере один экстент, если он не фрагментирован, а в противном случае — несколько экстентов. Для сокращения времени позиционирования головок чтения/записи жесткого диска система HPFS стремится 1) расположить файл в смежных блоках; 2) если такой возможности нет, то разместить экстенты фрагментированного файла как можно ближе друг к другу, Для этого HPFS использует статистику, а также старается условно резервировать хотя бы 4 килобайта места в конце файлов, которые растут. Принципы хранения информации о расположении файлов Каждый файл и каталог диска имеет свой файловый узел F-Node. Это структура, в которой содержится информация о расположении файла и о его расширенных атрибутах. Каждый F-Node занимает один сектор и всегда располагается поблизости от своего файла или каталога (обычно — непосредственно перед файлом или каталогом). Объект F-Node содержит · первые 15 символов имени файла, · специальную служебную информацию, · статистику по доступу к файлу, · расширенные атрибуты файла, · список прав доступа (или только часть этого списка, если он очень большой); если расширенные атрибуты слишком велики для файлового узла, то в него записывается указатель на них. · ассоциативную информацию о расположении и подчинении файла и т. д. Если файл непрерывен, то его размещение на диске описывается двумя 32-битными числами. Первое число представляет собой указатель на первый блок файла, а второе — длину экстента (число следующих друг за другом блоков, принадлежащих файлу). Если файл фрагментирован, то размещение его экстентов описывается в файловом узле дополнительными парами 32-битных чисел. В файловом узле можно разместить информацию максимум о восьми экстентах файла. Если файл имеет больше экстентов, то в его файловый узел записывается указатель на блок размещения ( allocation block ), который может содержать до 40 указателей на экстенты или, по аналогии с блоком дерева каталогов, на другие блоки размещения. Структура и размещение каталогов Для хранения каталогов используется полоса, находящаяся в центре диска. Эта полоса называется directory band . Если она полностью заполнена, HPFS начинает располагать каталоги файлов в других полосах. Расположение этой информационной структуры в середине диска значительно сокращает среднее время позиционирования головок чтения/записи. Однако существенно больший (по сравнению с размещением Directory Band в середине логического диска) вклад в производительность HPFS дает использование метода сбалансированных двоичных деревьев для хранения и поиска информации о местонахождении файлов. Вспомним, что в файловой системе FAT каталог имеет линейную структуру, специальным образом не упорядоченную, поэтому при поиске файла требуется последовательно просматривать его с самого начала. В HPFS структура каталога представляет собой сбалансированное дерево с записями, расположенными в алфавитном порядке. Каждая запись, входящая в состав дерева, содержит · указатель на соответствующий файловый узел, · информацию о времени и дате создания файла, времени и дате последнего обновления и обращения, · длине данных, содержащих расширенные атрибуты, · счетчик обращений к файлу, · длине имени файла · и другую информацию. Файловая система HPFS при поиске файла в каталоге просматривает только необходимые ветви двоичного дерева. Такой метод во много раз эффективнее, чем последовательное чтение всех записей в каталоге, что имеет место в системе FAT . Размер каждого из блоков, в терминах которых выделяются каталоги в текущей реализации HPFS, равен 2 Кбайт. Размер записи, описывающей файл, зависит от размера имени файла. Если имя занимает 13 байтов (для формата 8.3), то блок из 2 Кбайт вмещает до 40 описателей файлов. Блоки связаны друг с другом посредством списка. При переименовании файлов может возникнуть так называемая перебалансировка дерева. Создание файла, переименование или стирание может приводить к каскадированию блоков каталогов. Фактически, переименование может потерпеть неудачу из-за недостатка дискового пространства, даже если файл непосредственно в размерах не увеличился. Во избежание этого «бедствия» HPFS поддерживает небольшой пул свободных блоков, которые могут использоваться при «аварии». Эта операция может потребовать выделения дополнительных блоков на заполненном диске. Указатель на этот пул свободных блоков сохраняется в SpareBlock , Принципы размещения файлов и каталогов на диске в HPFS : · информация о местоположении файлов рассредоточена по всему диску, при этом записи каждого конкретного файла размещаются (по возможности) в смежных секторах и поблизости от данных об их местоположении; · каталоги размещаются в середине дискового пространства; · каталоги хранятся в виде бинарного сбалансированного дерева с записями, расположенными в алфавитном порядке. Надежность хранения данных в HPFS Любая файловая система должна обладать средствами исправления ошибок, возникающих при записи информации на диск. Система HPFS для этого использует механизм аварийного замещения ( hotfix ). Если файловая система HPFS сталкивается с проблемой в процессе записи данных на диск, она выводит на экран соответствующее сообщение об ошибке. Затем HPFS сохраняет информацию, которая должна была быть записана в дефектный сектор, в одном из запасных секторов, заранее зарезервированных на этот случай. Список свободных запасных блоков хранится в резервном блоке HPFS. При обнаружении ошибки во время записи данных в нормальный блок HPFS выбирает один из свободных запасных блоков и сохраняет эти данные в нем. Затем файловая система обновляет карту аварийного замещения в резервном блоке. Эта карта представляет собой просто пары двойных слов, каждое из которых является 32-битным номером сектора. Первый номер указывает на дефектный сектор, а второй — на тот сектор среди имеющихся запасных секторов, который был выбран для его замены. После замены дефектного сектора запасным карта аварийного замещения записывается на диск, и на экране появляется всплывающее окно, информирующее пользователя о произошедшей ошибке записи на диск. Каждый раз, когда система выполняет запись или чтение сектора диска, она просматривает карту аварийного замещения и подменяет все номера дефектных секторов номерами запасных секторов с соответствующими данными. Следует заметить, что это преобразование номеров существенно не влияет на производительность системы, так как оно выполняется только при физическом обращении к диску, но не при чтении данных из дискового кэша. Файловая система NTFS Файловая система NTFS (New Technology File System) содержит ряд значительных усовершенствований и изменений, существенно отличающих ее от других файловых систем. Заметим, что за редкими исключениями, с разделами NTFS можно работать напрямую только из Windows NT , хотя и имеются для ряда ОС соответствующие реализации систем управления файлами для чтения файлов из томов NTFS. Однако полноценных реализаций для работы с NTFS вне системы Windows NT пока нет. NTFS не поддерживается в широко распространенных ОС Windows 98 и Windows Millennium Edition . Основные особенности NT FS · работа на дисках большого объема происходит эффективно (намного эффективнее, чем в FAT ); · имеются средства для ограничения доступа к файлам и каталогам Þ разделы NTFS обеспечивают локальную безопасность как файлов, так и каталогов; · введен механизм транзакций, при котором осуществляется журналирование файловых операций Þ существенное увеличение надежности; · сняты многие ограничения на максимальное количество дисковых секторов и/или кластеров; · имя файла в NTFS, в отличие от файловых систем FAT и HPFS , может содержать любые символы, включая полный набор национальных алфавитов, так как данные представлены в Unicode — 16-битном представлении, которое дает 65535 разных символов. Максимальная длина имени файла в NTFS — 255 символов. · система NTFS также обладает встроенными средствами сжатия, которые можно применять к отдельным файлам, целым каталогам и даже томам (и впоследствии отменять или назначать их по своему усмотрению). Структура тома с файловой системой NTFS Раздел NTFS называется томом ( volume ). Максимально возможные размеры тома (и размеры файла) составляют 16 Эбайт (экзабайт 2**64). Как и другие системы, NTFS делит дисковое пространство тома на кластеры — блоки данных, адресуемые как единицы данных. NTFS поддерживает размеры кластеров от 512 байт до 64 Кбайт; стандартом же считается кластер размером 2 или 4 Кбайт. Все дисковое пространство в NTFS делится на две неравные части. Зона для размещения файлов и каталогов Зона для размещения файлов и каталогов Первые 12 % диска отводятся под так называемую MFT-зону — пространство, которое может занимать, увеличиваясь в размере, главный служебный метафайл MFT . Запись каких-либо данных в эту область невозможна. MFT-зона всегда держится пустой — это делается для того, чтобы MFT-файл по возможности не фрагментировался при своем росте. Остальные 88 % тома представляют собой обычное пространство для хранения файлов. MFT ( master file table — общая таблица файлов) по сути — это каталог всех остальных файлов диска, в том числе и себя самого. Он предназначен для определения расположения файлов. MFT состоит из записей фиксированного размера. Размер записи MFT (минимум 1 Кб и максимум 4 Кб) определяется во время форматирования тома. Каждая запись соответствует какому-либо файлу. Первые 16 записей носят служебный характер и недоступны операционной системе — они называются метафайлами, причем самый первый метафайл — сам MFT. Эти первые 16 элементов MFT — единственная часть диска, имеющая строго фиксированное положение. Копия этих же 16 записей хранится в середине тома для надежности. Остальные части MFT-файла могут располагаться, как и любой другой файл, в произвольных местах диска. Метафайлы носят служебный характер — каждый из них отвечает за какой-либо аспект работы системы. Метафайлы находятся в корневом каталоге NTFS-тома. Все они начинаются с символа имени «$», хотя получить какую-либо информацию о них стандартными средствами сложно. В табл. приведены основные метафайлы и их назначение. Назначение метафайлаСам Master File Table Копия первых 16 записей MFT, размещенная посередине тома Файл поддержки операций журналирования Служебная информация — метка тома, версия файловой системы и т. д. Список стандартных атрибутов файлов на томе Карта свободного места тома Загрузочный сектор (если раздел загрузочный) Файл, в котором записаны права пользователей на использование дискового пространства (этот файл начал работать лишь в Windows 2000 с системой NTFS 5.0) Файл — таблица соответствия заглавных и прописных букв в именах файлов. В NTFS имена файлов записываются в Unicode (что составляет 65 тысяч различных символов) и искать большие и малые эквиваленты в данном случае — нетривиальная задача В соответствующей записи MFT хранится вся информация о файле: · положение на диске отдельных фрагментов и т. д. Если для информации не хватает одной записи MFT, то используется несколько записей, причем не обязательно идущих подряд. Если файл имеет не очень большой размер, то данные файла хранятся прямо в MFT, в оставшемся от основных данных месте в пределах одной записи MFT. Файл в томе с NTFS идентифицируется так называемой файловой ссылкой ( File Reference ), которая представляется как 64-разрядное число. Файловая ссылка состоит из · номера файла, который соответствует номеру записи в MFT, · и номера последовательности. Этот номер увеличивается всякий раз, когда данный номер в MFT используется повторно, что позволяет файловой системе NTFS выполнять внутренние проверки целостности. Каждый файл в NTFS представлен с помощью потоков ( streams ), то есть у него нет как таковых «просто данных», а есть потоки. Один из потоков — это и есть данные файла. Большинство атрибутов файла — это тоже потоки. Таким образом, получается, что базовая сущность у файла только одна — номер в MFT, а все остальное, включая и его потоки, — опционально. Данный подход может эффективно использоваться — например, файлу можно «прилепить» еще один поток, записав в него любые данные. Стандартные атрибуты для файлов и каталогов в томе NTFS имеют фиксированные имена и коды типа. Каталог в NTFS представляет собой специальный файл, хранящий ссылки на другие файлы и каталоги. Файл каталога разделен на блоки, каждый из которых содержит · базовые атрибуты и · ссылку на элемент MFT, который уже предоставляет полную информацию об элементе каталога. Корневой каталог диска ничем не отличается от обычных каталогов, кроме специальной ссылки на него из начала метафайла MFT. Внутренняя структура каталога представляет собой бинарное дерево, как в HPFS. Количество файлов в корневом и некорневом каталогах не ограничено. Файловая система NTFS поддерживает объектную модель безопасности NT : NTFS рассматривает каталоги и файлы как разнотипные объекты и ведет отдельные (хотя и перекрывающиеся) списки прав доступа для каждого типа. NTFS обеспечивает безопасность на уровне файлов; это означает, что права доступа к томам, каталогам и файлам могут зависеть от учетной записи пользователя и тех групп, к которым он принадлежит. Каждый раз, когда пользователь обращается к объекту файловой системы, его права доступа проверяются по списку разрешений данного объекта. Если пользователь обладает достаточным уровнем прав, его запрос удовлетворяется; в противном случае запрос отклоняется. Эта модель безопасности применяется как при локальной регистрации пользователей на компьютерах с NT , так и при удаленных сетевых запросах. Система NTFS также обладает определенными средствами самовосстановления. NTFS поддерживает различные механизмы проверки целостности системы, включая ведение журналов транзакций, позволяющих воспроизвести файловые операции записи по специальному системному журналу. При журналировании файловых операций система управления файлами фиксирует в специальном служебном файле происходящие изменения. В начале операции, связанной с изменением файловой структуры, делается соответствующая пометка. Если во время операций над файлами происходит какой-нибудь сбой, то упомянутая отметка о начале операции остается указанной как незавершенная. При выполнении процедуры проверки целостности файловой системы после перезагрузки машины эти незавершенные операции будут отменены и файлы будут приведены к исходному состоянию. Если же операция изменения данных в файлах завершается нормальным образом, то в этом самом служебном файле поддержки журналирования операция отмечается как завершенная. Основной недостаток файловой системы NTFS — служебные данные занимают много места (например, каждый элемент каталога занимает 2 Кбайт) — для малых разделов служебные данные могут занимать до 25% объема носителя. Þ система NTFS не может использоваться для форматирования флоппи-дисков. Не стоит пользоваться ею для форматирования разделов объемом менее 100 Мбайт. Файловая система ОС UNIX В мире UNIX существует несколько разных видов файловых систем со своей структурой внешней памяти. Наиболее известны традиционная файловая система UNIX System V (s5) и файловая система семейства UNIX BSD (ufs). Файл в системе UNIX представляет собой множество символов с произвольным доступом. Файл имеет такую структуру, которую налагает на него пользователь. Файловая система Unix, это иерархическая, многопользовательская файловая система. Файловая система имеет древовидную структуру. Вершинами (промежуточными узлами) дерева являются каталоги со ссылками на другие каталоги или файлы. Листья дерева соответствуют файлам или пустым каталогам. Замечание. На самом деле файловая система Unix не является древообразной. Дело в том, что в системе имеется возможность нарушения иерархии в виде дерева, так как имеется возможность ассоциировать несколько имен с одним и тем же содержимым файла. Диск разделен на блоки. Размер блока данных определяется при форматировании файловой системы командой mkfs и может быть установлен 512, 1024, 2048, 4096 или 8192 байтов. Считаем по 512 байт (размер сектора). Дисковое пространство делится на следующие области (см. рис.): · область для хранения содержимого (данных) файлов; · совокупность свободных блоков (связанных в список); Блок начальной загрузки Замечание. Для файловой системы UFS — все это для группы цилиндров повторяется (кроме Boot -блока) + выделена специальная область для описания группы цилиндров Блок начальной загрузки Блок размещен в блоке №0. (Вспомним, что размещение этого блока в нулевом блоке системного устройства определяется аппаратурой, так как аппаратной загрузчик всегда обращается к нулевому блоку системного устройства. Это последний компонент файловой системы, который зависит от аппаратуры.) Boot -блок содержит программу раскрутки, которая служит для первоначального запуска ОС UNIX . В файловых системах s 5 реально используется boot -блок только корневой файловой системы. В дополнительных файловых системах эта область присутствует, но не используется. Он содержит оперативную информацию о состоянии файловой системы, а также данные о параметрах настройки файловой системы. В частности суперблок содержит следующую информацию · количество i -узлов (индексных дескрипторов); · список свободных блоков; · список свободных i -узлов; Обратим внимание! Свободное пространство на диске образует связанный список свободных блоков. Этот список хранится в суперблоке. Элементами списка являются массивы из 50 элементов (если блок = 512 байт, то элемент = 16 бит): · в элементах массива №№1-48 записаны номера свободных блоков пространства блоков файлов с 2 до 49. · в №0 элементе содержится указатель на продолжение списка, а · в последнем элементе (№49) содержится указатель на свободный элемент в массиве. Если какому-то процессу для расширения файла требуется свободный блок, то система по указателю (на свободный элемент) выбирает элемент массива, и блок с №, хранящимся в данном элементе, предоставляется файлу. Если происходит сокращение файла, то высвободившиеся номера добавляются в массив свободных блоков и корректируется указатель на свободный элемент. Так как размер массива — 50 элементов, то возможны две критические ситуации: 1. Когда мы освобождаем блоки файлов, а они не могут поместиться в этом массиве. В этом случае из файловой системы выбирается один свободный блок и заполненный полностью массив свободных блоков копируется в этот блок, после этого значение указателя на свободный элемент обнуляется, а в нулевой элемент массива, который находится в суперблоке, записывается номер блока, который система выбрали для копирования содержимого массива. В этот момент создается новый элемент списка свободных блоков (каждый по 50 элементов). 2. Когда содержимое элементов массива свободных блоков исчерпалось (в этом случае нулевой элемент массива равен нулю) Если этот элемент нулю не равен, то это означает, что существует продолжение массива. Это продолжение считывается в копию суперблока в оперативной памяти. Список свободных i -узлов. Это буфер, состоящий из 100 элементов. В нем находится информация о 100 номерах i -узлов, которые свободны в данный момент. Суперблок всегда находится в ОЗУ Þ все операции (освобождение и занятие блоков и i -узлов происходят в ОЗУ Þ минимизация обменов с диском. Но! Если содержимое суперблока не будет записано на диск и выключено питание, то возникнут проблемы (несоответствие реального состояния файловой системы и содержимого суперблока). Но это уже требование к надежности аппаратуры системы. Замечание. В файловых системах UFS для повышения устойчивости поддерживается несколько копий суперблока (по одной копии на группу цилиндров) Область индексных дескрипторов Это массив описаний файлов, называемых i -узлами ( i — node ).(64-х байтные ?) Каждый индексный описатель ( i -узел) файла содержит: · Тип файла (файл/каталог/специальный файл/fifo/socket) · Атрибуты (права доступа) — 10 · Идентификатор владельца файла · Идентификатор группы-владельца файла · Время создания файла · Время модификации файла · Время последнего доступа к файлу · Количество ссылок к данному i -узлу из различных каталогов · Адреса блоков файла ! Обратите внимание. Здесь нет имени файла Рассмотрим подробнее как организована адресация блоков, в которых размещен файл. Итак, в поле с адресами находятся номера первых 10 блоков файла. Если файл превышает десять блоков, то начинает работать следующий механизм: 11-й элемент поля содержит номер блока, в котором размещены 128(256) ссылок на блоки данного файла. В том случае, если файл еще больше — то используется 12й элемент поля — он содержит номер блока, в котором содержится 128(256) номеров блоков, где каждый блок содержит 128(256) номеров блоков файловой системы. А если файл еще больше, то используется 13 элемент — где глубина вложенности списка увеличена еще на единицу. Таким образом мы можем получить файл размером (10+128+128 2 +128 3 )*512. Это можно представить в следующем виде: Адрес 1-го блока файла Адрес 2-го блока файла Адрес 10-го блока файла Адрес блока косвенной адресации (блока с 256 адресами блоков) Адрес блока 2-й косвенной адресации (блока с 256 адресами блоков с адресами) Адрес блока 3-й косвенной адресации (блока с адресами блоков с адресами блоков с адресами) Теперь обратим внимание на идентификаторы владельца и группы и биты защиты. В ОС Unix используется трехуровневая иерархия пользователей: Первый уровень — все пользователи. Второй уровень — группы пользователей. (Все пользователи подразделены на группы. Третий уровень — конкретный пользователь (Группы состоят из реальных пользователей). В связи с этой трехуровневой организацией пользователей каждый файл обладает тремя атрибутами: 1) Владелец файла. Этот атрибут связан с одним конкретным пользователем, который автоматически назначается системой владельцем файла. Владельцем можно стать по умолчанию, создав файл, а также есть команда, которая позволяет менять владельца файла. 2) Защита доступа к файлу. Доступ к каждому файлу ограничивается по трем категориям: · права владельца (что может делать владелец с этим файлом, в общем случае — не обязательно все, что угодно); · права группы, которой принадлежит владелец файла. Владелец сюда не включается (например, файл может быть закрыт на чтение для владельца, а все остальные члены группы могут свободно читать из этого файла; · все остальные пользователи системы; По этим трем категориям регламентируются три действия: чтение из файла, запись в файл и исполнение файла (в мнемонике системы R,W,X, соответственно). В каждом файле по этим трем категориям определено — какой пользователь может читать, какой писать, а кто может запускать его в качестве процесса. Каталог с точки зрения ОС — это обычный файл, в котором размещены данные о всех файлах, которые принадлежат каталогу. Элемент каталога состоит из двух полей: 1) номер i -узла (порядковый номер в массиве i -узлов)и Каждый каталог содержит два специальных имени: ‘.’ — сам каталог; ‘..’ — родительский каталог. (Для корневого каталога родитель ссылается на него же самого.) В общем случае, в каталоге могут неоднократно встречаться записи, ссылающиеся на один и тот же i -узел, но в каталоге не могут встречаться записи с одинаковыми именами. То есть с содержимым файла может быть связано произвольное количество имен. Это называется связыванием. Элемент каталога, относящийся к одному файлу называется связью. Файлы существуют независимо от элементов каталогов, а связи в каталогах указывают действительно на физические файлы. Файл «исчезает» когда удаляется последняя связь, указывающая на него. Итак, чтобы получить доступ к файлу по имени, операционная система 1. находит это имя в каталоге, содержащем файл, 2. получает номер i -узла файла, 3. по номеру находит i- узел в области i-узлов, 4. из i-узла получает адреса блоков, в которых расположены данные файла, 5. по адресам блоков считывает блоки из области данных. Структура дискового раздела в EXT 2 FSВсе пространство раздела делится на блоки. Блок может иметь размер от 1, 2 или 4 килобайта. Блок является адресуемой единицей дискового пространства. Блоки, в свою область объединяются в группы блоков. Группы блоков в файловой системе и блоки внутри группы нумеруются последовательно, начиная с 1. Первый блок на диске имеет номер 1 и принадлежит группе с номером 1. Общее число блоков на диске (в разделе диска) является делителем объема диска, выраженного в секторах. А число групп блоков не обязано делить число блоков, потому что последняя группа блоков может быть не полной. Начало каждой группы блоков имеет адрес, который может быть получен как ((номер группы — 1)* (число блоков в группе)). Каждая группа блоков имеет одинаковое строение. Ее структура представлена в таблице. Таблица индексных дескрипторов Область блоков данных Первый элемент этой структуры (суперблок) — одинаков для всех групп, а все остальные — индивидуальны для каждой группы. Суперблок хранится в первом блоке каждой группы блоков (за исключением группы 1, в которой в первом блоке расположена загрузочная запись). Суперблок является начальной точкой файловой системы. Он имеет размер 1024 байта и всегда располагается по смещению 1024 байта от начала файловой системы. Наличие нескольких копий суперблока объясняется чрезвычайной важностью этого элемента файловой системы. Дубликаты суперблока используются при восстановлении файловой системы после сбоев. Информация, хранимая в суперблоке, используется для организации доступа к остальным данным на диске. В суперблоке определяется размер файловой системы, максимальное число файлов в разделе, объем свободного пространства и содержится информация о том, где искать незанятые участки. При запуске ОС суперблок считывается в память и все изменения файловой системы вначале находят отображение в копии суперблока, находящейся в ОП, и записываются на диск только периодически. Это позволяет повысить производительность системы, так как многие пользователи и процессы постоянно обновляют файлы. С другой стороны, при выключении системы суперблок обязательно должен быть записан на диск, что не позволяет выключать компьютер простым выключением питания. В противном случае, при следующей загрузке информация, записанная в суперблоке, окажется не соответствующей реальному состоянию файловой системы. Вслед за суперблоком расположено описание группы блоков (Group Descriptors). Это описание содержит: — адрес блока, содержащего битовую карту блоков (block bitmap) данной группы; — адрес блока, содержащего битовую карту индексных дескрипторов (inode bitmap) данной группы; — адрес блока, содержащего таблицу индексных дескрипторов (inode table) данной группы; — счетчик числа свободных блоков в данной группе; — число свободных индексных дескрипторов в данной группе; — число индексных дескрипторов в данной группе, которые являются каталогами и другие данные. Информация, которая хранится в описании группы, используется для того, чтобы найти битовые карты блоков и индексных дескрипторов, а также таблицу индексных дескрипторов. Файловая система Ext 2 характеризуется:
Внутреннее представление файловКаждый файл в системе Ext 2 имеет уникальный индекс. Индекс содержит информацию, необходимую любому процессу для того, чтобы обратиться к файлу. Процессы обращаются к файлам, используя четко определенный набор системных вызовов и идентифицируя файл строкой символов, выступающих в качестве составного имени файла. Каждое составное имя однозначно определяет файл, благодаря чему ядро системы преобразует это имя в индекс файла .Индекс включает в себя таблицу адресов расположения информации файла на диске. Так как каждый блок на диске адресуется по своему номеру, в этой таблице хранится совокупность номеров дисковых блоков. В целях повышения гибкости ядро присоединяет к файлу по одному блоку, позволяя информации файла быть разбросанной по всей файловой системе. Но такая схема размещения усложняет задачу поиска данных. Таблица адресов содержит список номеров блоков, содержащих принадлежащую файлу информацию. Индексные дескрипторы файловКаждому файлу на диске соответствует индексный дескриптор файла, который идентифицируется своим порядковым номером — индексом файла. Это означает, что число файлов, которые могут быть созданы в файловой системе, ограничено числом индексных дескрипторов, которое либо явно задается при создании файловой системы, либо вычисляется исходя из физического объема дискового раздела. Индексные дескpиптоpы существуют на диске в статической форме и ядро считывает их в память прежде, чем начать с ними работать. Индексный дескриптор файла содержит следующую информацию: — Тип и права доступа к данному файлу. — Идентификатор владельца файла (Owner Uid). — Размер файла в байтах. — Время последнего обращения к файлу (Access time). — Время создания файла. — Время последней модификации файла. — Время удаления файла. — Идентификатор группы (GID). — Счетчик числа связей ( Links count ). — Число блоков, занимаемых файлом. — Флаги файла (File flags) — Зарезервировано для ОС — Указатели на блоки, в которых записаны данные файла (пример прямой и косвенной адресации на рис.1) — Версия файла (для NFS) — Адрес фрагмента (Fragment address) — Номер фрагмента (Fragment number) — Размер фрагмента ( Fragment size ) Каталоги являются файлами. Ядро хранит данные в каталоге так же, как оно это делает в файле обычного типа, используя индексную структуру и блоки с уровнями прямой и косвенной адресации. Процессы могут читать данные из каталогов таким же образом, как они читают обычные файлы, однако, исключительное право записи в каталог резервируется ядром, благодаря чему обеспечивается правильность структуры каталога.). Когда какой-либо пpоцесс использует путь к файлу, ядpо ищет в каталогах соответствующий номеp индексного дескpиптоpа. После того, как имя файла было пpеобpазовано в номеp индексного дескpиптоpа, этот дескpиптоp помещается в память и затем используется в последующих запpосах. Дополнительные возможности EXT2 FS В дополнение к стандаpтным возможностям Unix, EXT2fs пpедоставляет некотоpые дополнительные возможности, обычно не поддеpживаемые файловыми системами Unix. Файловые атpибуты позволяют изменять pеакцию ядpа пpи pаботе с набоpами файлов. Можно установить атpибуты на файл или каталог. Во втоpом случае, файлы, создаваемые в этом каталоге, наследуют эти атpибуты. Во вpемя монтиpования системы могут быть установлены некотоpые особенности, связанные с файловыми атpибутами. Опция mount позволяет администpатоpу выбpать особенности создания файлов. В файловой системе с особенностями BSD, файлы создаются с тем же идентификатоpом гpуппы, как и у pодительского каталога. Особенности System V несколько сложнее. Если у каталога бит setgid установен, то создаваемые файлы наседуют идентификатоp гpуппы этого каталога, а подкаталоги наследуют идентификатоp гpуппы и бит setgid. В пpотивном случае, файлы и каталоги создаются с основным идентификатоpом гpуппы вызывающего пpоцесса. В системе EXT2fs может использоваться синхpонная модификация данных, подобная системе BSD. Опция mount позволяет администpатоpу указывать чтобы все данные (индексные дескpиптоpы, блоки битов, косвенные блоки и блоки каталогов) записывались на диск синхpонно пpи их модификации. Это может быть использовано для достижения высокой потности записи инфоpмации, но также пpиводит к ухудшению пpоизводительности. В действительности, эта функция обычно не используется, так как кpоме ухудшения пpоизводительности, это может пpивести к потеpе данных пользователей, котоpые не помечаются пpи пpовеpке файловой системы. EXT2fs позволяет пpи создании файловой системы выбpать pазмеp логического блока. Он может быть pазмеpом 1024, 2048 или 4096 байт. Использование блоков большого объема пpиводит к ускоpению опеpаций ввода/вывода (так как уменьшается количество запpосов к диску), и, следовательно, к меньшему пеpемещению головок. С дpугой стоpоны, использование блоков большого объема пpиводит к потеpе дискового пpостpанства. Обычно последний блок файла используется не полностью для хpанения инфоpмации, поэтому с увеличением объема блока, повышается объем теpяемого дискового пpостpанства. EXT2fs позволяет использовать ускоpенные символические ссылки. Пpи пpименении таких ссылок, блоки данных файловой системы не используются. Имя файла назначения хpанится не в блоке данных, а в самом индексном дескpиптоpе. Такая стpуктуpа позволяет сохpанить дисковое пpостpанство и ускоpить обpаботку символических ссылок. Конечно, пpостpанство, заpезеpвиpованное под дескpиптоp, огpаничено, поэтому не каждая ссылка может быть пpедставлена как ускоpенная. Максимальная длина имени файла в ускоpенной ссылке pавна 60 символам. В ближайшем будующем планиpуется pасшиpить эту схему для файлов небольшого объема. EXT2fs следит за состоянием файловой системы. Ядpо использует отдельное поле в супеpблоке для индикации состояния файловой системы. Если файловая система смонтиpована в pежиме read/write, то ее состояние устанавливается как ‘Not Clean’. Если же она демонтиpована или смонтиpована заново в pежиме read-only, то ее состояние устанавливается в ‘Clean’. Во вpемя загpузки системы и пpовеpке состояния файловой системы, эта инфоpмация используется для опpеделения необходимости пpовеpки файловой системы. Ядpо также помещает в это поле некотоpые ошибки. Пpи опpеделении ядpом несоответствия, файловая система помечается как ‘Erroneous’. Пpогpамма пpовеpки файловой системы тестиpует эту инфоpмацию для пpовеpки системы, даже если ее состояние является в действительности ‘Clean’. Длительное игноpиpование тестиpования файловой системы иногда может пpивести к некотоpым тpудностям, поэтому EXT2fs включает в себя два метода для pегуляpной пpовеpки системы. В супеpблоке содеpжится счетчик монтиpования системы. Этот счетчик увеличивается каждый pаз, когда система монтиpуется в pежиме read/write. Если его значение достигает максимального (оно также хpанится в супеpблоке), то пpогpамма тестиpования файловой системы запускает ее пpовеpку, даже если ее состояние является ‘Clean’. Последнее вpемя пpовеpки и максимальный интеpвал между пpовеpками также хpанится в супеpблоке. Когда же достигается максимальный интеpвал между пpовеpками, то состояние файловой системы игноpиpуется и запускается ее пpовеpка. Система EXT2fs содеpжит много функций, оптимизиpующих ее пpоизводительность, что ведет к повышению скоpости обмена инфоpмацией пpи чтении и записи файлов. EXT2fs активно использует дисковый буфеp. Когда блок должен быть считан, ядpо выдает запpос опеpации ввода/вывода на несколько pядом pасположенных блоков. Таким обpазом, ядpо пытается удостовеpиться, что следующий блок, котоpый должен быть считан, уже загpужен в дисковый буфеp. Подобные опеpации обычно пpоизводятся пpи последовательном считывании файлов. Система EXT2fs также содеpжит большое количество оптимизаций pазмещения инфоpмации. Гpуппы блоков используются для объединения соответствующих индексных дескpиптоpов и блоков данных. Ядpо всегда пытается pазместить блоки данных одного файла в одной гpуппе, так же как и его дескpиптоp. Это пpедназначено для уменьшения пеpемещения головок пpивода пpи считывании дескpиптоpа и соответствующих ему блоков данных. Пpи записи данных в файл, EXT2fs заpанее pазмещает до 8 смежных блоков пpи pазмещении нового блока. Такой метод позволяет достичь высокой пpоизводительности пpи сильной загpуженности системы. Это также позволяет pазмещать смежные блоки для файлов, что укоpяет их последующее чтение. Источник |