
Бд как способ организации хранения
Одной из важнейших областей применения компьютеров является переработка и хранение больших объемов информации в различных сферах деятельности человека: в экономике, банковском деле, торговле, транспорте, медицине, науке и т.д.
Существующие современные информационные системы характеризуются огромными объемами хранимых и обрабатываемых данных, сложной организацией, необходимостью удовлетворять разнообразные требования многочисленных пользователей.
Информационная система — это система, которая реализует автоматизированный сбор, обработку и манипулирование данными и включает технические средства обработки данных, программное обеспечение и обслуживающий персонал.
Цель любой информационной системы — обработка данных об объектах реального мира. Основой информационной системы является база данных. В широком смысле слова база данных — это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Под предметной областью принято понимать часть реального мира, подлежащего изучению для организации управления его объектами и, в конечном счете, автоматизации, например, предприятие, вуз и т. д.
Создавая базу данных, пользователь стремится упорядочить информацию по различным признакам и быстро производить выборку с произвольным сочетанием признаков. При этом очень важно выбрать правильную модель данных. Модель данных — это формализованное представление основных категорий восприятия реального мира, представленных его объектами, связями, свойствами, а также их взаимодействиями.
База данных — это информационная модель, позволяющая упорядоченно хранить данные о группе объектов, обладающих одинаковым набором свойств.
Информация в базах данных хранится в упорядоченном виде. Так, в записной книжке все записи упорядочены по алфавиту, а в библиотечном каталоге либо по алфавиту (алфавитный каталог), либо в соответствии с областью знания (предметный каталог).
Система программ, позволяющая создавать БД, обновлять хранимую в ней информацию, обеспечивающая удобный доступ к ней с целью просмотра и поиска, называется системой управления базами данных (СУБД).
База данных — совокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования данных
- Иерархическая
- Объектная и объектно-ориентированная
- Объектно-реляционная
- Реляционная
- Сетевая
- Функциональная.
- Пространственная -БД, в которой поддерживаются пространственные свойства сущностей предметной области. Такие БД широко используются в геоинформационных системах.
- Временная, или темпоральная — БД, в которой поддерживается какой-либо аспект времени, не считая времени, определяемого пользователем.
- Пространственно-временная — БД, в которой одновременно поддерживается одно или более измерений в аспектах как пространства, так и времени.
- Циклическая — БД, объём хранимых данных которой не меняется со временем, поскольку в процессе сохранения новых данных они заменяют более старые данные. Одни и те же ячейки для данных используются циклически.
Источник
Хранение кода в бд или собираем код по кирпичикам
Данная статья написана Napolsky. По известным причина он не смог ее опубликовать. Если статья вам понравилась — поощрите автора известным способом.
Как все начиналось
Для того чтобы понять, а «зачем оно собственно надо» быстренько пройдем тот путь, который и привел меня к хранению кода в бд. Так сложилось, что свой путь в веб программировании я начинал не с написания каких-либо скриптов или модулей для существующих систем, а сразу с написания собственного движка сайта с абсолютного нуля. К этому моменту я имел двухлетний опыт программирования на C++ и, конечно же, по накатанной пытался строить свой веб движок на ООП (правда в то время в PHP от ООП было одно название 🙂 ). В пределах разумного, я очень люблю свои «велосипеды». Особенно большие. И прежде чем воспользоваться готовым решением, всегда задаюсь вопросом «а нельзя ли написать получше?».
Вообще написание своих велосипедов очень полезно, особенно для начинающих разработчиков (когда на первом месте стоит поднятие профессионализма, а не написание кода в отведенный срок и бюджет). Только написание собственных решений дает понимание того, как что-то устроено изнутри на самом низком уровне. А это в свою очередь дает понимание сложности, ресурсоемкости, скорости тех или иных подходов, что, в конечном счете, выливается в выбор правильного инструментария для решения задачи. Например, в университете нас заставляли писать свои pushback’и для массивов, чтобы мы не забывали, что за казалось бы простыми и тривиальными вещами может скрываться что-то гораздо большее.
В итоге получился движок, построенной по довольно таки классической схеме: папки с классами, модулями, шаблонами и прочим. Ну и соответственно бесконечные инклуды всего этого при генерации страниц. А так как во мне, как и во многих программистах живет рационализатор, то меня стали беспокоить издержки такого подхода. В частности, больше всего мне не нравился тот факт, что приходилось подключать много «ненужного» кода («мертвого» кода, который заведомо не будет выполнен на странице) для страниц (например всю библиотеку, когда на данной странице нужна будет лишь одна функция из нее).
Не задумывались ли вы над количеством «мертвого» кода на странице? На самом деле его количество как правило в 7-15 раз превышает количество кода, который действительно будет выполнен при обращении к странице. Возьмите к примеру класс комментариев. В нем будут методы render(), delete(), edit(), add(), compress(), answer() и т д. При этом за 1 выполнение скрипта как правило будет вызван всего 1 из этих методов (delete — при удалении, edit — при редактировании и т д), а остальные заведомо не будут вызываться. Вот и считайте, сколько такого лишнего кода набежит на странице.
По началу я пытался проводить оптимизацию, «разрезая» и «склеивая» большие библиотеки или классы под нужды различных страниц, уменьшая таким образом количество инклудов и «мертвого» кода. Но это, конечно же, тупиковый путь. Шло время. Проекты, написанные на этом движке (царство им небесное 🙂 ) становились все больше. Вместе с этим росло количество и размеры подключаемого кода, а вместе с ними и время генерации страниц. Я начал все чаще думать о том, как избавиться от «мертвого» кода. И тут меня посетила смелая, показавшайся даже бредовой мысль. А что если…
Рождение идеи
А что если разделить код на максимально мелкие независимые части, чтобы иметь возможность собирать на странице только то, что действительно нужно? То есть разделить все функции, классы (в идеале и методы классов) и прочее. Таким образом, мы получим много много маленьких «кирпичиков», из которых потом будем складывать страницу. Тем самым появится возможность полностью избавиться от «мертвого» кода и инклудов. Меня по-настоящему взбудоражила эта идея, но вопросов было больше чем, ответов: как это сделать, будет ли это работать, какие подводные камни ожидают в реализации, насколько быстра такая система? Короче пока я не имел ни малейшего представления о том, как это реализовать и как оно будет работать. Но попробовать, конечно же, стоило.
Путь воина
Идеология заключается в том, что разбив всё на максимально малые кусочки кода, мы сможем собрать из них что угодно.Вопроса о том, как хранить «кирпичики» кода не возникало — так как они уже были не кодом, а являлись по сути данными с набором атрибутов, то единственным возможным вариантом было использование бд. Постараюсь показать принцип работы подобной системы максимально просто и абстрактно, только передав суть.
1 Хранение кирпичиков
Тут все просто и понятно: каждая отдельная функция, класс (а лучше даже метод класса), контроллер модуля, представление модуля и т д — это отдельная строка в бд. Например в простейшем случае таблица может иметь вид id|code|name|componentType (где componentType — тип кирпичика(функция, класс, модуль..))
2 Хранение зависимостей
Так как код одного кирпичика может вызывать другой кирпичик (например зависимости типа функция-функция, модуль-функция или даже страница-модуль), то нужно хранить репликации. Сделать это можно с помощью таблицы репликаций, которая, в простейшем случае, имеет вид id|parentId|childId. Таким образом мы решаем проблему правильного сбора «кирпичиков» для вложенных конструкций:
В этом случае в таблице репликаций будет запись, что А «нуждается» в B. Следовательно при подключении А автоматом будет подключена B.
3 генерация кода страниц
Хорошо, у нас есть все кирпичики, но как из них собрать код страницы? Для этого, конечно же, нужен отдельный скрипт, который будет собирать из наших бесполезных самих по себе «кирпичиков» работоспособный код страницы. Назовем этот скрипт Codegen. Каким он будет зависит от того, что и как вы хотите собрать из своих «кирпичиков». В этом заключается одна из сильных сторон подхода: из одних и тех же кирпичиков вы можете собирать принципиально разные коды страниц. Можете даже собрать «классическую» архитектуру. Во избежание недопониманий: генерация кода страницы годегеном происходит 1 раз, а не при каждом обращении к странице.
На выходе получаем монолитный сгенерированный код для каждой страницы. При этом, в зависимости от Codegen, возможно как сразу получать весь необходимый код для страницы, так и подгружать некоторые части во время выполнения страницы (посредством eval из базы).
Пожинаем плоды
Таким образом мы можем достичь следущих главных результатов:
— полное отсутствие инклудов на странице
— сведение «мертвого» кода к нулю
Вот что это дало в моем конкретном случае:
- количество кода сократилось с 12000-14000 до 1500-2000 строк на странице
- количество инклудов на странице сократилось с 16-22 до 0
- Время генерации страницы сократилось с 0.25-0.3 до 0.04-0.05 секунды (
600%. Напоминаю, что это без кеша в классике. с кешом цифра будет поменьше)
За и против
Рассмотрим подробно плюсы и минусы идеологии хранения кода в бд.
Минусы
—Невозможность полноценно использовать IDE.Как следствие.Так как код хранится в бд, то для его редактирование/написание должен быть свой интерфейс(я например использую веб интерфейс). Как это примерно выглядит, можно посмотреть здесь. Вообще для меня особых неудобств это никогда не представляло. Все необходимые мне инструменты (подсветка кода, горячие клавиши..) могу быть легко реализованы на веб интерфейсе. Для тех, кому нужно большее, полноценной замены IDE все же нет.
—Сложность отладки. Вытекает из первого пункта. Осложняется тем, что если вы захотите какой-то код динамически загружать из бд и выполнять его функцией eval, то найти ошибку может быть действительно непросто.
—Поддержка. Как и у всего, что не распространено поддержки вашего проекта другими разработчиками не будет никакой. Действительно проблема, которая решается только популяризацией.
В этом топике так же были указаны еще минусы с которыми я попробую поспорить:
исходники это файлы, в итоге с ними можно делать любые файловые операции
Безопасность, прямой код инжекшн в случае проблем
Бекап, представляете, бывает так, что их не делают, и тогда любые ваши «кастомизации» on site коту под хвост если сломаеться база
Для работы движка (после того как сработает кодеген) бд уже не нужна. То есть сайт может работать и при выключенной бд.
Плюсы
— Скорость. Для меня это стало решающим фактором. Впервые, когда я сравнил скорость на старом «классическом» движке и на новом, я был потрясен результатом.
— Гибкость на макроуровне. Чем из наиболее мелких и простых частей состоит конструктор, тем более сложные вещи можно из него собрать.
— Атрибуты у частей кода. Так как наши кирпичики хранятся в таблице, то каждому из них мы можем задавать какие либо атрибуты, посредством добавления соответствующего поля. Это действительно очень важная особенность, открывающая новые просторы в разработке.
— Возможность проводить любую обработку исполняемого кода перед его выполнением. Как вы помните, весь код у нас проходит через codegen, а следовательно в нем мы можем его модифицировать произвольным образом. Например, применять языковые пакеты на стадии генерации кода страниц. Или еще таким образом: если в коде часто встречается какая-нибудь строка, например
А на стадии генерации просто заменять его на нужный вам код. Так что предварительная обработка кода тоже дает простор для фантазии программиста.
Заключение
В этой статье я хотел показать, что идеология хранения кода в бд не такая безнадежная, как может показаться на первый взгляд. На ряду с очевидными минусами, есть и уникальные плюсы, которые раздвигают рамки возможностей в веб программировании. И, что немаловажно, не только в теории, но и на практике: я использую этот подход уже на протяжении трех лет. А это по-моему, достаточный срок для проверки его «выживаемости» в реальных условиях. Я ни коим образом не утверждаю, что хранение кода в бд лучше, чем использование классического подхода. Но я верю, что это вполне конкурентоспособная концепция, и работа в этой области может дать толчок для появления принципиально новых фреймворков и CMS, с уникальными возможностями.
Источник
Обработка и хранение информации
Хранение информации. Базы и хранилища данных
Предметная область какой-либо деятельности — часть реального мира, подлежащая изучению с целью организации управления процессами и объектами для получения бизнес-результата. Предметная область может быть разделена (декомпозирована) на фрагменты: например, предприятие — это дирекция, плановые отделы, бухгалтерия, цеха, отделы маркетинга, логистики и продаж, клиенты, поставщики и т. д. Каждый фрагмент предметной области характеризуется множеством объектов и процессов, использующих объекты, а также множеством пользователей, характеризуемых различными взглядами на предметную область и данными, которые описывают указанные составляющие предметной области . Эти данные отражают динамичную внешнюю и внутреннюю среды предприятия, поэтому в специальных разделах информационной системы необходимо создавать динамически обновляемые модели отражения внешнего мира с использованием единого хранилища — базы данных .
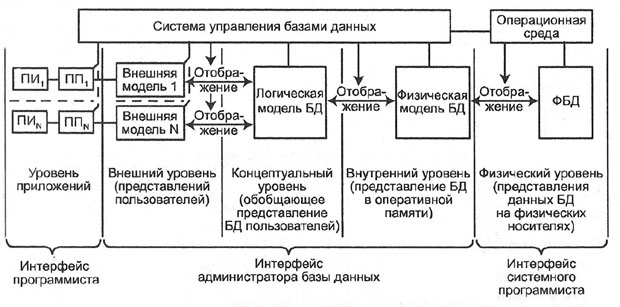
База данных, БД (Data Base) — структурированный организованный набор данных, объединенных в соответствии с некоторой выбранной моделью и описывающих характеристики какой-либо физической или виртуальной системы ( рис. 2.2).
Понятие «динамически обновляемая БД » означает, что соответствие базы данных текущему состоянию предметной области обеспечивается не периодически, а в режиме реального времени. При этом одни и те же данные могут быть по -разному представлены в соответствии с потребностями различных групп пользователей.
Система управления базами данных, СУБД (Data Base Management System) — специализированная программа или комплекс программ, предназначенные для манипулирования базой данных. Для создания информационной системы и управления ею СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор .
СУБД часто упрощенно или ошибочно называют «базой данных». Нужно различать набор данных (собственно БД ) и программное обеспечение , предназначенное для организации и ведения баз данных ( СУБД ).
Отличительной чертой баз данных следует считать то, что данные хранятся совместно с их описанием, а в прикладных программах описание данных не содержится. Независимые от программ пользователя данные обычно называются метаданными или данными о данных. В ряде современных систем метаданные , содержащие также информацию о пользователях, форматы отображения, статистику обращения к данным и др. сведения, хранятся в специальном словаре базы данных .
Организация структуры БД формируется исходя из следующих соображений:
- адекватность описываемому объекту/системе — на уровне концептуальной и логической моделей ;
- удобство использования для ведения учета и анализа данных — на уровне так называемой физической модели .
Виды концептуальных и логических моделей БД :
- картотеки;
- сетевые;
- иерархические;
- реляционные;
- дедуктивные;
- объектно-ориентированные;
- многомерные.
На уровне физической модели электронная БД представляет собой файл или набор данных в dbf-форматах приложений Excel , Access либо в специализированном формате конкретной СУБД . Также в СУБД в понятие физической модели включают специализированные виртуальные понятия, существующие в ее рамках, — » таблица «, «табличное пространство «, «сегмент», «куб», » кластер » и т. д.
В настоящее время наибольшее распространение получили реляционные базы данных . Картотеками пользовались до появления электронных баз данных. Сетевые и иерархические базы данных считаются устаревшими, объектно-ориентированные пока никак не стандартизированы и не получили широкого распространения.
Реляционная база данных — база данных , основанная на реляционной модели. Слово «реляционный» происходит от английского » relation » ( отношение ).
Теория реляционных баз данных была разработана доктором Эдгаром Коддом из компании IBM в 1970 году. В реляционных базах данных все данные представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении которых расположены данные. Запросы к таким таблицам возвращают таблицы, которые сами могут становиться предметом дальнейших запросов. Каждая база данных может включать несколько таблиц. Кратко особенности реляционной базы данных можно сформулировать следующим образом:
- данные хранятся в таблицах, состоящих из столбцов («атрибутов») и строк («записей»);
- на пересечении каждого столбца и строчки стоит в точности одно значение;
- у каждого столбца есть свое имя, которое служит его названием, и все значения в одном столбце имеют один тип;
- запросы к базе данных возвращают результат в виде таблиц, которые тоже могут выступать как объект запросов;
- строки в реляционной базе данных неупорядочены, упорядочивание производится в момент формирования ответа на запрос.
Общепринятым стандартом языка работы с реляционными базами данных в настоящее время является язык структурированных запросов ( Structured Query Language — SQL ). Это универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных . Вопреки существующим заблуждениям, SQL является информационно-логическим языком, а не языком программирования.
SQL основывается на реляционной алгебре . Язык SQL делится на три части:
- операторы определения данных;
- операторы манипуляции данными (Insert, Select, Update, Delete);
- операторы определения доступа к данным.
Основные функции системы управления базами данных :
- управление данными во внешней памяти (на различных носителях);
- управление данными в оперативной памяти;
- журналирование изменений и восстановление базы данных после сбоев;
- поддержка языков БД (язык определения данных, язык манипулирования данными, язык определения доступа к данным).
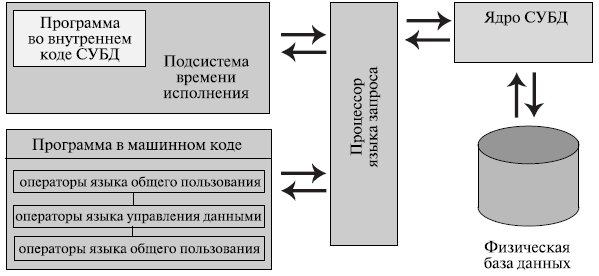
Обычно современная СУБД содержит следующие компоненты ( рис. 2.3):
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журналирование ;
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода;
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД;
- сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
По типу управляемой базы данных СУБД разделяются на иерархические, реляционные, объектно-реляционные, объектно-ориентированные, сетевые.
По архитектуре организации хранения данных:
- локальные СУБД (все части локальной СУБД размещаются на одном компьютере);
- распределенные СУБД (части СУБД могут размещаться на двух и более компьютерах).
Классификация СУБД по способу доступа к БД :
- файл-серверные ;
- клиент-серверные;
- трехзвенные;
- встраиваемые.
Файл-серверные СУБД. Архитектура » файл-сервер » не имеет сетевого разделения компонентов диалога и использует компьютер для функции отображения, что облегчает построение графического интерфейса. » Файл-сервер » только извлекает данные из файлов, так что дополнительные пользователи добавляют лишь незначительную нагрузку на центральный процессор , и каждый новый клиент добавляет вычислительную мощность сети. Минус — высокая загрузка сети. На данный момент файл-серверные СУБД считаются устаревшими. Примеры: Microsoft Access, MySQL (до версии 5.0).
Клиент-серверные СУБД. Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера. Клиент-серверные СУБД , в отличие от файл -серверных, обеспечивают разграничение доступа между пользователями и меньше загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по мере надобности его можно заменить другим. Недостаток клиент-серверных СУБД — в самом факте существования сервера (что плохо для локальных программ — в них удобнее встраиваемые СУБД ) и больших вычислительных ресурсах, потребляемых сервером. Примеры: Firebird , Interbase , MS SQL Server , Oracle , DB2 , PostgreSQL, MySQL (старше версии 5.0).
Существенным недостатком клиент-серверной архитектуры является необходимость установления прямого соединения между клиентским компьютером и базой данных. При трехзвенной архитектуре пользовательское приложение (клиент) соединяется со специально выделенным сервером приложений, и только он уже соединяется с базой данных. Кроме повышения уровня безопасности трехзвенная архитектура позволяет более гибко модернизировать приложения. Как правило, в массовой клиентской части оставляют только минимальный набор функций по доступу и отображению информации, а основную бизнес-логику реализуют в программах, запускаемых на серверах приложений . При этом модернизация обычно затрагивает только сервер приложений , а на массовых клиентских местах переустанавливать ПО не приходится.
Встраиваемая СУБД — это, как правило, «библиотека», которая позволяет унифицированным образом хранить большие объемы данных на локальной машине. Доступ к данным может происходить через SQL либо через особые функции СУБД . Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют установки сервера, поэтому востребованы в локальном ПО , которое имеет дело с большими объемами данных — например, геоинформационные системы (Geographic Informational System — GIS ). Примеры: SQLite, BerkeleyDB, один из вариантов Firebird , один из вариантов MySQL .
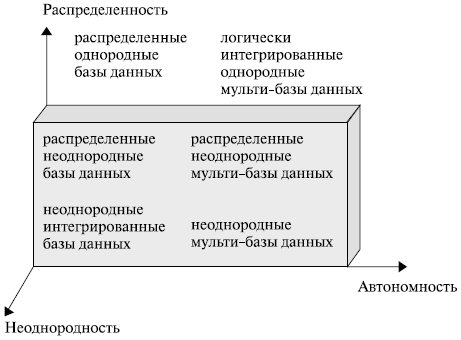
В общем случае СУБД могут быть классифицированы в системе координат «Неоднородность — Автономность -Распределенность» ( рис. 2.4).
Таким образом, распределенная обработка данных в обязательном порядке предполагает наличие банков и баз данных. Но база данных — это не просто место , куда складывают данные, ими нужно пользоваться, актуализировать, изменять форматы и связи, совершать множество других действий. Если бессистемно наполнять базу данных информацией, то через некоторое время ее невозможно будет использовать — времени на поиск нужных данных будет уходить все больше и больше, физическое пространство базы переполнится. Чтобы этого избежать, данные необходимо «очищать» и структурировать, а для эффективной работы с ними необходимы системы управления работой баз данных.
Индустрия создания баз данных и СУБД берет свое начало в 60-х годах прошлого века и к настоящему времени достаточно развита, однако понятие » хранилище данных » в современном понимании его появилось относительно недавно.
Идея хранилищ данных оказалась востребованной, так как во многих видах государственной, деловой, научной, социальной деятельности необходимы тематически объединенные и исторически очищенные совокупности данных, при этом постоянно возрастала потребность:
- в более дешевых данных;
- в точных и структурированных данных;
- в большей оперативности получения и обработки данных;
- в интегрированных данных.
К концу 1980-х годов, когда была в полной мере осознана необходимость интеграции корпоративной информации и надлежащего управления этой информацией, появились технические возможности для создания соответствующих систем, которые первоначально были названы «хранилищами информации» ( Information Warehouse — IW). И лишь в 1990-е годы, с выходом книги Уильяма (Билла) Инмона, хранилища получили свое нынешнее наименование «хранилища данных» ( Data Warehouse — DW) [Inmon W.H. Building the Data Warehouse , QED/Wiley, 1991, 312 р.].
Билл Инмон определил хранилища данных как «предметно-ориентированные, интегрированные, неизменные, поддерживающие хронологию наборы данных, организованные для целей поддержки управления, призванные выступать в роли единого и единственного источника истины, обеспечивающего менеджеров и аналитиков достоверной информацией, необходимой для оперативного анализа и принятия решений».
В основе концепции хранилищ данных лежат следующие основополагающие идеи:
- интеграция ранее разъединенных детализированных данных (исторические архивы, данные из традиционных систем обработки документов, разрозненных баз данных, данные из внешних источников) в едином хранилище данных;
- тематическое и временное структурирование, согласование и агрегирование ;
- разделение наборов данных, используемых для операционной (производственной) обработки, и наборов данных, используемых для решения задач анализа.
Данные, помещаемые в хранилище, должны отвечать определенным требованиям — предметной ориентированности, интегрированности, поддержки хронологии и неизменяемости (таблица 2.3).
| Предметная ориентированность | Все данные о некоторой сущности (бизнес-объекте, бизнес-процессе и т. д.) из некоторой предметной области собираются из множества различных источников, очищаются, согласовываются, дополняются, агрегируются и представляются в единой, удобной для их использования в бизнес-анализе форме |
| Интегрированность | Все данные о различных бизнес-объектах взаимно согласованы и хранятся в едином общекорпоративном хранилище |
| Поддержка хронологии | Данные хронологически структурированы и отражают историю за период времени, достаточный для выполнения задач бизнес-анализа, прогнозирования и подготовки принятия решения |
| Неизменяемость | Исходные (исторические) данные, после того как они были согласованы, верифицированы и внесены в общекорпоративное хранилище, остаются неизменными и используются исключительно в режиме чтения |
Хранилище данных выполняет множество функций, но его основное предназначение — предоставление точных данных и информации в кратчайшие сроки и с минимумом затрат.
Понятие хранилище данных в первоначальном понимании было основано на понятии распределенной витрины данных ( Distributed Data Mart — DDM ). Поэтому в классическом исполнении хранилище данных было прежде всего репозиторием (сквозной базой данных) данных и информации предприятия.
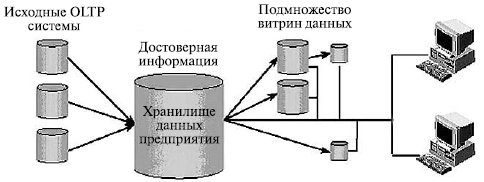
Среда хранилища была предназначена только для чтения и состояла из детальных и агрегированных данных, которые полностью очищены и интегрированы; кроме того, в репозитории хранилась обширная и детальная история данных на уровне транзакций. С точки зрения архитектурного решения такое хранилище данных реализует свои функции через подмножество зависимых витрин данных ( рис. 2.5).
Достоинствами архитектуры классического хранилища данных являются:
- общая семантика;
- централизованная, управляемая среда;
- согласованный набор процессов извлечения и бизнес-логики использования;
- непротиворечивость содержащейся информации;
- легко создаваемые по шаблонам и наполняемые витрины данных;
- единый репозиторий метаданных ;
- многообразие механизмов обработки и представления данных.
К недостаткам можно отнести большие затраты по реализации, высокую ресурсоемкость в масштабе всего предприятия, потребность в сложных сервисных системах, рискованный сценарий развития, когда все данные и метаданные находятся в одном репозитории и в неблагоприятном случае могут быть потеряны. Кроме того, при фильтрации, агрегировании и рафинировании «сырых» данных для такого хранилища обычно теряется очень много информации, которая может быть чрезвычайно полезной при бизнес-анализе. В связи с этим возникло понимание того, что хранилище, помимо механизмов размещения и извлечения данных (On Line Transactional Processing — OLTP ), репозитория и витрин, должно иметь соответствующее пространство для организации «сырых» данных и их многомерного анализа в режиме реального времени (On Line Analytical Processing — OLAP ).
Источник



