
Аналитические методы шифрования




![]()
Для шифрования информации могут использоваться аналитические преобразования [8]. Наибольшее распространение получили методы шифрования, основанные на использовании матричной алгебры. Зашифрование k-го блока исходной информации, представленного в виде вектора Вk = ||bj|| , осуществляется путем перемножения матрицы-ключа А= ||аij|| и вектора Bk;. В результате перемножения получается блок шифртекста в виде вектора Ck = ||ci||, где элементы вектора Сk определяются по формуле:
Расшифрование информации осуществляется путем последовательного перемножения векторов Ck и матрицы А — 1 , обратной матрице А.
Пример шифрования информации с использованием алгебры матриц.
Пусть необходимо зашифровать и расшифровать слово
Т0 = с помощью матрицы-ключа А:
Для зашифрования исходного слова необходимо выполнить следующие шаги.
Шаг 1. Определяется числовой эквивалент исходного слова как последовательность соответствующих порядковых номеров букв слова ТЭ:
| 1 4 8 | × | 8 | = | 28 |
С1 = | 3 7 2 | × | 1 | = | 35 |;
| 6 9 5 | × | 2 | = | 67 |
| 1 4 8 | × | 1 | = | 21 |
С1 = | 3 7 2 | × | 3 | = | 26 |.
| 6 9 5 | × | 1 | = | 38 |
Шаг З. Зашифрованное слово записывается в виде последовательности чисел Т1 = .
Расшифрование слова осуществляется следующим образом.
Шаг 1. Вычисляется определитель |А |= — 115.
Шаг 2. Определяется присоединенная матрица А*, каждый элемент которой является алгебраическим дополнением элемента aij матрицы А
Шаг 3. Получается транспонированная матрица А
Шаг 4. Вычисляется обратная матрица А — 1 по формуле:
В результате вычислений обратная матрица имеет вид:
| -17/115 -52/115 48/115 |
А – 1 = | 3/115 43/115 -22/115 |
| 15/115 -15/115 5/115 |
Шаг 5. Определяются векторы B1 и В2:
| 17/115 -52/115 48/115 | | 28 | = | 8 |
B1 = | 3/115 43/115 -22/115 | × | 35 | = | 1 |.
| 15/115 -15/115 5/115 | | 67 | = | 2 |
| 17/115 -52/115 48/115 | | 21 | = | 1 |
B2 = | 3/115 43/115 -22/115 | × | 26 | = | 3 |.
| 15/115 -15/115 5/115 | | 38 | = | 1 |
Шаг 6. Числовой эквивалент расшифрованного слова ТЭ = заменяется символами, в результате чего получается исходное слово Т0 = .
11.1.3.4. Аддитивные методы шифрования
Сущность аддитивных методов шифрования заключается в последовательном суммировании цифровых кодов, соответствующих символам исходной информации, с последовательностью кодов, которая соответствует некоторому кортежу символов [56]. Этот кортеж называется гаммой. Поэтому аддитивные методы шифрования называют также гаммированием.
Для данных методов шифрования ключом является гамма. Криптостойкость аддитивных методов зависит от длины ключа и равномерности его статистических характеристик. Если ключ короче, чем шифруемая последовательность символов, то шифртекст может быть расшифрован криптоаналитиком статистическими методами исследования. Чем больше разница длин ключа и исходной информации, тем выше вероятность успешной атаки на шифртекст. Если ключ представляет собой непериодическую последовательность случайных чисел, длина которой превышает длину шифруемой информации, то без знания ключа расшифровать шифртекст практически невозможно. Как и для методов замены в качестве ключа могут использоваться неповторяющиеся последовательности цифр, например, в числах p, e и других.
На практике самыми эффективными и распространенными являются аддитивные методы, в основу которых положено использование генераторов (датчиков) псевдослучайных чисел. Генератор использует исходную информацию относительно малой длины для получения практически бесконечной последовательности псевдослучайных чисел.
Для получения последовательности псевдослучайных чисел (ПСЧ) могут использоваться конгруэнтные генераторы. Генераторы этого класса вырабатывают псевдослучайные последовательности чисел, для которых могут быть строго математически определены такие основные характеристики генераторов как периодичность и случайность выходных последовательностей.
Среди конгруэнтных генераторов ПСЧ выделяется своей простотой и эффективностью линейный генератор, вырабатывающий псевдослучайную последовательность чисел T(i) в соответствии с соотношением

где а и с — константы, Т(0) — исходная величина, выбранная в качестве порождающего числа.
Период повторения такого датчика ПСЧ зависит от величин а и с. Значение т обычно принимается равным 2 s , где s — длина слова ЭВМ в битах. Период повторения последовательности генерируемых чисел будет максимальным тогда и только тогда, когда с — нечетное число и a (mod 4) = 1 [39]: Такой генератор может быть сравнительно легко создан как аппаратными средствами, так и программно.
11.1.4. Системы шифрования с открытым ключом
Наряду с традиционным шифрованием на основе секретного ключа в последние годы «все большее признание получают системы шифрования с открытым ключом. В таких системах используются два ключа. Информация шифруется с помощью открытого ключа, а расшифровывается с использованием секретного ключа.
В основе применения систем с открытым ключом лежит использование необратимых или односторонних функций [8]. Эти функции обладают следующим свойством. По известному x легко определяется функция у = f(x). Но по известному значению у практически невозможно получить x. В криптографии используются односторонние функции, имеющие так называемый потайной ход. Эти функции с параметром z обладают следующими свойствами. Для определенного z могут быть найдены алгоритмы Ez и Dz. С помощью Ez легко получить функцию f(x) для всех x из области определения. Так же просто с помощью алгоритма Dz получается и обратная функция x = f 1 (у) для всех у из области допустимых значений. В то же время практически для всех z и почти для всех у из области допустимых значений нахождение f –1 (x) при помощи вычислений невозможно даже при известном Ez. В качестве открытого ключа используется у, а в качестве закрытого — x.
При шифровании с использованием открытого ключа нет необходимости в передаче сек-
ретного ключа между взаимодействующими субъектами, что существенно упрощает криптозащиту передаваемой информации.
Криптосистемы с открытыми ключами различаются видом односторонних функций. Среди них самыми известными являются системы RSA, Эль-Гамаля и Мак-Элиса. В настоящее время наиболее эффективным и распространенным алгоритмом шифрования с открытым ключом является алгоритм RSA, получивший свое название от первых букв фамилий его создателей: Rivest, Shamir и Adleman.
Алгоритм основан на использовании операции возведения в степень модульной арифметики. Его можно представить в виде следующей последовательности шагов [39].
Шаг 1. Выбираются два больших простых числа p и q. Простыми называются числа, которые делятся только на самих себя и на 1. Величина этих чисел должна быть больше 200.
Шаг 2. Получается открытая компонента ключа n:
Шаг 3. Вычисляется функция Эйлера по формуле:
Функция Эйлера показывает количество целых положительных чисел от 1 до п, которые взаимно просты с п. Взаимно простыми являются такие числа, которые не имеют ни одного общего делителя, кроме 1.
Шаг 4. Выбирается большое простое число d, которое является взаимно простым со значением f(p, q).
Шаг 5. Определяется число e, удовлетворяющее условию: e d = 1 (mod f(p, q)).
Данное условие означает, что остаток от деления (вычет) произведения e d на функцию f(p, q) равен 1. Число e принимается в качестве второй компоненты открытого ключа. В качестве секретного ключа используются числа d и п.
Шаг 6. Исходная информация, независимо от ее физической природы, представляется в числовом двоичном виде. Последовательность бит разделяется на блоки длиной L бит, где L — наименьшее целое число, удовлетворяющее условию: L ³ log2(n+1). Каждый блок рассматривается как целое положительное число X(i), принадлежащее интервалу [0,n-1]. Таким образом, исходная информация представляется последовательностью чисел Х(i), i=1,I. Значение I определяется длиной шифруемой последовательности.
Шаг 7. Зашифрованная информация получается в виде последовательности чисел Y(i), вычисляемых по формуле:
Шаг 8. Для расшифрования информации используется следующая зависимость:
Пример применения метода RSA для криптографического закрытия информации. Примечание: для простоты вычислений использованы минимально возможные числа.
Пусть требуется зашифровать сообщение на русском языке «ГАЗ».
Для зашифрования и расшифрования сообщения необходимо выполнить следующие шаги.
Шаг 1. Выбирается p=3 и q = 11.
Шаг 2. Вычисляется n = 3×11=33.
Шаг 3. Определяется функция Эйлера
Шаг 4. В качестве взаимно простого числа выбирается число d=3.
Шаг 5. Выбирается такое число e, которое удовлетворяло бы соотношению: (е×3) (mod 20) = 1. Пусть e = 7.
Шаг 6. Исходное сообщение представляется как последовательность целых чисел. Пусть букве А соответствует число 1, букве Г — число 4, букве З — число 9. Для представления чисел в двоичном коде требуется 6 двоичных разрядов, так как в русском алфавите используются 33 буквы (случайное совпадение с числом n). Исходная информация в двоичном коде имеет вид:
Длина блока L определяется как минимальное число из целых чисел, удовлетворяющих условию: L ³ log2(n+1) = log2(33+1), так как n = 33. Отсюда L=6. Тогда исходный текст представляется в виде кортежа X(i) = .
Шаг 7. Кортеж X(i) зашифровывается с помощью открытого ключа <7, 33>:
Y(1) = (4 7 ) (mod 33) = 16384 (mod 33) = 16;
Y(2) = (I 7 ) (mod 33) = 1 (mod 33) = 1;
Y(3) = (9 7 ) (rood 33) = 4782969 (mod 33) = 15.
Получено зашифрованное сообщение Y(i) = .
Шаг 8. Расшифровка сообщения Y(i) = осуществляется с помощью секретного ключа <3, 33>:
Х(1) = (16 3 ) (mod 33) = 4096 (mod 33) = 4;
X(2) = (I 3 ) (mod 33) = 1 (mod 33) = 1;
Х(3) = (15 3 ) (mod 33) = 3375 (mod 33) = 9.
Исходная числовая последовательность в расшифрованном виде Х(i) = заменяется исходным текстом «ГАЗ».
Система Эль-Гамаля основана на сложности вычисления дискретных логарифмов в конечных полях [22]. Основным недостатком систем RSA и Эль-Гамаля является необходимость выполнения трудоемких операций в модульной арифметике, что требует привлечения значительных вычислительных ресурсов.
Криптосистема Мак-Элиса использует коды, исправляющие ошибки. Она реализуется в несколько раз быстрее, чем криптосистема RSA, но имеет и существенный недостаток. В криптосистеме Мак-Элиса используется ключ большой длины и получаемый шифртекст в два раза превышает длину исходного текста.
Для всех методов шифрования с открытым ключом математически строго не доказано отсутствие других методов криптоанализа кроме решения NP-полной задачи (задачи полного перебора). Если появятся методы эффективного решения таких задач, то криптосистемы такого типа будут дискредитированы. Например, ранее считалось, что задача укладки рюкзака является NP-полной. В настоящее время известен метод решения такой задачи, позволяющий избежать полного перебора.
Источник
Классический криптоанализ

На протяжении многих веков люди придумывали хитроумные способы сокрытия информации — шифры, в то время как другие люди придумывали еще более хитроумные способы вскрытия информации — методы взлома.
В этом топике я хочу кратко пройтись по наиболее известным классическим методам шифрования и описать технику взлома каждого из них.
Шифр Цезаря
Самый легкий и один из самых известных классических шифров — шифр Цезаря отлично подойдет на роль аперитива.
Шифр Цезаря относится к группе так называемых одноалфавитных шифров подстановки. При использовании шифров этой группы «каждый символ открытого текста заменяется на некоторый, фиксированный при данном ключе символ того же алфавита» wiki.
Способы выбора ключей могут быть различны. В шифре Цезаря ключом служит произвольное число k, выбранное в интервале от 1 до 25. Каждая буква открытого текста заменяется буквой, стоящей на k знаков дальше нее в алфавите. К примеру, пусть ключом будет число 3. Тогда буква A английского алфавита будет заменена буквой D, буква B — буквой E и так далее.
Для наглядности зашифруем слово HABRAHABR шифром Цезаря с ключом k=7. Построим таблицу подстановок:
| a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z |
| h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z | a | b | c | d | e | f | g |
И заменив каждую букву в тексте получим: C(‘HABRAHABR’, 7) = ‘OHIYHOHIY’.
При расшифровке каждая буква заменяется буквой, стоящей в алфавите на k знаков раньше: D(‘OHIYHOHIY’, 7) = ‘HABRAHABR’.
Криптоанализ шифра Цезаря
Малое пространство ключей (всего 25 вариантов) делает брут-форс самым эффективным и простым вариантом атаки.
Для вскрытия необходимо каждую букву шифртекста заменить буквой, стоящей на один знак левее в алфавите. Если в результате этого не удалось получить читаемое сообщение, то необходимо повторить действие, но уже сместив буквы на два знака левее. И так далее, пока в результате не получится читаемый текст.
Аффиный шифр
Рассмотрим немного более интересный одноалфавитный шифр подстановки под названием аффиный шифр. Он тоже реализует простую подстановку, но обеспечивает немного большее пространство ключей по сравнению с шифром Цезаря. В аффинном шифре каждой букве алфавита размера m ставится в соответствие число из диапазона 0… m-1. Затем при помощи специальной формулы, вычисляется новое число, которое заменит старое в шифртексте.
Процесс шифрования можно описать следующей формулой:
 ,
,
где x — номер шифруемой буквы в алфавите; m — размер алфавита; a, b — ключ шифрования.
Для расшифровки вычисляется другая функция:
,
где a -1 — число обратное a по модулю m. Это значит, что для корректной расшифровки число a должно быть взаимно простым с m.
С учетом этого ограничения вычислим пространство ключей аффиного шифра на примере английского алфавита. Так как английский алфавит содержит 26 букв, то в качестве a может быть выбрано только взаимно простое с 26 число. Таких чисел всего двенадцать: 1, 3, 5, 7, 9, 11, 15, 17, 19, 21, 23 и 25. Число b в свою очередь может принимать любое значение в интервале от 0 до 25, что в итоге дает нам 12*26 = 312 вариантов возможных ключей.
Криптоанализ аффиного шифра
Очевидно, что и в случае аффиного шифра простейшим способом взлома оказывается перебор всех возможных ключей. Но в результате перебора получится 312 различных текстов. Проанализировать такое количество сообщений можно и в ручную, но лучше автоматизировать этот процесс, используя такую характеристику как частота появления букв.
Давно известно, что буквы в естественных языках распределены не равномерно. К примеру, частоты появления букв английского языка в текстах имеют следующие значения:

Т.е. в английском тексте наиболее встречающимися буквами будут E, T, A. В то время как самыми редкими буквами являются J, Q, Z. Следовательно, посчитав частоту появления каждой буквы в тексте мы можем определить насколько частотная характеристика текста соответствует английскому языку.
Для этого необходимо вычислить значение:
,
где ni — частота i-й буквы алфавита в естественном языке. И fi — частота i-й буквы в шифртексте.
Чем больше значение χ, тем больше вероятность того, что текст написан на естественном языке.
Таким образом, для взлома аффиного шифра достаточно перебрать 312 возможных ключей и вычислить значение χ для полученного в результате расшифровки текста. Текст, для которого значение χ окажется максимальным, с большой долей вероятности и является зашифрованным сообщением.
Разумеется следует учитывать, что метод не всегда работает с короткими сообщениями, в которых частотные характеристики могут сильно отличатся от характеристик естественного языка.
Шифр простой замены
Очередной шифр, относящийся к группе одноалфавитных шифров подстановки. Ключом шифра служит перемешанный произвольным образом алфавит. Например, ключом может быть следующая последовательность букв: XFQABOLYWJGPMRVIHUSDZKNTEC.
При шифровании каждая буква в тексте заменяется по следующему правилу. Первая буква алфавита замещается первой буквой ключа, вторая буква алфавита — второй буквой ключа и так далее. В нашем примере буква A будет заменена на X, буква B на F.
При расшифровке буква сперва ищется в ключе и затем заменяется буквой стоящей в алфавите на той же позиции.
Криптоанализ шифра простой замены
Пространство ключей шифра простой замены огромно и равно количеству перестановок используемого алфавита. Так для английского языка это число составляет 26! = 2 88 . Разумеется наивный перебор всех возможных ключей дело безнадежное и для взлома потребуется более утонченная техника, такая как поиск восхождением к вершине:
- Выбирается случайная последовательность букв — основной ключ. Шифртекст расшифровывается с помощью основного ключа. Для получившегося текста вычисляется коэффициент, характеризующий вероятность принадлежности к естественному языку.
- Основной ключ подвергается небольшим изменениям (перестановка двух произвольно выбранных букв). Производится расшифровка и вычисляется коэффициент полученного текста.
- Если коэффициент выше сохраненного значения, то основной ключ заменяется на модифицированный вариант.
- Шаги 2-3 повторяются пока коэффициент не станет постоянным.
Для вычисления коэффициента используется еще одна характеристика естественного языка — частота встречаемости триграмм.
Чем ближе текст к английскому языку тем чаще в нем будут встречаться такие триграммы как THE, AND, ING. Суммируя частоты появления в естественном языке всех триграмм, встреченных в тексте получим коэффициент, который с большой долей вероятности определит текст, написанный на естественном языке.
Шифр Полибия
Еще один шифр подстановки. Ключом шифра является квадрат размером 5*5 (для английского языка), содержащий все буквы алфавита, кроме J.
При шифровании каждая буква исходного текста замещается парой символов, представляющих номер строки и номер столбца, в которых расположена замещаемая буква. Буква a будет замещена в шифртексте парой BB, буква b — парой EB и так далее. Так как ключ не содержит букву J, перед шифрованием в исходном тексте J следует заменить на I.
Например, зашифруем слово HABRAHABR. C(‘HABRAHABR’) = ‘AB BB EB DA BB AB BB EB DA’.
Криптоанализ шифра Полибия
Шифр имеет большое пространство ключей (25! = 2 83 для английского языка). Однако единственное отличие квадрата Полибия от предыдущего шифра заключается в том, что буква исходного текста замещается двумя символами.
Поэтому для атаки можно использовать методику, применяемую при взломе шифра простой замены — поиск восхождением к вершине.
В качестве основного ключа выбирается случайный квадрат размером 5*5. В ходе каждой итерации ключ подвергается незначительным изменениям и проверяется насколько распределение триграмм в тексте, полученном в результате расшифровки, соответствует распределению в естественном языке.
Перестановочный шифр
Помимо шифров подстановки, широкое распространение также получили перестановочные шифры. В качестве примера опишем Шифр вертикальной перестановки.
В процессе шифрования сообщение записывается в виде таблицы. Количество колонок таблицы определяется размером ключа. Например, зашифруем сообщение WE ARE DISCOVERED. FLEE AT ONCE с помощью ключа 632415.
Так как ключ содержит 6 цифр дополним сообщение до длины кратной 6 произвольно выбранными буквами QKJEU и запишем сообщение в таблицу, содержащую 6 колонок, слева направо:

Для получения шифртекста выпишем каждую колонку из таблицы в порядке, определяемом ключом: EVLNE ACDTK ESEAQ ROFOJ DEECU WIREE.
При расшифровке текст записывается в таблицу по колонкам сверху вниз в порядке, определяемом ключом.
Криптоанализ перестановочного шифра
Лучшим способом атаки шифра вертикальной перестановки будет полный перебор всех возможных ключей малой длины (до 9 включительно — около 400 000 вариантов). В случае, если перебор не дал желаемых результатов, можно воспользоваться поиском восхождением к вершине.
Для каждого возможного значения длины осуществляется поиск наиболее правдоподобного ключа. Для оценки правдоподобности лучше использовать частоту появления триграмм. В результате возвращается ключ, обеспечивающий наиболее близкий к естественному языку текст расшифрованного сообщения.
Шифр Плейфера
Шифр Плейфера — подстановочный шифр, реализующий замену биграмм. Для шифрования необходим ключ, представляющий собой таблицу букв размером 5*5 (без буквы J).
Процесс шифрования сводится к поиску биграммы в таблице и замене ее на пару букв, образующих с исходной биграммой прямоугольник.
Рассмотрим, в качестве примера следующую таблицу, образующую ключ шифра Плейфера:
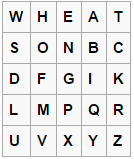
Зашифруем пару ‘WN’. Буква W расположена в первой строке и первой колонке. А буква N находится во второй строке и третьей колонке. Эти буквы образуют прямоугольник с углами W-E-S-N. Следовательно, при шифровании биграмма WN преобразовывается в биграмму ES.
В случае, если буквы расположены в одной строке или колонке, результатом шифрования является биграмма расположенная на одну позицию правее/ниже. Например, биграмма NG преобразовывается в биграмму GP.
Криптоанализ шифра Плейфера
Так как ключ шифра Плейфера представляет собой таблицу, содержащую 25 букв английского алфавита, можно ошибочно предположить, что метод поиска восхождением к вершине — лучший способ взлома данного шифра. К сожалению, этот метод не будет работать. Достигнув определенного уровня соответствия текста, алгоритм застрянет в точке локального максимума и не сможет продолжить поиск.
Чтобы успешно взломать шифр Плейфера лучше воспользоваться алгоритмом имитации отжига.
Отличие алгоритма имитации отжига от поиска восхождением к вершине заключается в том, что последний на пути к правильному решению никогда не принимает в качестве возможного решения более слабые варианты. В то время как алгоритм имитации отжига периодически откатывается назад к менее вероятным решениям, что увеличивает шансы на конечный успех.
Суть алгоритма сводится к следующим действиям:
- Выбирается случайная последовательность букв — основной-ключ. Шифртекст расшифровывается с помощью основного ключа. Для получившегося текста вычисляется коэффициент, характеризующий вероятность принадлежности к естественному языку.
- Основной ключ подвергается небольшим изменениям (перестановка двух произвольно выбранных букв, перестановка столбцов или строк). Производится расшифровка и вычисляется коэффициент полученного текста.
- Если коэффициент выше сохраненного значения, то основной ключ заменяется на модифицированный вариант.
- В противном случае замена основного ключа на модифицированный происходит с вероятностью, напрямую зависящей от разницы коэффициентов основного и модифицированного ключей.
- Шаги 2-4 повторяются около 50 000 раз.
Алгоритм периодически замещает основной ключ, ключом с худшими характеристиками. При этом вероятность замены зависит от разницы характеристик, что не позволяет алгоритму принимать плохие варианты слишком часто.
Для расчета коэффициентов, определяющих принадлежность текста к естественному языку лучше всего использовать частоты появления триграмм.
Шифр Виженера
Шифр Виженера относится к группе полиалфавитных шифров подстановки. Это значит, что в зависимости от ключа одна и та же буква открытого текста может быть зашифрована в разные символы. Такая техника шифрования скрывает все частотные характеристики текста и затрудняет криптоанализ.
Шифр Виженера представляет собой последовательность нескольких шифров Цезаря с различными ключами.
Продемонстрируем, в качестве примера, шифрование слова HABRAHABR с помощью ключа 123. Запишем ключ под исходным текстом, повторив его требуемое количество раз:
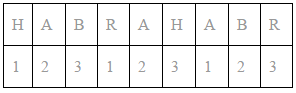
Цифры ключа определяют на сколько позиций необходимо сдвинуть букву в алфавите для получения шифртекста. Букву H необходимо сместить на одну позицию — в результате получается буква I, букву A на 2 позиции — буква C, и так далее. Осуществив все подстановки, получим в результате шифртекст: ICESCKBDU.
Криптоанализ шифра Виженера
Первая задача, стоящая при криптоанализе шифра Виженера заключается в нахождении длины, использованного при шифровании, ключа.
Для этого можно воспользоваться индексом совпадений.
Индекс совпадений — число, характеризующее вероятность того, что две произвольно выбранные из текста буквы окажутся одинаковы.
Для любого текста индекс совпадений вычисляется по формуле:
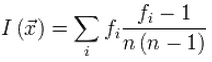 ,
,
где fi — количество появлений i-й буквы алфавита в тексте, а n — количество букв в тексте.
Для английского языка индекс совпадений имеет значение 0.0667, в то время как для случайного набора букв этот показатель равен 0.038.
Более того, для текста зашифрованного с помощью одноалфавитной подстановки, индекс совпадений также равен 0.0667. Это объясняется тем, что количество различных букв в тексте остается неизменным.
Это свойство используется для нахождения длины ключа шифра Виженера. Из шифртекста по очереди выбираются каждая вторая буквы и для полученного текста считается индекс совпадений. Если результат примерно соответствует индексу совпадений естественного языка, значит длина ключа равна двум. В противном случае из шифртекста выбирается каждая третья буква и опять считается индекс совпадений. Процесс повторяется пока высокое значение индекса совпадений не укажет на длину ключа.
Успешность метода объясняется тем, что если длина ключа угадана верно, то выбранные буквы образуют шифртекст, зашифрованный простым шифром Цезаря. И индекс совпадений должен быть приблизительно соответствовать индексу совпадений естественного языка.
После того как длина ключа будет найдена взлом сводится к вскрытию нескольких шифров Цезаря. Для этого можно использовать способ, описанный в первом разделе данного топика.
Исходники всех вышеописанных шифров и атак на них можно посмотреть на GitHub.
Источник



