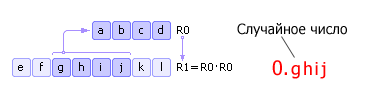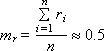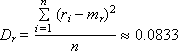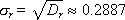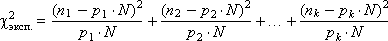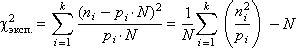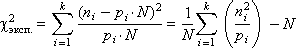- Тесты — Упрощенная генерация случайных чисел
- Алгоритм Лемера
- Алгоритм Вичмана-Хилла
- Линейный конгруэнтный алгоритм
- Алгоритм Фибоначчи с запаздываниями
- Заключение
- Лекция 22. Генераторы случайных чисел
- Физические ГСЧ
- Табличные ГСЧ
- Алгоритмические ГСЧ
- Метод серединных квадратов
- Метод серединных произведений
- Метод перемешивания
- Линейный конгруэнтный метод
- Проверка качества работы генератора
- Проверки на равномерность распределения
- Проверки на статистическую независимость
Тесты — Упрощенная генерация случайных чисел
.png) Случайные числа используются во многих алгоритма х машинного обучения. Например, распространенной задачей является выбор случайной строки матрицы. В C# код может выглядеть так:
Случайные числа используются во многих алгоритма х машинного обучения. Например, распространенной задачей является выбор случайной строки матрицы. В C# код может выглядеть так:
В этой статье я покажу, как генерировать случайные числа с помощью четырех разных алгоритмов: алгоритма Лемера (Lehmer), линейного конгруэнтного алгоритма ( linear congruential algorithm), алгоритма Вичмана-Хилла (Wichmann-Hill) и алгоритма Фибоначчи с запаздываниями (lagged Fibonacci algorithm).
Но зачем обременять себя созданием собственного генератора случайных чисел (random number generator, RNG), когда в Microsoft .NET Framework уже есть эффективный и простой в использовании класс Random? Существует два сценария, где вам может понадобиться создать свой RNG. Во-первых, в разные языки программирования встроены разные алгоритмы генерации случайных чисел, а значит, если вы пишете код, который будет переноситься на несколько языков, можно создать собственный RNG, чтобы реализовать его во всех нужных вам языках. Во-вторых, некоторые языки, в частности R, имеют лишь глобальный RNG, поэтому, если вы захотите создать несколько генераторов, вам придется писать свой RNG.
Хороший способ получить представление о том, куда я клоню в этой статье, — взглянуть на демонстрационную программу на рис. 1. Демонстрационная программа начинает с создания очень простого RNGЮ используя алгоритм Лемера. Затем с помощью RNG генерируется 1000 случайных целых чисел между 0 и 9 включительно. За кулисами записываются счетчики для каждого из сгенерированных целых чисел, которые потом отображаются на экране. Этот процесс повторяется для линейного конгруэнтного алгоритма, алгоритма Вичмана-Хилла и алгоритм Фибоначчи с запаздываниями.
.png)
Рис. 1. Демонстрация упрощенной генерации случайных чисел
В этой статье предполагается, что вы умеете программировать хотя бы на среднем уровне, но ничего не знаете о генерации случайных чисел. Демонстрационная программа написана на C#, но, поскольку один из основных случаев использования собственной генерации случайных чисел — написание портируемого кода, эта программа разработана так, чтобы ее можно было легко транслировать на другие языки.
Алгоритм Лемера
Самый простой приемлемый метод генерации случайных чисел — алгоритм Лемера. (Для простоты я использую термин «генерация случайных чисел» вместо более точного термина «генерация псевдослучайных чисел».) Выраженный в символьном виде, алгоритм Лемера представляет собой следующее:
На словах это звучит так: «новое случайное число является старым случайным числом, умножаемым на константу a, после чего над результатом выполняется операция по модулю константы m». Например, предположим, что в некий момент текущее случайное число равно 104, a = 3 и m = 100. Тогда новое случайное число будет равно 3 * 104 mod 100 = 312 mod 100 = 12. Вроде бы просто, но в реализации этого алгоритма много хитроумных деталей.
Чтобы создать демонстрационную программу, я запустил Visual Studio, выбрал шаблон C# Console Application и назвал проект RandomNumbers. В этой программе нет значимых зависимостей от .NET Framework, поэтому подойдет любая версия Visual Studio.
После загрузки кода шаблона в окно редактора я переименовал в окне Solution Explorer файл Program.cs в более описательный RandomNumbersProgram.cs, и Visual Studio автоматически переименовала класс Program за меня. В начале кода я удалил все лишние выражения using, оставив только ссылки на пространства имен верхнего уровня System и Collections.Generic.
Затем я добавил класс с именем LehmerRng для реализации RNG-алгоритма Лемера. Код показан на рис. 2. Версия алгоритма Лемера за 1988 год использует a = 16807 и m = 2147483647 (которое является int.MaxValue). Позднее, в 1993 году Лемер предложил другую версию, где a = 48271 как чуть более качественную альтернативу. Эти значения берутся из математической теории. Демонстрационный код основан на знаменитой статье С. К. Парка (S. K. Park) и К. У. Миллера (K. W. Miller) «Random Number Generators: Good Ones Are Hard to Find».
Рис. 2. Реализация алгоритма Лемера
Проблема реализации в том, чтобы предотвращать арифметическое переполнение. Алгоритм Лемера использует ловкий алгебраический трюк. Значение q является результатом m / a (целочисленное деление), а значение r равно m % a (m по модулю a).
При инициализации RNG Лемера начальным (зародышевым) значением можно использовать любое целое число в диапазоне [1, int.MaxValue – 1]. Многие RNG имеют конструктор без параметров, который получает системные дату и время, преобразует их в целое число и использует в качестве начального значения.
RNG Лемера вызывается в методе Main демонстрационной программы:
Каждый вызов метода Next возвращает значение в диапазоне [0.0, 1.0) — больше или равно 0.0 и строго меньше 1.0. Шаблон (int)(hi – lo) * Next + lo) будет возвращать целое число в диапазоне [lo, hi–1].
Алгоритм Лемера весьма эффективен, и в простых сценариях я обычно выбираю именно его. Но заметьте, что ни один алгоритм из представленных в этой статье не обладает надежностью криптографического уровня и что их следует применять только в ситуациях, где не требуется статической строгости (statistical rigor).
Алгоритм Вичмана-Хилла
Этот алгоритм датируется 1982 годом. Идея Вичмана-Хилла заключается в генерации трех предварительных результатов и последующего их объединения в один финальный результат. Код, реализующий алгоритм Вичмана-Хилла, представлен на рис. 3. Демонстрационный код основан на статье Б. А. Вичмана (B. A. Wichmann) и А. Д. Хилла (I. D. Hill) «Algorithm AS 183: An Efficient and Portable Pseudo-Random Number Generator».
Рис. 3. Реализация алгоритма Вичмана-Хилла
Поскольку алгоритм Вичмана-Хилла использует три разных генерирующих уравнения, он требует трех начальных значений. В этом алгоритме три m-значения равны 30269, 30307 и 30323, поэтому вам понадобятся три начальных значения в диапазоне [1, 30000]. Вы могли бы написать конструктор, принимающий эти три значения, но тогда вы получили бы несколько раздражающий программный интерфейс. В демонстрации применяется параметр с одним начальным значением, генерирующим три рабочих зародыша.
Вызов RNG Вичмана-Хилла осуществляется по тому же шаблону, что и других демонстрационных RNG:
Алгоритм Вичмана-Хилла лишь немного труднее в реализации, чем алгоритм Лемера. Преимущество первого над вторым в том, что алгоритм Вичмана-Хилла генерирует более длинную последовательность (более 6 000 000 000 000 значений) до того, как начнет повторяться.
Линейный конгруэнтный алгоритм
Оказывается, и алгоритм Лемера, и алгоритм Вичмана-Хилла можно считать особыми случаями так называемого линейного конгруэнтного алгоритма (linear congruential, LC). Выраженный в виде уравнения, LC выглядит так:
Это точно соответствует алгоритму Лемера с добавлением дополнительной константы c. Включение c придает универсальному LC-алгоритму несколько лучшие статистические свойства по сравнению с алгоритмом Лемера. Демонстрационная реализация LC-алгоритма показана на рис. 4. Код основан на стандарте POSIX (Portable Operating System Interface).
Рис. 4. Реализация линейного конгруэнтного алгоритма
LC-алгоритм использует несколько битовых операций. Здесь идея в том, чтобы в базовых математических типах работать не с целым типом (32 бита), а с длинным целым (64 бита). По окончании 32 из этих битов (с 16-го по 47-й включительно) извлекаются и преобразуются в целое число. Этот подход дает более качественные результаты, чем при использовании просто 32 младших или старших битов, но за счет некоторого усложнения кодирования.
В демонстрации генератор случайных чисел LC вызывается так:
Заметьте, что в отличие от генераторов Лемера и Вичмана-Хилла генератор LC может принимать начальное значение 0. Конструктор в демонстрации LC копирует значение входного параметра seed непосредственно в член класса — поле seed. Многие распространенные реализации LC выполняют предварительные манипуляции над входным начальным значением, чтобы избежать генерации хорошо известных серий начальных значений.
Алгоритм Фибоначчи с запаздываниями
Этот алгоритм, выраженный уравнением, выглядит так:
Если на словах, то новое случайное число является тем, которое было сгенерировано 7 раз назад, плюс случайное число, сгенерированное 10 раз назад, и деленное по модулю на большое значение m. Значения (7, 10) можно изменять, как я вскоре поясню.
Допустим, что в некий момент времени последовательность сгенерированных чисел следующая:
где 561 — самое последнее из сгенерированных значений. Если m = 100, то следующим случайным числом будет:
Заметьте, что в любой момент вам всегда нужны 10 самых последних сгенерированных значений. Поэтому ключевая задача в алгоритме Фибоначчи с запаздываниями состоит в генерации начальных значений, необходимых для запуска процесса. Демонстрационная реализация алгоритма Фибоначчи с запаздываниями приведена на рис. 5.
Рис. 5. Реализация алгоритма Фибоначчи с запаздываниями
Демонстрационный код использует предыдущие случайные числа X(i–7) и X(i–10) для генерации следующего случайного числа. В научно-исследовательской литературе по этой тематике значения (7, 10) обычно обозначаются (j, k). Существуют другие пары (j, k), которые можно применять для алгоритма Фибоначчи с запаздываниями. Несколько значений, рекомендованных в хорошо известной книге «Art of Computer Programming» (Addison-Wesley, 1968), — (24,55), (38,89), (37,100), (30,127), (83,258), (107,378).
Чтобы инициализировать (j, k) в RNG Фибоначчи с запаздываниями, вы должны предварительно заполнить список значениями k. Это можно сделать несколькими способами. Однако наименьшее из начальных значений k обязательно должно быть нечетным. В демонстрации применяется грубый метод копирования значения параметра seed для всех начальных значений k с последующим удалением первой 1000 сгенерированных значений. Если значение параметра seed четное, тогда первое из значений k выставляется равным 11 (произвольному нечетному числу).
Чтобы предотвратить арифметическое переполнение, метод Next использует тип long для вычислений и математическое свойство: (a + b) mod n = [(a mod n) + (b mod n)] mod n.
Заключение
Позвольте мне подчеркнуть, что все четыре RNG, представленные в этой статье, предназначены только для некритичных случаев применения. С учетом этого я прогнал все RNG через набор хорошо известных базовых тестов на степень случайности, и они прошли эти тесты. Но даже при этом коварство RNG всем хорошо известно, и время от времени даже в стандартных RNG обнаруживаются дефекты, иногда лишь спустя годы их использования. Например, в 1960-х годах IBM распространяла реализацию линейного конгруэнтного алгоритма под названием RANDU, которая, как оказалось, обладала невероятно плохими качествами. А в Microsoft Excel 2008 была выявлена ужасно проблемная реализация алгоритма Вичмана-Хилла.
Нынешний фаворит в генерации случайных чисел — алгоритм Фортуна (Fortuna) (названный в честь римской богини удачи). Алгоритм Фортуна был опубликован в 2003 году и основан на математической энтропии плюс сложных шифровальных методах, таких как AES (Advanced Encryption System).
Джеймс Маккафри (Dr. James McCaffrey) — работает на Microsoft Research в Редмонде (штат Вашингтон). Принимал участие в создании нескольких продуктов Microsoft, в том числе Internet Explorer и Bing. С ним можно связаться по адресу jammc@microsoft.com.
Выражаю благодарность за рецензирование статьи экспертам Microsoft Крису Ли (Chris Lee) и Кирку Олинику (Kirk Olynyk).
Источник
Лекция 22.
Генераторы случайных чисел
В основе метода Монте-Карло (см. Лекцию 21. Статистическое моделирование) лежит генерация случайных чисел, которые должны быть равномерно распределены в интервале (0; 1) .
Если генератор выдает числа, смещенные в какую-то часть интервала (одни числа выпадают чаще других), то результат решения задачи, решаемой статистическим методом, может оказаться неверным. Поэтому проблема использования хорошего генератора действительно случайных и действительно равномерно распределенных чисел стоит очень остро.
Математическое ожидание mr и дисперсия Dr такой последовательности, состоящей из n случайных чисел ri , должны быть следующими (если это действительно равномерно распределенные случайные числа в интервале от 0 до 1):
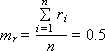
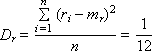
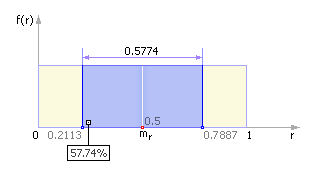
Если пользователю потребуется, чтобы случайное число x находилось в интервале (a; b) , отличном от (0; 1) , нужно воспользоваться формулой x = a + (b a) · r , где r случайное число из интервала (0; 1) . Законность данного преобразования демонстрируется на рис. 22.1 .
| |
| Рис. 22.1. Схема перевода числа из интервала (0; 1) в интервал (a; b) |
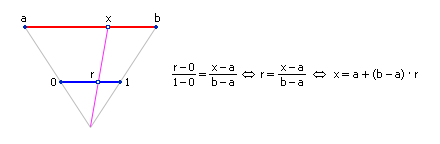
Теперь x случайное число, равномерно распределенное в диапазоне от a до b .
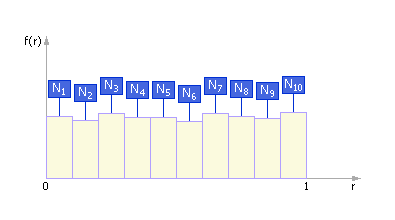
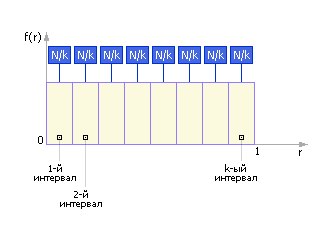
За эталон генератора случайных чисел (ГСЧ) принят такой генератор, который порождает последовательность случайных чисел с равномерным законом распределения в интервале (0; 1) . За одно обращение данный генератор возвращает одно случайное число. Если наблюдать такой ГСЧ достаточно длительное время, то окажется, что, например, в каждый из десяти интервалов (0; 0.1) , (0.1; 0.2) , (0.2; 0.3) , , (0.9; 1) попадет практически одинаковое количество случайных чисел то есть они будут распределены равномерно по всему интервалу (0; 1) . Если изобразить на графике k = 10 интервалов и частоты Ni попаданий в них, то получится экспериментальная кривая плотности распределения случайных чисел (см. рис. 22.2 ).
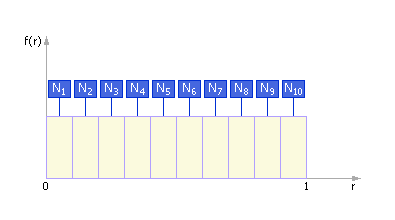
Заметим, что в идеале кривая плотности распределения случайных чисел выглядела бы так, как показано на рис. 22.3 . То есть в идеальном случае в каждый интервал попадает одинаковое число точек: Ni = N/k , где N общее число точек, k количество интервалов, i = 1, , k .
Следует помнить, что генерация произвольного случайного числа состоит из двух этапов:
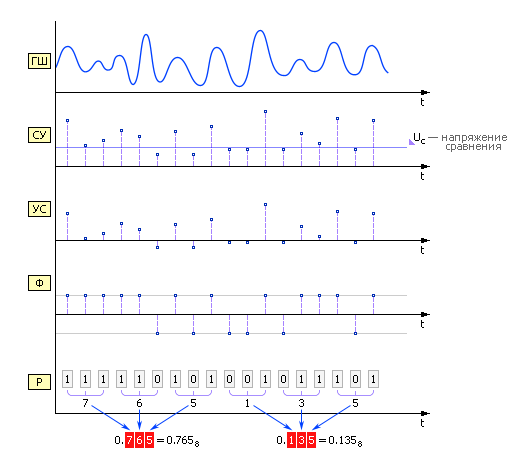
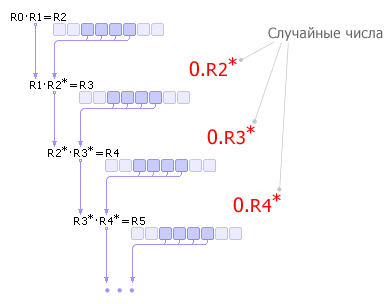
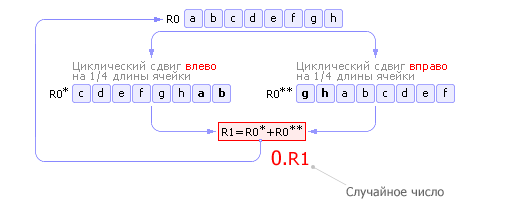
Генераторы случайных чисел по способу получения чисел делятся на: Физические ГСЧПримером физических ГСЧ могут служить: монета («орел» 1, «решка» 0); игральные кости; поделенный на секторы с цифрами барабан со стрелкой; аппаратурный генератор шума (ГШ), в качестве которого используют шумящее тепловое устройство, например, транзистор ( рис. 22.422.5 ).
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||